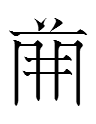
TT2078 'yï 2.28
07.10.6.23:50: HOW MANY HATS? (PART 3)
In part 2, I found that 71 tangraphs were sources of HORNED-HAT in 146 tangraphs. 146 is roughly 71 times 2. Does that mean each source had two derivatives? In fact, most sources (39/71 = 54.9%) had only one derivative:
| Number of derivatives per source | Frequency |
| 1 | 39 |
| 2 | 17 |
| 3 | 9 |
| 4 | 2 |
| 5 | 1 |
| 8 | 2 |
| 11 | 1 |
The most 'popular' source was the surname tangraph
TT2078 'yï 2.28
which was the source of HORNED-HAT in 11 other surname tangraphs:
TT1797 tshyiy 1.36
TT1798 kyụ 1.59
TT1809 korw 1.91
TT1854 gyiiw 1.47
(also used to transcribe Chn 牛 ?*nggiw in Cixiao)
TT1859 'ã 1.24
TT1870 'yiry 1.74
TT1951 la 1.17
TT1963 ?ñ- (pronunciation unknown)
TT1985 Ga 1.17
TT2025 shyïr 1.86
TT2095 swẽ 1.15
(Shi et al. [2000: 57] equated this with Chn 宋; note the HORNED-HAT-like 宀 on top)
Since the above tangraphs have no phonetic features in common, one might conclude that HORNED-HAT was a semantic element meaning SURNAME. One could even go so far as to derive it from Chn 宀 'roof': those under the same roof tend to share the same SURNAME.
TT4940 appears to be a combination of HORNED-HAT atop a phonetic element
TT4979 SAY 'yï 2.28
No Tangraphic Sea analysis for TT4940 has survived, but surely its near-homophony with SAY cannot be coincidental.
The second and third most popular sources were
TT1832 耳 EAR nyu 1.3
(Is HORNED-HAT derived from 门, an abbreviation of 門 'gate', the phonetic of 聞 'hear'? Is this why HORNED-HAT is in
TT1932 mẽ 1.15
the tangraph used to write a place name which sounded like Chn 門? Is TT1932 a combination of Tangutized versions of 门 and 門?)
TT1879 節 JOINT/PERIOD tserw 1.87
(Is HORNED-HAT derived from 竹 'bamboo' in 節? 竹 can be reduced to an element that looks exactly like HORNED-HAT in cursive sinography.)
(The gloss PERIOD is from Grinstead. Gong [1995:77] glossed this as DIVISION-OF-TIME. Nevsky [1960 I: 279] glossed this as сустав 'joint', период вермени 'period of time'. Although its Tangraphic Sea definition does not refer to time at all, it clearly refer to periods of time in the Pearl. Chn 節 means both 'joint' and 'period of time'. Presumably the Tangut borrowed the extended usage of 'joint' for 'period of time' from Chinese.)
which each served as HAT sources for eight tangraphs.
In fourth place with five derivatives was
TT1882 朝 COURT/京 CAPITAL kiẹy 2.53
(The glosses are from Jacques [2007: 155].)
(A loan from Chn 京 'capital'?; cf. its Sino-Japanese reading kei < *?kyẽy, borrowed from pre-Tangut NW Chn and its pre-Tangut Tibetan transcriptions ke and keng)
(Is HORNED-HAT meant to evoke the 亠 of 京?)
(Shi et al. [2000: 287] gloss this as 界 'boundary' which was phonetically similar in Tangut period NW Chn: ?*kyey. Cf. its pre-Tangut Tibetan transcriptions ke and geHi. Also cf. 境 TPNWC ?*kyẽy 'border' [pre-Tangut Tib. transcriptions keng, heng].)
Obviously, there is no semantic similarity between these top four sources (a surname, EAR, JOINT/PERIOD, and COURT/CAPITAL) and it's possible that HORNED-HAT corresponds to several different sinographic elements (宀, 亠, 门, 竹).
If the 146 HATted tangraphs with surviving analyses are representative of all 280 HATted tangraphs (I found a few more since part 1), it is impossible to guess where any given HORNED-HAT came from. The 11 derivatives of the most popular source comprise only 7.5% of the sample. There may be no 'typical' function of HORNED-HAT.
Next: Sources of sources. (And later: derivatives of derivatives.)
07.10.4.23:59: HOW MANY HATS? (PART 2: THE ACRONYM ANALOGY)
For over a decade, I've regarded the standard explanation of tangraphy as implausible. If tangraphs consist of parts of each other, how does one know that part X came from graph XYZ as opposed to graphs ABX, CXD, XEF, etc.?
Tonight, I realized that tangraphs are like acronyms: combinations of elements which are all abbreviations with multiple interpretations: e.g., C can stand for
current in AC, DC
computer in PC
compact in CD
CD and DC look like they could be related terms, but their letters stand for different words (compact disc and direct current). Tangraphic Sea-style analyses for those two acronyms would be:
CD = left of CLIC (compact linear collider) + right of DVD (digital versatile disc)
DC = left of DMA (direct memory access) + right of AC (alternating current)
(Are there more common acronyms with C for compact and D for direct?)
How many HATted tangraphs can HORNED-HAT represent? There's no way to know the total number because the analyses of most tangraphs for rising tone syllables are in the lost rising tone volume of Tangraphic Sea. However, 146 analyses of HATted tangraphs in the survivng volumes of Tangraphic Sea contain 71 different sources of HORNED-HAT: e.g., EAR, EYE, FATHER, HEAR, PERIOD, SEE, etc. Could a writing system thrive with so many possible values for a symbol?
One could argue that the answer is 'yes' because the number of words represented by C in English acronyms is also large. However, acronyms are only a part of the English writing system whereas the combination of abbreviations is supposed to be the essence of tangraphy. Common words such as
TT1832 EAR nyu 1.3 = top of HEAR + bottom of HEAR-ABOUT
TT1850 EYE mey 1.33 = top of SEE + right (sic; why not all?) of UNDERSTAND
are written with combinations of elements.
Note also that the meaning of a tangraph is not quite the sum of its parts. HEAR plus HEAR-ABOUT and SEE plus UNDERSTAND suggest verbs (LISTEN? RECOGNIZE?), but in fact their parts combine to represent the nouns EAR and EYE. Acronyms, on the other hand, are much simpler: C plus D represents a phrase whose words begin with C and D.
Lastly, each part of an acronym represents a word (or part of a word) in a spoken phrase, whereas the components of tangraphs didn't form phrases: e.g.,
myi 1.11 wer 1.77
HEAR HEAR-ABOUT
(Is HEAR-ABOUT borrowed from Tangut period NW Chn 聞 ?*və̃ 'hear'? If it is, why would it have a retroflex vowel absent in Chinese?)
lyi 2.9 mey 1.33
SEE UNDERSTAND
(Since UNDERSTAND is homophonous with EYE, was SEE added to mey 1.33 as a clarifier or extender in speech? Are UNDERSTAND and EYE the same word? If they are, UNDERSTAND must be a derived meaning ['to eye something' > 'to understand it'?] since its probable cognates in Sino-Tibetan mean 'eye': e.g., Japhug rGyalrong tɯ-mñaʁ, Taoping Qiang mi, Written Tibetan mig, Written Burmese myak, and Old Chinese 目 *muk.)
Or did such phrases actually exist as substitutes for nyu 1.3 'ear' and mey 1.33 'eye' in the language game that David Boxenhorn proposed?
(I had forgotten that David had suggested the "Cockney Connection" almost two years ago. My apologies. He had even used the same example of bread < bread and honey, rhyming with money.)
07.10.3.23:45: HOW MANY HATS? (PART 1)
I was running out of time when I wrote "The Cockney Connection", so I gave an estimate of 270 tangraphs with HORNED-HAT based on the following methodology:
- I glanced at all 364 tangraphs in Sofronov's HORNED-HAT section (TT 1772-2135).
- I only considered tangraphs with HORNED-HAT covering all other elements to be HORNED-HAT tangraphs. This excluded tangraphs such as
TT1895 眷屬 FAMILY-DEPENDENTS Gwə 2.25
whose HORNED-HATs only covered their bottom left-hand components.
(Nishida considers HORNED-HAT + ㄇ to be his radical 106 HEAD. The right side of TT1895 doesn't occur by itself but does appear in three tangraphs for WIFE.)
- Sofronov's tangraph index lists 23 tangraphs per column.
- TT1772-2135 were in 16 columns.
- Roughly four columns' worth of tangraphs didn't qualify.
- (16 - 4) * 23 = 276.
Tonight I went through those 364 tangraphs again for a more precise count. This time I included tangraphs whose upper-left hand HORNED-HATs were derived from tangraphs with full HORNED-HATs; e.g.,
=
+
TT1950 畜根 ('livestock root' - a Chn euphemism?) tsyu 1.3 =
all of TT1949 嬰 INFANT ze 1.8 +
all of TT1568 陰根 ('yin root' - a Chn euphemism) kyu 2.3
When no tangraphic analysis is known - e.g., in cases such as
TT1815 (meaning unknown) new 1.43
(baby-related?; TT1814 INFANT and TT1237 瘦 EMACIATED are its clarifiers in Homophones)
TT1822 安居 LIVE-IN-PEACE low 2.47 (why is WORD on the left?)
TT1823 剛正 UPRIGHT low 2.47
TT1935 寬 綽 SPACIOUS zhyïr 1.86
- and when I am confident that the upper-left hand HORNED-HATs are from fully HORNED-HATted tangraphs which are clearly phonetic -
TT1814 INFANT nwu 1.1
TT1821 BROAD low 2.47
TT1934 (syl. of nam) zhyïr 1.86
- I have counted such tangraphs as HORNED-HATted.
Although Nishida distinguishes between HORNED-HAT (his radical 007) and a HORNED-HAT with a left-hand vertical line (his radical 008 EAR), I treated his r008 tangraphs as if they were r007, since the HORNED-HATs of r007 tangraphs are cited as sources of the HORNED-HATS of r008 tangraphs: e.g.,
=
+
TT1832 EAR nyu 1.03 =
top of TT2062 HEAR myi 1.11 +
bottom of TT2487 耳聞 HEAR-ABOUT wer 1.77
This implies that at least some r008 are really r007 plus a separate element. Here's an instance in which that separate element is extracted from r008:
=
+
TT1610 LEAF (Shi et al. 2000: 茶杯 TEACUP) tserw 1.87 (see "A Rare Hand") =
left of TT1875 寬綽 SPACIOUS xyïy 1.42
center of TT1879 節 PERIOD tserw 1.87
The center of PERIOD (see "The Coolest Component") is apparently phonetic in TT1610, though the function of the vertical line (Nishida radical 039 HAND) is unknown. (Is the resemblance between TT1610 and Chn 杯 'cup' coincidental?)
When I included known and probable derivatives of r007 tangraphs plus r008 tangraphs, the total number of HORNED-HAT tangraphs was 278 - quite close to my rough figure of 270.
Subtracting the 27 r008 tangraphs results in a total of 251.
In theory, a HORNED-HAT could come from any one of those 278 (or 251) tangraphs. If HORNED-HAT had a fixed semantic or phonetic value, this wouldn't be so bad.
If I see the tangraphic element WORD, it doesn't matter if I know whether it's from
the right of TT0451 WORD (Gong: LANGUAGE/SPEECH) ngwuu 1.5
the left of TT4597 MOUTH (Gong: LANGUAGE) ngwuu 2.5
the left of TT4633 SAY (Gong also has SPEAK) ngwuu 1.5
because it has the same semantic function in all of them. (But it doesn't seem to be semantic or phonetic in TT1822 安居 LIVE-IN-PEACE above.)
However, the sight of HORNED-HAT tells me nothing about the pronunciation or meaning of a tangraph. When I see an analysis such as
=
TT1879 節 PERIOD tserw 1.87 =
frame of TT1832 EAR nyu 1.03 +
TT5081 嫡 ?PRIMARY-WIFE nyï 1.30
I don't understand why PERIOD and EAR both share the same elements (Nishida's EAR + the mysterious right-hand ヒ). Such elements forced me to consider the Tangut B hypothesis. Although deliberately meaningless elements do exist in sinography - e.g., the arbitrary elements added to distinguish the Sanskrit transcription characters 迦伽佉 from the regular characters 加 and 去 - they are rare.
Some seemingly meaningless elements in sinography were originally meaningful, though they have lost their significance over time: e.g., 車 'carriage' in 輕 'light' (i.e., not heavy), which once meant 'light carriage' (Karlgren 1957: 220; Shuowen defines 輕 as 輕車 'light carriage').
That explanation does not account for the meaningless elements in tangraphy, because the history of tangraphy is so short. If those elements truly have always been meaningless, they must either be arbitrary (and therefore difficult to memorize) or based on a sound system distinct from that of Tangut (A).
Next: How many tangraphs are sources of HORNED-HAT in other tangraphs?
07.10.2.23:59: THE COCKNEY CONNECTION
For over ten years, I've found it difficult to believe that tangraphy works the way most scholars say it does. Take the tangraph from "Speechless", for example:
=
+
+
TT2002 SPEAK (Gong: LANGUAGE/SPEECH) ngwuu 1.5 =
(top of) TT1801 喧說 TALK-LOUDLY chhyiw 1.47 +
(left of) TT3815 WORD gywi 2.10 +
(bottom) right of TT5276 兵器 WEAPON thyiy 1.36
Presumably
the top of SPEAK (HORNED-HAT) was supposed to evoke TT1801 喧說 TALK-LOUDLY, even though there are at least 1000 tangraphs with this element (c. 600 with PERSON on the left, c. 350 with PERSON on the right, and still more with PERSON in the middle).
the bottom left of SPEAK (PERSON) was supposed to evoke TT3815 WORD, even though there are c. ?270 tangraphs with this element and surely the right side of WORD (the semantic element WORD) would have been more semantically appropriate.
the bottom right of SPEAK (ENCLOSURE + ヒ) was supposed to evoke TT5276 WEAPON. Neither WEAPON nor the three other tangraphs with ENCLOSURE + ヒ have any semantic or phonetic relationship to SPEAK.
Can a writing system not only be semantocentric (which would make it unique in the history of writing), but also be based on the principle of the least relevant part being reminiscent of a whole? If English were written tangraphically, speak would be written as TWOPON, a combination of TALK, WORD, and WEAPON. That example is not sufficiently complex enough, since TALK, WORD, and WEAPON would in turn be combinations of other 'anglographs' derived from yet more 'anglographs'.
Yesterday I discovered a living language phenomenon also based on the principle of parts evoking wholes: Cockney rhyming slang (CRS). CRS operates on this principle:
Given a word A:
- find a word B that rhymes with A and occurs in a phrase C B
- substitute C for A
(i.e., let C [a part] evoke C B [a whole], whose last part [B] in turn evokes A)
If tangraphy were explained in such terms:
Given a tangraph ABC
- A evokes a tangraph ADE (rather than other tangraphs containing A)
- B evokes a tangraph FBG (rather than other tangraphs containing B)
- C evokes a tangraph HIC (rather than other tangraphs containing C)
In both systems, the user is expected to mentally supply the missing parts.
Despite the precedent of CRS, I still remain skeptical about the standard explanation of obscure tangraphs.
First, unlike obscure tangraphs, CRS is used to represent only a small number of words, not a large part of the lexicon.
Second, CRS relies on two-stage evocation (part > whole; rhyme > rhyming word), whereas tangraphy allows long chains of evocation (part > whole > parts > wholes ...).
Third, the parts used to evoke wholes in CRS (e.g., bread > bread and honey > money) are not as high-frequency as HORNED-HAT or PERSON.
Nonetheless, I wonder if David Boxenhorn was right when he suggested that tangraphy may have originated in a language game.
07.10.1.23:31: SPEECHLESS
Which is the 'odd man out' among these tangraphs from "Five Languages"?
TT0434 言詞 EXPRESSION ngwu 1.1
TT0451 WORD (Gong: LANGUAGE/SPEECH) ngwuu 1.5
TT2002 SPEAK (Gong: LANGUAGE/SPEECH) ngwuu 1.5
TT4597 MOUTH (Gong: LANGUAGE) ngwuu 2.5
TT4633 SAY (Gong also has SPEAK) ngwuu 1.5
The first contains the tangraphic element MOUTH (Nishida radical 255).
The first, second, and fourth contain the tangraphic element LANGUAGE (Nishida radical 154).
The second, fourth, and fifth contain the tangraphic element WORD (Nishida radical 182, based on the cursive form 讠 of Chn 言 'speech'?).
(The second and fourth are almost mirror images of each other -
- though this is obscured by the use of differently shaped left- and right-hand versions of Nishida radical 182.)
Only the third contains no obvious element having to do with language:
It is tangraphs like TT2002 that fascinate me the most. They contain no obvious semantic or phonetic elements and seem to be completely random combinations of elements. TT2002 looks like
HORNED-HAT (Nishida radical 007; may indicate a verb [Grinstead 1972: 56]) atop
PERSON (Nishida radical 204)
ENCLOSURE (Nishida radical 98)
ヒ ('filler' right-hand element; function unknown)
The Tangraphic Sea analyzed it as
TT2002 SPEAK (Gong: LANGUAGE/SPEECH) ngwuu 1.5 =
(top of) TT1801 喧說 TALK-LOUDLY chhyiw 1.47 +
this also lacks any obvious LANGUAGE elements; its Tangraphic Sea analysis is:
top (HORNED-HAT) from TT2002 SPEAK (Gong: LANGUAGE/SPEECH) ngwuu 1.5 +
bottom left (Nishida radical 223; meaning unknown) from TT1085 HEAR lhyïy 1.42 +
bottom right (bottom half of Nishida radical 246; meaning unknown) from TT2960 ESTABLISH thu 1.1
(left of) TT3815 WORD gywi 2.10 (why this isn't borrowed from Chinese*) +
there's Nishida radical 182 WORD again on the right, but combined with PERSON and a vertical line (why?)
(bottom) right of TT5276 兵器 WEAPON thyiy 1.36 (not in Grinstead or Tangraphic Sea; no analysis available)
looks like MOVEMENT (Nishida radical 049) + a combination not found elsewhere:
METAL (Nishida radical 028) atop
Nishida radical 202 + ENCLOSURE (Nishida radical 98) + ヒ
There are several things I don't understand:
1. Why weren't all five ngwu(u) words written with semantic elements indicating LANGUAGE? Why not make all five transparent semantic compounds? Why make four self-explanatory tangraphs and then create a fifth obscure one? If tangraphy was meant to be deliberately obscure, why not make all tangraphs obscure? If a word is written obscurely, is that somehow significant? Does it mean that a word is part of the ritual language? (No, for some everyday, non-ritual words were written with obscure characters: e.g., TT1790 VEGETABLE below.)
2. Why does TT2002 SPEAK contain PERSON, the left side of
TT3815 WORD gywi 2.10
instead of WORD, its right side?
3. Why does TT2002 SPEAK ngwuu 1.5 contain part of TT5276 兵器 WEAPON thyiy 1.36, which is both semantically and phonetically irrelevant? The combination 干+ヒ also occurs on the (bottom) right of
=
+
TT1062 EGG tew 1.43 =
frame (sic!) of TT1063 遮 ?IMPEDE lyiy 2.33 +
(bottom) left of TT4445 EGG dziã 2.23
=
+
TT1790 菜 VEGETABLE naa 2.19 = (acc. to Precious Rhymes)
all (sic!) of TT3595 CURE/藥 MEDICINE tser 1.77 +
why is PERSON on the left?
neither VEGETABLE nor MEDICINE are verbs, despite the presence of HORNED-HAT
center (sic!) of TT2002 SPEAK ngwuu 1.5
=
+
TT2666 拴 索孔 ?FASTEN-ROPE-HOLE swey 1.33 =
left of TT2727 連縫 ?CONNECT-SEAMGor 2.80
bottom right of TT1344 LOSE lyạ 2.57
(is a hole a void, implying something LOST?)
(ユ +干+ヒ is a common unit; this implies it is derived from 干+ヒ)
These tangraphs have no semantic or phonetic connection to TT2002 SPEAK ngwuu 1.5. So why would anyone write VEGETABLE as MEDICINE-SPEAK?
Next: The Cockney Connection.
*10.2.00:21: I initially wondered if
TT3815 WORD gywi 2.10
could be a borrowing from (pre-)Tangut period northwestern Chinese. TPNWC *ngg- corresponds to Tangut g- (Gong 1981: 722-723). And -ywi would be a reasonable approximation of TPNWC *ü in 語 ?*nggü 'language'.
However, according to Gong (1981: 764), Tangut rhyme 2.10 was used to approximate TPNWC ?*-i (my reconstruction), not ?*-ü. One could object and point out that Gong's examples involve -yi 1.11/2.10, not -ywi 1.11/2.10. Nonetheless, I know of no other cases in which -ywi 1.11/2.10 corresponds to TPNWC *-ü. In Gong's list of Chinese loanwords in Tangut, TPNWC ?*-ü corresponds to
-yu 1.2/2.2/1.3/2.3 (I'll be looking into these rhymes later this week.)
-yuu 1.7/2.6
In Cixiao (Jacques 2007), TPNWC ?*-ü (< earlier ?*-üö like 語) was transcribed with tangraphs ending in
-yu 2.2/1.3/2.3 (TT0563, TT5701, TT0660)
Therefore a Tangut borrowing of 語 TPNWC ?*nggü 'language' should have been gyu(u), not gywi 2.10.
07.9.30.21:25: FIVE LANGUAGES
In Old Chinese, 五 *nga' 'five' and 語 *nga' 'speak' (later 'language') were nearly homophonous. It is therefore not surprising that the sinograph for 語 *nga' contains the phonetic 五 *nga' 'five'.
語 OC *nga' 'speak' is the root of several other OC words (Schuessler 2007: 588):
語 OC *nga-s 'tell'
言 OC *nga-n 'speak; speech, talk'
唁 OC *r-nga-n-s 'to console'
諺 OC *r-nga-n-s 'saying; proverb'
(If *nga' is the root, why is there no glottal stop in the above reconstructions?*)
In Tangut, 'five' was also nearly homophonous with five words dealing with speech:
TT3119 FIVE ngwə 1.27
TT0434 言詞 EXPRESSION ngwu 1.1
TT0451 WORD (Gong: LANGUAGE/SPEECH) ngwuu 1.5
TT2002 SPEAK (Gong: LANGUAGE/SPEECH) ngwuu 1.5
TT4597 MOUTH (Gong: LANGUAGE) ngwuu 2.5
TT4633 SAY (Gong also has SPEAK) ngwuu 1.5
Is it a coincidence that 'five' and words for speech were near-homophones beginning with ng- in both languages?
It is tempting to link the Tangut words to OC *nga' 'five' and OC *nga' 'speak'. However, I have already explained why I expected the Tangut cognate of OC *nga' 'speak' to be ngya 1.19 in Gong's reconstruction, not ngwu 1.1 (or ngwuu 1.5 or 2.5). Moreover, I expected the Tangut cognate of OC *nga' 'five' to be nga 1.17, not ngwə 1.27.
Note that I use the past tense of expect. I now realize that the situation is far more complex than I thought.
I already knew that pre-Tangut *a raised and fronted to various degrees under unknown circumstances. Other languages preserve lower vowels: e.g. (from Jacques 2003: 7):
'moon': TT lhyị 2.60:
gDong-brgyad rGyalrong sla
Written Tibetan zla-ba
夕 OC *slak 'evening' (but Schuessler 2007: 522 reconstructed 夕 as *s-yak, which would not be cognate)
'nose': TT nyii 2.12
gDong-brgyad rGyalrong tU shna
WT rna
'eat': TT0524 dzyi 1.10, TT0479 dzyo 1.51 (< *dzyi-o)
gDong-brgyad rGyalrong kë ndza
WT za-ba
'horse': TT5233 ryiry 1.74 (with raising), TT4789 ryar 2.74 (without raising):
gDong-brgyad rGyalrong mbro (< Proto-rGyalrong *-ang)
Old Tibetan rmang
馬 OC *mra'
'sheep': TT1512 'yiy 2.33
gDong-brgyad rGyalrong qa zho (< Proto-rGyalrong *yang)
WT g-yang-dkar
羊 OC *lang or *yang (I favor the latter on Chinese-internal grounds)
'five': TT3119 FIVE ngwə 1.27
gDong-brgyad rGyalrong kU mngu
WT lnga
五 OC *nga' 'five'
(Thanks to Guillaume Jacques for pointing out to me that Tangut 'five' could not be a loan; see below.)
'cow': TT5432 ngwe 2.7
gDong-brgyad rGyalrong nU nga
WT ba (< ?*ngba < ?*ngwa, suggested by Schuessler [2007: 403])
牛 OC *ngwə
What I did not know was that *a raised and backed in Qiangic languages (Tangut, rGyalrong, and Qiang). Guillaume Jacques kindly drew my attention to the fact that gDong-brgyad rGyalrong kU mngu 'five' has -u (cf. WT lnga, Written Burmese ngaaḥ, and OC *nga'). Taoping and Mawo Qiang both have ʁuɑ (ignoring Taoping tone). Tangut ngwə 1.27 with a mid vowel looks like a compromise between rGyalrong with a high vowel and Qiang with a low vowel:
rG kU mngu < T ngwə > Q ʁuɑ
The source of the labiality of these words (rG u, T -w-, Q -u-) is unknown.
Guillaume also noted these two cognate sets (I have added the Qiang, Pumi, Written Burmese, and OC forms):
'ear': TT1832 nyu 1.3
gDong-brgyad rGyalrong tU rna
Qiang (three different vowels!):
Taoping ñikie
Mawo nəku
Yadu ñuku̥
WT rna
WB naaḥ
耳 OC *nəng' ~ *nə' 'ear'
(Schuessler [2007: 226] thought that there was a single Tibeto-Burman root for 'nose' and 'ear': cf. the semantics of 聞 Md wen 'smell/hear'.)
'meat': TT1514 shyu 2.2
(also cf. TT1582 MEAT chhyi 1.10 [Gong in Matisoff (2003:171-172)] and possibly TT2289 DRIED-MEAT swu 1.1)
Pumi Dayang shchï (Matisoff 2003: 169, showing a third Qiangic reflex of earlier *a)
WT sha
WB saaḥ
(No OC cognate, contra Benedict's proposals of 身 'body' and 獸 'beast', which I reconstruct as OC *hlin and OC*-us [initial uncertain; Baxter proposed *st-] with non-a vowels.)
Two or even three Tangut words for 'ox' may also contain a raised and backed *a:
TT0190 byu 1.2
TT2165 byu 2.3
(and TT0183 CYCLICAL-SIGN-OX myuu 2.6?)
cf. WT ba 'ox' and Md [ü] < OC *a: e.g., 語 Md yu [yü] < OC *nga' 'speak'.
I have found two apparent Tangut doublets with u (raised and backed?) and a (original?):
'box': TT0917 khu 2.1 : TT0908 kha (rhyme unknown)
'infant': TT1814 nwu 1.1 : TT3599 na 1.17
So contrary to what I wrote yesterday, it's possible that the various Tangut ngwu(u) words dealing with language were cognate to 語 OC *nga' 'speak' after all.
Schuessler (2007: 588) links the OC word to WT ngag 'speech'.
I am not sure which (if any) of the five ngwu(u) words is the base of the others. I can, however, say that we can see tonal and rhyme alternation:
1.1 ~ 1.5 ~ 2.5
Gong interprets the difference between 1.1/2.1 and 1.5/2.5 in terms of length (short vs. long), but other interpretations are possible: e.g.,
Nishida: -u : -ʊ
Sofronov: -u : -ũ
Shi et al.: -(i)u : -(u)o
Li Fanwen: -u / -ü : -ʊ
Arakawa: -u : -u' (= [uɦ]?)
Each interpretation has morphological implications: e.g., Sofronov's ngwũ 1.5/2.5 suggests a nasal suffix added to a non-nasal base (presumably ngwu 1.1).
In any case, there were two independent vowel-raising trends in Qiangic and in Sinitic. There is some consensus on the conditioning factors for the multiple reflexes of OC *a:
After emphatics:
OC*Ca > MC *Co
OC *Cra, rCa > MC *Cæ
After nonemphatics: reflexes vary depending on the point of articulation of the initial:
OC *Ka, *Ta > MC *Kïə, *Tïə
OC *Pa > MC *Puə
- but the conditioning factors for raising (with fronting or backing) of *a in Qiangic remain unclear. Until these factors come to light, it is difficult to distinguish between genuine cognates and lookalikes which happen to share similar consonants.
Next: SPEECHless.
*I suspect that some, if not all, instances of final glottal stop in OC are automatic codas for syllables ending in short vowels. A suffix added to a short-vowel CV root filled the coda position, so no glottal stop was needed:
*/nga/ > *[nga']
*/nga-s/ > *[ngas] (not *nga's)
*/nga-n/ > *[ngan] (not *nga'n)
*/r-nga-n-s/ > *[rngans] (not *rnga'ns)
OC syllables ending in long vowels did not require final glottal stops: e.g., 吾 *[ngaa] 'I', phonetic in 語 *[nga'] 'speak'. I write such long vowels as if they were short but without a final glottal stop: 吾*nga = *[ngaa] (not *[nga]).
Schuessler (2007: 75) related some OC *-n' words to Tibetan words without codas:
犬 OC *khwin' : Written Tibetan khyi 'dog' (< ?*ki)
臇 OC *tson' : Written Tibetan tsho-ba 'be fat'
卵 OC *ron' 'egg' : West Tibetan sro-ma 'nit'
(Starostin also listed a rGyalrong [variety unspecified] Ja-ru 'louse egg'; other possible open-syllable cognates here; why did he reconstruct Proto-Sino-Tibetan *ruuH?**)
These OC words may originate from roots with original glottal stops plus *-n: *khwi'-, *tso'-, *ro'-:
*CV'-n > *CVn' (glottal stop and -n metathesize)
Could cases of nasal-glottal stop clusters alternating with long vowels and zero codas such as
耎 OC *non' 'soft, weak' : 懦 OC *no [noo] 'weak, timid'
碗 OC *'on' 'bowl' : 甌 OC *'o ['oo] 'bowl'
罔 OC *mang' 'deceive' : 誣 OC *ma [maa] 'deceive'
往 OC *wang' 'go' : 于 OC *wa [waa] 'go'
枉 OC *'wang' 'bent, crooked' : 迂紆 OC *'wa ['waa] 'to bend, deflect'
reflect the loss of original glottal stop after long vowels?
*CVV' > *CVV
*CVV'-N > *CVN' (glottal stop and nasal metathesize)
And are
耳 OC *nəng' ~ *nə' 'ear'
等 OC *təng' ~ *tə' 'classify'
cases of short-vowel roots with an original glottal stop:
*CV' > *CV' (merging with original *CV)
*CV'-N > *CVN' (glottal stop and nasal metathesize)
I have yet to fully work out the implications of my hypotheses concerning vowel length and glottal stops in OC for word families and phonetic series.
**Starostin's final *-H in his Proto-Sino-Tibetan *ruuH seems to have left no trace in any of the forms that he lists. Presumably he would have analyzed Miji rinh 'egg' as ri-n-h, not rih-n with metathesis. This PST *H corresponds to his Proto-North Caucasian *s:
PST *ruuH 'nit, egg' : PNC *sarasV 'nit; embryo (of an egg)'
PST *taanH 'mat': 'PNC *ṭams_V 'carpet'
PST *nǝ̆wH 'younger sibling' : PNC *nŭsA 'daughter-in-law' (poor semantic fit -A)
The *H in the latter two forms also corresponds to nothing in the listed ST forms.
If the North Caucasian family existed, and if Sino-Tibetan existed and were related to North Caucasian, then it might be possible that a Proto-Sino-Caucasian *-s- lenited to *-H (is this voiced in Starostin's notation?) before disappearing in the extant Sino-Tibetan languages. But that's two ifs too many, and even if that scenario were true, where would Proto-Sino-Tibetan *-s come from?