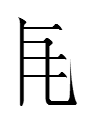
TT1338 2505 0099
lyï 1.29 zhyịy 2.54 Giẹ 1.59
07.3.10.23:50: CONSONANTAL CONSENSUS: THE TIBETAN TEST
How do we know that chapter I of Homophones contained labial-initial syllables, chapter II contained labiodental-initial syllables, etc.? In most cases, we could guess the chapters' content by translating their titles which are largely calques of Chinese phonological terms except for Chapter IX:
TT1338 2505 0099
lyï 1.29 zhyịy 2.54 Giẹ 1.59
But we cannot assume that the Tangut used Chinese terminology in exactly the same way. Thus we must find another source of data to clarify Homophones' scheme of classification.
The table below organizes the initials in the Tibetan transcriptions of Tangut by the Homophones chapters of their tangraphs.
By 'initial' I mean 'consonant closest to the vowel with or without an intervening glide': e.g., the 'initial' of TT1267 STRONG rkyiH (Nevsky 1926 #9) is k.
In some cases, I have treated clusters as single consonants: e.g., ldth.
Clusters that do not occur in Written Tibetan are in red. These un-Tibetan letter sequences presumably represented Tangut sounds absent from Tibetan.
Consonants found in all reconstructions known to me are in bold. All of the consensus consonants can be found in the table, so they all pass the 'Tibetan test'. (I treat the unaspirated voiced stop and affricate series in the table as the equivalents of (b), etc. in "Consonantal Consensus".)
There is no guarantee that each 'slot' in the table represents a distinct phoneme in any Tangut dialect: e.g., Hph, Hb, Hbh could all have been attempts to write a single Tangut phoneme /mbh/.
| Homophones chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| stops and affricates | p** | t | k | ts | ch | ' | |||
| ph | th | kh | tsh | chh | th, ldth | ||||
| b | b | d | g | dz | j | g | ld | ||
| bh | dh | gh | gh | ||||||
| stops
and affricates with preceding H- (a homorganic nasal?: e.g., Hts = [nts]?) | Hts | ||||||||
| Hph | Hth | ||||||||
| Hb | Hd | Hg | Hdz | Hj | Hg | ||||
| Hbh | |||||||||
| nasals | m | n, ñ, ng? | ng, n | ||||||
| hrn | hñ | ||||||||
| fricatives | s | sh | h | ||||||
| Hs | |||||||||
| z | z | ||||||||
| Hz | |||||||||
| zl | |||||||||
| zh | |||||||||
| H | |||||||||
| sonorants | wh | lh | |||||||
| w | w | l | |||||||
| ww | yy | ||||||||
| yw | y | y | r | ||||||
| Hr |
(07.3.18.3:44: See Nishida [1964: 42] for examples of Hs- and Hz-.)
The contents of Chapters I, III, V, VI, and VII are straightforward
I: labials
III: dentals
V: velars
VI: alveolars
VII: palatals
with a few exceptions:
- Palatal ñ in III (dentals) probably represented a cluster [n] + [y] or [i] rather than a palatal [ñ]. Written Tibetan has a letter ñ but has no letter sequence n + y.
- Velarng in III (dentals) is probably a mistake, unless it represents the fusion of a velar consonant (prefix?) with a dental consonant: kn- > ngn- > ng-?
- Conversely, dental n in V (velars) is probably a mistake.
- Why isn't zh in VII (palatals)?
- Why is z in both VI (alveolars) and - of all places - IX (liquids)? No one has reconstructed z in VI, though I have considered the possibility. (And if [z] is in VI, then the z in IX must stand for something else.)
I intend to investigate the remaning four chapters in future posts.
I tentatively assume that all the Tibetan transcriptions for Chapter II initials represent a single phoneme which may have been [w] or [v] (or a labiodental glide [V]) depending on dialect (or speaker?). See part 9 of "Lip Sounds Light". However, Nishida, Sofronov, and Arakawa reconstruct both w and v. If they are correct,
- w- and v-tangraphs should not have overlapping fanqie initial spellers
- w-tangraphs should not be transcribed in Tibetan with anything but simple w
- w-tangraphs should not be used to transcribe Sanskrit v-syllables
except in cases when no similar v-syllable exists in Tangut
Whether this is the case or not remains to be seen.
Would Homophones really have a single chapter (IV) devoted to hñ, which looks like it should go into the palatal chapter? I would presume not.
The Chinese evidence (Nishida 1964: 98) points to at least one more initial which may have been ñj or j (and why wouldn't that initial be in chapter VII?).
Nishida and Arakawa also proposed voiceless unaspirated and aspirated initials in this chapter, but I am unaware of any basis for this.
It looks as if chapter VIII contained at least five initials:
1. a glottal stop (or a zero initial)
2. a voiceless velar or glottal fricative (x or h)
3. a voiced velar or glottal fricative (G or H)
the point of articulation may have varied by speaker or dialect
4. a w-like initial
5. a y-like initial
The inclusion of nonvelar and nonglottal w- and y-type initials in VIII may reflect Chinese influence for reasons I may explain in a future post.
Chinese phonological tradition may also account for the inclusion of z-type initials in IX which otherwise consists of liquids.
Next: Six vowel letters for 105 rhymes!?
*WIND (surname) SOUND often appears in the literature as 流風音 'flowing wind sounds' though Grinstead (1972), Li (1986: 474), and Shi et al. (2000) did not gloss TT2505 as FLOW. Grinstead did not gloss it and the latter two glossed it as a surname.
Li (1986: 431) apparently regarded TT1338 and TT2505 as Tangut equivalents of the Chinese phonological terms 來 and 日 for the Middle Chinese initials transcribed in Tibetan as l- and zh-. TT1338 and TT2505 were explictly used to represent those Chinese initials in the 五聲切韻 Five Tones Cut Rhymes rhyme table.
**The only Tibetan transcription with p- known to me is pu (Nishida 1964: 76). That seems to be a rather shaky basis for reconstructing p- in Tangut. If there was no p-, we might expect an f- instead (cf. Arabic and Japanese which both developed labial fricatives from earlier *p-).
However, the absence of ph- in the Tibetan transcriptions for chapter II (labiodental) tangraphs and the rarity of f- in the Chinese transcriptions suggests that Tangut may not have had an f-***.
More importantly, the use of p-sinographs in the Chinese transcriptions indicates that Tangut did indeed have a p-.
The use of tangraphs to represent Sanskrit p-syllables does not by itself prove that Tangut had p-, since the Tangut could have used tangraphs for f- or b-syllables to approximate foreign p-syllables.
***07.3.11.00:39: I suspect Chinese f- was an attempt to write Tangut [v]. I know of only two instances of f-sinographs transcribing Tangut:
口縛 for TT3352 FLOWER 1.64 (Pearl 062, 133-136, 211, 219, 331, 333)
transcribed in Tibetan as d-waH
reconstructed by Nishida as fạ
reconstructed by Arakawa as faak
口縛 for TT5147 FLOUR 1.82 (Pearl 332)
reconstructed by Nishida as far
The diacritic in 口縛 indicated that it was to be read in some abnormal fashion. I suspect the 'abnormality' was voicing: [v] or [V] instead of [f].
Kwanten (1982: 57) lists a third instance:
豶 for TT2585 GET-DIRTY 1.65
reconstructed by Nishida as vỊ
but I cannot find this in the Pearl after searching the entire text four times.
07.3.9.20:52: CONSONANTAL CONSENSUS
In recent posts, I've been referring to the initial classes of Homophones without explaining what they stand for, beyond giving hints in capital letters: e.g., "P" for chapter I. It's about time that I outline the system.
The trouble is that there is no agreement on exactly how many initial consonants Tangut had, or even how many classes of initial consonants it had. In some cases, it seems as if the only thing everyone can agree on is that tangraph X appears in chapter Y of Homophones. The reality is not that bad, as there is a 'lowest common denominator' (LCD) consonant system shared by all reconstructions I know of. The table below draws upon Li Fanwen's (1986: 126-127) comparison of reconstructions, Gong's reconstruction in Li Fanwen (1997), and Arakawa's reconstruction as described by Kotaka.
| Homophones chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| My archetype symbol | P | V | T | T | K | TS | CH | ' | L |
| stops and affricates | p | ? | t | ? | k | ts | (ch) | ? | |
| ph | th | kh | tsh | (chh) | |||||
| (b) | (d) | (dz) | (j) | ||||||
| nasals | m | n | ng | ||||||
| fricatives | s | (sh) | |||||||
| (z) | |||||||||
| sonorants | l | ||||||||
| r |
This LCD inventory could belong to a generic Chinese-type language.
There is no consensus about the consonants in chapters II, IV, and VIII.
The absence of parentheses indicates a consonant reconstructed by everyone: e.g., nobody has proposed that Tangut lacked p.
The presence of parentheses indicates a consonant reconstructed in two or more ways by different scholars:
| Nishida | Sofronov | Li Xinkui | Huang | Li Fanwen | Gong | Arakawa | Me | |
| (b) | mb | mb | bh and mb | mb | b | b | b | (m)b(h) |
| (d) | nd | nd | dh and nd | nd | d | d | d | (n)d(h) |
| (dz) | ndz | ndz | dzh | nts | dz | dz | dz | (n)dz(h) |
| (ch) | ch | ch | Ch | ch | ch | ch | ch | ch |
| (chh) | chh | chh | Chh | chh | chh | chh | chh | chh |
| (j) | ñj | nj | Jh | ñch | j | j | j | (ñ)j(h) |
| (sh) | sh | sh | Sh | sh | sh | sh | sh | sh |
| (z) | Rz | zh | z | rz | z | z | z | z |
The symbols within parentheses represent common denominators whenever possible: e.g.,
(b) indicates that everyone reconstructs something with b in it
(dz) indicates that nearly everyone reconstructs something with dz in it
The disagreements in the table above can be summed up as follows:
1. Tangut had at least three types of obstruents:
voiceless unaspirated: p, t, ts, ch, k
voiceless aspirated: ph, th, tsh, chh, kh
voiced: (b), (d), (dz), (j); all but Sofronov also reconstruct (g)
Scholars disagree on whether the voiced series had any other qualities:
- aspiration: bh?
- prenasalization: mb?
Li Xinkui posited separate voiced aspirated and prenasalized voiced series.
I am agnostic about aspiration and prenasalization. Perhaps different Tangut dialects had different voiced series.
- devoicing after prenasalization: Huang's nts and ñch (not ndz and ñj)
though he reconstructed mb, nd, ngg (not mp, nt, ngk)
2. Tangut had fricatives and affricates which were neither alveolar nor velar.
Most reconstructed these as palatals (IPA [tɕ tɕh (n/ɲ)dʑ ɕ]).
Nishida (and Arakawa, it seems) reconstructed these as postalveolars (IPA [tʃ tʃh ɲdʒ ʃ]), though I do not distinguish between postalveolars and palatals in my notation: both are ch chh j sh.
Li Xinkui reconstructed these as retroflexes (IPA [tʂ tʂh dʐ ʂ]) which I indicate with capital letters: Ch, Chh, J, Sh.
3. Tangut had a z-like initial which was classified alongside l and r in Homophones Chapter IX (but not in Chapter VI alongside s or in Chapter VII alongside sh - why?)
Most scholars reconstructed two z-like initials, but all reconstructed at least one.
Nishida's Rz is a voiced uvular fricative (IPA [ʁ]) followed by z.
Huang's rz is a retroflex r (IPA [ɽ]) followed by z.
One scholar's z-like initial does not necessarily correspond to another's: e.g., Sofronov's zh can correspond to Gong's
zh (not in the table; TT0005, TT0007)
or, in one case, even Gong's
lh (not in the table; TT2295)
as well as Gong's z (TT0006).
Next: Can the consonantal consensus stand up to the Tibetan test?
07.3.8.23:56: THE ORIGIN OF ORIGIN (PART 2)
Before I look at the left half of
TT4484 ORIGIN mər 2.76
I want to demonstrate how sinographic elements work for comparison. There is no sinographic element corresponding to TRIBE on the right of ORIGIN, so I'll have to go back to
TT5000 MASTER lhyi 2.10?
to find a Tangut element which has a Chinese counterpart.
In "Origin of the MASTER", I found that the left-hand element of MASTER
TT4990 SKIN jyï 1.30
appeared in tangraphs with meanings that had nothing to do with SKIN and readings that were nothing like jyï 1.30: i.e., tangraphs in which SKIN had no apparent semantic or phonetic function. But surely it was in those characters for a reason.
For comparison, Chinese 皮 'skin' is almost always clearly phonetic or semantic. It is phonetic in the following sinographs that are typeable using Windows XP's Traditional Chinese input method:
| final | tone \ initial | b- | p- |
| -ei | 1 | ||
| 2 | |||
| 3 | |||
| 4 | bei4 被紴 | pei4 帔 | |
| -i | 1 | pi1 披翍被鈹怶旇狓秛耚鮍 | |
| 2 | pi2 皮疲鈹陂 | ||
| 3 | bi3 彼佊柀 | ||
| 4 | bi4 詖 | ||
| -o | 1 | bo1 波玻啵菠岥碆 | po1 波坡翍陂 |
| 2 | po2 婆嘙蔢 | ||
| 3 | bo3 跛簸蚾 | po3 頗箥駊 | |
| 4 | bo4 蔢 | po4 破 |
(All readings are in Mandarin. Sinographs with multiple readings are listed more than once.)
皮 'skin' has no tonal correlation, but it always occurs as a phonetic in sinographs pronounced with labial stop initials and the rhymes -(e)i and -o. In Old Chinese (OC), all the 皮 'skin' graphs ended in -ay (with or without different final consonants), but different initials led to different vocalism from Late Old Chinese (LOC) onward: e.g.,
non-emphatic initial: 彼 OC *pay' > LOC pïay' > Middle Chinese pïe' > Md bi3
non-emphatic initial: 被 OC *bay's > LOC bïayh > Middle Chinese bïeh > Md bei4
(It's not clear to me why Md has two rhymes -i and -ei corresponding to Middle Chinese -ïe. The earlier final consonants led to different Mandarin tones.)
emphatic initial: 波 OC *pay > LOC pay > Middle Chinese pa > Md bo1
I found 皮 'skin' as a semantic element in these seven sinographs in 民衆書林 Minjung Seorim's Essence Chinese-Korean Dictionary 3rd ed. (2001; 3339 pgs.):
皴 cun1 'wrinkle(d)'
夋 jun1 is phonetic
皸 jun1 'chapped (i.e., skin)'
軍 jun1 is phonetic
皰 pao1 'pimple'
包 bao1 is phonetic
皻 zha1 'red blotch on skin'
且 qie3 is phonetic
皽 zhan3 'dead skin cells'
亶 dan3 is phonetic
皺 zhou4 'wrinkled'
芻 chu2 is phonetic
赤+ 皮 (not in my font; see it here) nan3 'blushing': 赤 chi4 'red' is semantic
graphic variant of non-皮 character 赧
phonetic of 赧 is nian3 'soften skin' (not in my font; see it here)
which looks like 尸 shi1 'corpse' atop 叉 cha1 'fork'
nian3 'soften skin' has a variant (not in font; see it here)
< 皮 pi2 'skin' + phonetic 需 xu1 'need' < Old Chinese *sno
皮 'skin' has no function in this sinograph because it is a substitute for a similar-looking element which is in turn a substitute for yet another similar-looking element!
皷 gu3 'drum': graphic variant of non-皮 character 鼓
鼓 < 壴 zhu4 'musical instrument for display' + 支 zhi1 'branch'
支 zhi1 'branch' (drumstick?) replaced 攴 pu1 'strike'
皷/ 鼓 has 31 other variants!
Out of 50 sinographs (counting graphs with two readings twice and excluding the obscure 'skin' + 'need' graph), 皮 'skin' is
phonetic in 42 (84%)
semantic in 7 (14%)
nonfunctional in 1 (2%)
and one could argue that 皮 'skin' refers to the skin of a 皷 drum
though a 皷 drum is still less 'dermal' than 皴 'wrinkled', etc.
If these 皮 'skin'-graphs were put into Homophones, nearly all would be in chapter I:
| Chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| Initial type | P | V | T | T | K | TS | CH | ' | L |
| Tangraphs | 43 | 0 | 1 | 3 | 1 | 1 | 1 | 0 | 0 |
| Percentage | 86% | 0% | 2% | 6% | 2% | 2% | 2% | 0% | 0% |
Compare the distribution of 皮 'skin'-graphs with the distribution of the 87 SKIN graphs in Homophones from this post (all 66 SKIN-left graphs + 16 sample SKIN-right graphs + 5 sample SKIN-middle graphs):
| Chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| Initial type | P | V | T | T | K | TS | CH | ' | L |
| Tangraphs | 10 | 10 | 7 | 0 | 17 | 7 | 9 | 9 | 18 |
| Percentage (out of total of 87) | 11.5% | 11.5% | 8% | 0% | 19.5% | 8% | 10.3% | 10.3% | 20.7% |
| All tangraphs in each chapter | 690 | 248 | 869 | 20 | 911 | 648 | 613 | 514 | 1038+** |
| Percentage of all tangraphs in each chapter (out of total of 5551) | 12.4% | 4.4% | 15.7% | 0.4% | 16.4% | 11.7% | 11% | 9.2% | 18.7% |
(Chapter IV tangraphs are extremely rare.)
The probablility of a SKIN-graph having a certain initial type is usually very close to the probability of any random tangraph having a certain initial type. (SKIN has more chapter II and fewer chapter III tangraphs than expected, but these figures might change if the sample is enlarged.)
SKIN-graphs can also occur in both Tangut tones with rhymes containing
- all seven Tangut vowels
- short and long vowels
- lax (plain), tense (underdotted), and retroflex vowels
- the medial and final glides -w(-), -y(-)
That might as well be a short description of the Tangut final system!
And SKIN has no semantic function most of the time.
The situation with the left side of MASTER (그+ㄇ) is even worse. Unlike SKIN, it does not occur as an independent tangraph, and it has no apparent semantic value. But like SKIN, it also has no single phonetic value and can occur with all sorts of rhymes. See the four charts below.
그+ㄇ in 'pure' left-hand position (no components above it):
| Tangut Telecode | Gloss | Gong's reconstruction | Rhyme | Homophones chapter |
| 4470 | SOURCE | ka | 2.14 | V |
| 4471 | HURRIED | bow | 2.47 | I |
| 4472 | GAME/PLAY | 'u | 2.1 | VIII |
| 4473 | TORTOISE/FROG? | piẹ | 1.66 | I |
| 4474 | A-LITTLE | zyịy | 1.61 | IX |
| 4475 | CROSS | dzyịy | 1.61 | VI |
| 4476 | (a place name) | gyaa | 2.21 | V |
| 4477 | PILLOW | wọ (should this be 'wọ?) | 1.70 | VIII |
| 4478 | HOW | lyọ | 2.64 | IX |
| 4479 | BLACK | nyaa | 1.21 | III |
| 4480 | DIRTY | lwo | 1.49 | IX |
| 4481 | AS-IF | la | 2.14 | IX |
| 4482 | COLLECT | shioo | 1.53 | VII |
| 4483 | COLLECT/DESKTOP | 'yiw | 2.40 | VIII |
| 4484 | ORIGIN (the topic of this post) | mər | 2.76 | I |
| 4485 | COLLECT | shiee | 1.13 | VII |
| 4486 | THRESHING-FLOOR | 'wi | 2.10 | VIII |
| 4487 | ROUND/GARDEN | khwe | ? | V |
| 4488 | FLOWER-GARDEN | khwa | 1.17 | V |
| 4489 | TEN | Gạ | 2.56 | VIII |
| 4490 | TEN-FEET | lhyoor | 1.94 | IX |
| 4491 | (a surname) | 'yiw | 2.4- | VIII |
| 4492 | (measure of weight) | lyïï | 1.32 | IX |
그+ ㄇ in 'pure' center position (no components above it):
| Tangut Telecode | Gloss | Gong's reconstruction | Rhyme | Homophones chapter |
| ? | HIGH | ? | ? | ? |
| 0363 | 悶 DEPRESSED | khwə | 1.27 | V |
| 0364 | 暈 HALO | Gow | 1.54 | VIII |
| 0447 | 令 ORDER? | phyi | 1.11 | I |
| 0542 | GIVE-MEDICINE | tyị | 1.67 | III |
| 0649 | (a surname) | Gu | 2.4 | VIII |
| 1111 | 弓 腰 STOOP-OVER | gyow | 2.49 | V |
| 1453 | DISPERSE | sã | 1.24 | VI |
| 1600 | WEALTH | jyi | ? | VII |
| 1601 | PROPERTY | kyụ | 1.59 | VI |
| 2769 | SCROLL | ? | ? | (not in Homophones) |
| 2770 | SEND | shiə | 1.28 | VII |
| 3094 | QUICKLY | xya | 1.19 | VIII |
| 3127 | RUBBISH | me | 2.7 | I |
| 3187 | DESTROY | kyịy | 1.61 | V |
| 3331 | (second half of 皇上 'your majesty') | Gu | 2.4 | VIII |
| 3332 | (syllable of name) | Ga | 2.56 | VIII |
| 3817 | QUICK | lyị | 2.60 | IX |
| 3819 | DISCRIMINATE | sywiy | 1.36 | VI |
| 3821 | 過 PASS (loanword from Chinese) | kwa | 1.17 | V |
| 3822 | DESTROY | phia | 1.18 | I |
| 3823 | DARKNESS | kow | 1.54 | V |
| 4116 | 常 病 OFTEN ILL | dyï | 1.30 | III |
| 4117 | 邑 VILLAGE | dyï | 1.30 | III |
| 4264 | 昔 日 FORMER DAYS | no | 2.42 | III |
| 4265 | 寒 冷 FRIGID | lyïy | 2.37 | IX |
| 4266 | ? | ? | ? | IX |
| 4268 | 上 TOP/雜 VARIOUS | ? | ? | VII |
| 4269 | ABYSS | nya | 1.21 | II |
| 4645 | HONOR | pyụ | 1.59 | I |
| 4646 | TOUCH-ON | sa | 2.14 | VI |
| 4647 | 議 論 DEBATE | sa | 2.14 | VI |
| 5042 | (verbal prefix) | ryər | 2.77 | IX |
| 5105 | (second half of 不識 'ignorant') | khwụ | 2.51 | V |
| 5365 | DOG | na | 1.17 | II |
| 5449 | APPEARANCE | ywïr | 1.86 | VIII |
| 5536 | OVERTURNED | chhyu | 2.6 | VII |
| 5537 | INFORM | wyi | 2.9 | II |
| 5538 | PLAN | chyïy | 1.42 | VII |
| 5539 | INTELLECT | phyi | 1.11 | I |
| 5733 | SCENT | lew | 2.38 | IX |
| 5739 | CROW | ley (should be liey?; -ey is 1.33) | 1.60 | IX |
| 5740 | 亂 DISORDER | chyo | 1.51 | VII |
| 5800 | (kind of insect) | pyə̣y | 2.65 | I |
그+ ㄇ in 'pure' right position (no components above it):
| Tangut Telecode | Gloss | Gong's reconstruction | Rhyme | Homophones chapter |
| 1523 | WEST | lyi | ? | IX |
| 1702 | 莢 POD | ka | 2.17 | V |
| 2236 | DETERMINATION | kyur | 2.70 | V |
| 2834 | SAME | thwuu | 1.5 | III |
| 3922 | PLAN | lyïy | 2.37 | IX |
| 4231 | NIPPLE | thwu | 2.1 | III |
| 5062 | 騙 術 RUSE | dzyi | 1.10 | VI |
| 5738 | 湧 GUSH | gywi | 2.10 | V |
Distribution of all 'pure' left/center/right-그+ㄇ graphs occurring in Homophones:
| Chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| Initial type | P | V | T | T | K | TS | CH | ' | L |
| Tangraphs | 9 | 1 | 9 | 0 | 14 | 6 | 7 | 12 | 14 |
| Percentage (out of total of 72) | 12.5% | 1.4% | 12.5% | 0% | 19.4% | 8.3% | 9.7% | 16.7% | 19.4% |
| All tangraphs in each chapter | 690 | 248 | 869 | 20 | 911 | 648 | 613 | 514 | 1038+** |
| Percentage of all tangraphs in each chapter (out of total of 5551) | 12.4% | 4.4% | 15.7% | 0.4% | 16.4% | 11.7% | 11% | 9.2% | 18.7% |
Apart from the low number of chapter II graphs and the large number of chapter VIII graphs, the distribution might as well be random.
I propose that 그+ㄇ has no meaning and is a phonogram in most if not all cases. The exceptions involve cases of two types.
Assume the following hypothetical Tangut B readings (for demonstration purposes only):
그+ ㄇ = a
PERSON = ki
一+ 匕 = chu
PLANT = te
BIRD = po
1. 그+ㄇ is part of a Tangut A-based phonetic:
Base tangraph Derived tangraph Tangut Telecode 4479 0936 Gloss BLACK (kind of tree) Graphic structure top slot empty semantogram (PLANT) phonogram 1 (Tangut B a) phonogram 4 (BLACK; Tangut A nyaa) phonogram 2 (Tangut B ki) phonogram 3 (Tangut B chu) Tangut A reading nyaa 1.21 nyaa 2.21 Tangut B reading (hypothetical) akichu Tangut B word for the nyaa-tree; could even be nyaa if one Tangut language borrowed from the other (do all tangraphs of this type represent shared vocabulary?) 2. 그+ ㄇ is part of a semantic element:
Base tangraph Derived tangraph Tangut Telecode 4479 5739 Gloss BLACK 烏 鴉 CROW Graphic
structureleft slot empty semantogram (BIRD, abbreviated to resemble WAIST*) phonogram 1 (Tangut B a) semantogram (BLACK) phonogram 2 (Tangut B ki) phonogram 3 (Tangut B chu) Tangut A reading nyaa 1.21 liey 1.60? Tangut B reading (hypothetical) akichu Tangut B word for 'crow'; could even be liey if one Tangut language borrowed from the other (do all tangraphs of this type represent shared vocabulary?)
그+ ㄇ may actually be phonetic in either or both cases if the derived tangraphs represented Tangut B compounds: e.g., the Tangut B word for the nyaa-tree was PLANT-BLACK (te-akichu) and the word for 'crow' was BIRD-BLACK (po-akichu).
(A reminder: the 'Tangut B readings' are totally hypothetical and hence certainly wrong.)
Next: Consonantal consensus.
*WAIST is probably a Tangut A phonetic in the full tangraph for BIRD:
| Base tangraph | Derived tangraph | |
 |  | |
| Tangut Telecode | 5649 | 2262 |
| Gloss | WAIST | BIRD |
| Graphic structure | abbrev. of Chn 要 'waist'? or phonogram + phonogram (vertical stack)? | Tangut A phonogram (jyiw) |
| Tangut B phonogram | ||
| semantogram (BIRD, prob. deriv. from Chn 鳥 'bird') | ||
| Tangut A reading | jyiw 1.45 | jywow 1.56 |
| Tangut B reading (hypothetical) | unknown 1 | unknown 2 (represented by the phonogram in the center; the left and right-hand elements are irrelevant for Tangut B pronunciation) |
The structure of BIRD would be like a hypothetical Chinese character
牛β鳥
doing double duty for Eng bird and Md niao 'bird' composed of
牛 Md niu, phonetic element sounding like niao 'bird'
β, phonetic element representing English bird
鳥, semantogram 'bird' (which in fact is the actual sinograph for 'bird')
**The end of chapter IX is missing.
07.3.7.23:31: THE ORIGIN OF ORIGIN (PART 1)
According to the Tangraphic Sea, the right side of MASTER forms the left side of the monosyllabic ritual language word for TANGUT:
<
+
TT0405 TANGUT lhywịy 1.61 <
right of TT5000 MASTER lhyi 2.10? +
right of TT4484 ORIGIN mər 2.76
No Tangraphic Sea analysis survives for either MASTER or ORIGIN.
MASTER is not even in the Precious Rhymes of the Tangraphic Sea. (Why were some tangraphs excluded? Was this accidental?) I have tried to interpret its components in the previous post.
The PRTS entry for ORIGIN does not include a graphic analysis, so I can only speculate that it consists of the common name element TRIBE found in tangraphs for surname syllables:

TT0214 lyụ 2.52
FEMALE and PERSON plus TRIBE
TT1240 tew 1.43
TT1261 'wyu 2.2
HOUSING plus PLANT plus TRIBE
TT1834 nyu 1.3
TT2141 'yow 1.56


TT2193 gyu 2.3
TT2784 ryur 2.70
HAND (cf. Chn 手 'hand') plus TRIBE
TT2940 'yiw 1.45
TT3273 pạ 2.56
PLANT plus TRIBE (cf. TT1261 above)
TT4436 syi 2.33
SURNAME itself is PERSON plus TRIBE:
TT3890 mə 2.25
ORIGIN may share a root with SURNAME:
*mə > mə SURNAME
*r-mə, *mə-r? > mər ORIGIN
Not all surname tangraphs contain TRIBE: e.g.,
TT0191 gjwã 1.26
an unusually simple tangraph
TT0404 tsyi 2.10
BIRD plus INSECT
TT2043 khjwã 1.26
TT2876 pu 1.1
first tangraph in Tangraphic Sea
TT3473 dyï 2.44
PERSON + PLANT over PERSON
and many more.
Moreover, not all tangraphs containing TRIBE are surnames: e.g.,
TT0893 LUXURIANT mə 2.25
PLANT atop the name tangraph TT3273 pạ 2.56
TT1225 SEASON shyow 1.56
incorporates parts of SPRING and AUTUMN
right said to be from ORIGIN
TT3444 VITALITY mə 2.25
TT4054 ROCK meey 2.34
ROCK + ORIGIN
TT4332 SISTERS mə 2.25
TT4379 PLANT/草 GRASS syï 1.30
TT4707 DAYLIGHT zyị̈ 1.69
TT5045 MEET mər 2.76
looks like SKIN + TRIBE
TT5126 MOREOVER lyị̈ 1.69
TRIBE + PERSON; TT3890 SURNAME reversed
TT5750 鶴 CRANE (the bird) mər 2.76
WAIST on the left is probably short for BIRD
The Mojikyo font has a graphic variant of TRIBE in some of these non-tribal tangraphs:
TT5122 WHAT lyị̈ 1.69
TT5123 SLAUGHTER lyị̈y 1.69
(sic; typo for lyị̈ 1.69? -yïỵ is rhyme 1.62)
TT5124 DISTRESS lyị̈ 1.69
TT5125 DISCOURSE lyị̈ 1.69
TRIBE + HAND
Graphic analyses in the Tangraphic Sea treat the two variants of TRIBE are interchangeable (= homophonous in Tangut B?): e.g.,
<
+
TT5123 SLAUGHTER lyị̈ 1.69 <
left of TT5126 MOREOVER lyị̈ 1.69 +
right of TT3131 DEATH ryir 2.72
This may be why both Sofronov and Grinstead treat the two TRIBE-s as a single element.
Five of these are (nearly) homophonous with ORIGIN mər 2.76, ROCK meey 2.34 at least shares an m- with ORIGIN, and six form their own phonetic group (zyï 1.69 and lyï 1.69; z- and l- were Homophones chapter IX initials). SEASON shyow 1.56 is a semantic compound. PLANT/草 GRASS syï 1.30 defies explanation - it looks as if it should be pronounced like the name tangraph TT3273 pạ 2.56, but it isn't.
What's going on here?
- If TRIBE were a purely semantic symbol, it would be used more consistently in surnames. Why don't all surname tangraphs contain it? Perhaps it represents a suffix present in some but not all Tangut B surnames which had no Tangut A equivalent.
- The non-TRIBE parts of surnames may be Tangut B phonetic elements.
- What is the relationship between Tangut (A) surnames and these hypothetical Tangut B surnames? Are the former monosyllabic versions of the latter, like these Sinified versions of Xianbei names? If so, are onomagraphs (name characters) the keys to Tangut B?
- When TRIBE has no apparent semantic or (Tangut A) phonetic value, it may be a Tangut B phonetic symbol: e.g., in MOREOVER.
- The multiple phonetic uses of TRIBE may also give clues to Tangut B phonetic values: e.g., TRIBE seems to have at least two recurring Tangut (A) phonetic values, mə and lyị̈ 1.69. The latter may be the Tangut B word for 'tribe'.
- So could, for instance,
TT2784 ryur 2.70
HAND + TRIBE
have corresponded to a Tangut B surname that sounded like the Tangut B word for 'hand' followed by a syllable similar to mə or lyị̈?
- Conversely, could
TT5125 DISCOURSE lyị̈ 1.69
TRIBE + HAND
have corresponded to a Tangut B word for 'discourse' that sounded like mə or lyị̈ followed by a syllable that sounded like the Tangut B word for 'hand'?
- In short, the Tangut B hypothesis predicts that
TT2784 = X + mə or lyị̈
TT5125 = mə or lyị̈ + X
X = the Tangut B word for 'hand' or at least its second half, judging from
TT1545 HAND lạ
(Did the vertical line signify a prefix added to a Tangut B root represented by the right side which is a recurring semantic element for HAND?)
HAND as a phonetic element could also have been something like lạ, the Tangut A word for 'hand'. Therefore there are 4 possible Tangut B readings of each tangraph, though presumably only one was correct:
TT2784 (a surname) = HAND (X or lạ) + TRIBE (mə or lyị̈)
TT5125 DISCOURSE = TRIBE (mə or lyị̈) + HAND (X or lạ)
If this sounds outrageous, consider a parallel with Japanese writing. It is often difficult for a non-native determine whether a given sinographic sequence in Japanese is to be read as
Sino-Japanese + Sino-Japanese
Sino-Japanese + native (i.e.., 重箱 juubako readings; see below)
native + Sino-Japanese (i.e., 湯桶 yutou readings; see below)
native + native
Examples:
重 箱 'tiered box' looks like it could be
SJ + SJ: *juusou
SJ + native: juubako
native + SJ: *omosou
native + native: *omobako
but only juubako is correct (hence the asterisks for the other hypothetical [not reconstructed!] forms)
湯 桶 'hot water bucket' looks like it could be
SJ + SJ: *toutou
SJ + native: *touoke
native + SJ: yutou
native + native: *yuoke
but only yutou is correct.
These examples actually don't even exhaust the number of potential readings (e.g., 重 can also be chou or SJ kasa) but they get the point across.
In modern Japanese, there are even some ambiguous cases: e.g., these names:
英 世 Eisei (SJ + SJ) or Hideyo (native + native)
(name of an actor, 天本英世 Amamoto; fans have pronounced his personal name both ways; ja.wikipedia.org lists him as Hideyo, but only he really knew!)
一 郎 Ichirou (SJ + SJ) or Kazurou (native + SJ; rare) or Kazuo (native + native); Ichio (native + native) has been used as a female (!) name (the rest are all male, as 郎 SJ rou = 'man' and native o = 'male'.)
Tangraphy may have worked similarly but with mixtures of tangraphic component readings instead of readings of whole characters. A reader would know whether TRIBE stood for mə or lyị̈ in a given tangraph, just as a modern Japanese reader knows that 一 is ichi, kazu, hito (yes, it has another native reading), etc. depending on context. ̣
Next: The other half of the origin of ORIGIN.
07.3.6.23:54: ORIGIN OF THE MASTER
According to the Tangraphic Sea, the right side of MASTER forms the left side of the monosyllabic ritual language word for TANGUT:
TT0405 TANGUT lhywịy 1.61 <
TT5000 MASTER lhyi 2.10? +
right of TT4484 ORIGIN mər 2.76
I have already identified the right side of MASTER as a phonetic element representing lhyi (similar to TANGUT lhywịy which may not have had a medial -w-).
But what about the left side?
TT4990 (I'll reveal its gloss and Gong's reconstruction later)
It occurs in that position in 65 different tangraphs (TT4991-5055). Here are the glosses of twenty of them from Grinstead (1972) and, if not in Grinstead, Li Fanwen (1986) or Shi et al. (2000):
TT4991 溺愛 DOTE-ON kyï 1.30
the Md gloss literally means 'drown love'!
TT4992 (a surname) kyï 1.30
TT4993 (second half of a word 不識 IGNORANT lhia 1.20 jyï 1.30) jyï 1.30
TT4994 TORTOISE-SHELL syiy 2.33
TT4995 鉤帶 HOOK-BELT lhyụ 1.59
TT4996 KNOW-HOW-TO wyị 2.60
TT4997 I/MYSELF myo 2.44
with TT1309 HIGH byiy 2.33 on the right
TT4998 SHINGLE/THIN Ga 1.17
TT4999 ASK 'yïr 2.77
affixed version of TT5050 SAY yï 1.30?
(hereafter I'll list every fifth tangraph)
TT5005 ? lhwe 2.7
not in Tangraphic Sea or Homophones
TT5010 表皮 OUTER-SKIN zhwe 1.8
表 皮 is Md for 'epidermis', but that term sounds too scientific
TT5015 RESIN tew 1.43
TT5020 坦平 LEVEL yï 1.30
TT5025 POT kyï 1.30 (homophonous with TT4992)
TT5030 FLAY/BUTCHER taar 1.83
TT5035 GRAMMAR-WORD/USE wya 1.19
TT5040 CHILD wier 1.78
TT5045 MEET mər 2.76
homophonous with TT4484 ORIGIN mər 2.76; both share right-hand element TRIBE
TT5050 SAY yï 1.30
TT5055 DISAPPEAR mur 1.75
Tangraphs with TT4990 on the left have diverse initials. They appear in eight of the nine chapters of Homophones:
| Chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| Initial type | P | V | T | T | K | TS | CH | ' | L |
| Tangraphs | 9 | 5 | 5 | 0 | 16 | 6 | 5 | 5 | 15 |
(Chapter IV tangraphs are extremely rare.)
They also have diverse rhymes: 25 different level tone rhymes and 17 different rising tone rhymes in three out of four rhyme cycles.
TT4990 appears on the right or on the bottom of 55 other tangraphs (Grinstead 1972: 143-144). Here is a sampling (every fifth tangraph in Grinstead's list, reordered by TT):
TT0832 (a tree) wery 2.66
TT1325 RISE (of water) giwïr 1.86 (sic; was gywïr intended?)
TT1415 SLOW lwow 1.54
TT1799 裁衣 CUT-CLOTHES wə 1.27
TT2072 FOOTWEAR zyị 2.60
TT2515 VENUS syiy 1.36
TT2585 GET-DIRTY we 1.65
TT2999 BOOTS piə 2.26
TT4461 (an animal) tyiy 2.33
TT4783 支撐 PROP-UP thwey 1.33
TT4866 HEAVY zyir 1.79
Six of the nine chapters of Homophones are represented in this small sample alone:
| Chapter | I | II | III | IV | V | VI | VII | VIII | IX |
| Initial type | P | V | T | T | K | TS | CH | ' | L |
| Tangraphs | x | x | x | 0 | x | x | 0 | 0 | x |
TT4990-right tangraphs can also be found in Homophones chapters VII and VIII:
TT4258 MUD/ADOBE chior 2.81 (VII)
TT0953 (a kind of plant?) jyï 1.30 (VII, acc. to Sofronov)
TT3111 襪 SOCKS 'yïy 2.37 (VIII)
TT3135 驚 STARTLE 'yu 1.2 (VIII)
TT5581 AFRAID Gar 2.73 (VIII)
Lastly, TT4990 appears in the middle of tangraphs such as
TT0376 能曉 CAN-UNDERSTAND wyo 2.64
TT2272 細語 PILLOW-TALK shywi 1.10
TT3284 枯 WITHER Ga 1.17
cognate to Old Chinese 枯 kha 'wither'?
Tangut voiced fricative due to prefix-induced lenition?
*C-kha > Ga?
TT3871 貢 PAY-TRIBUTE/奉 PRESENT-WITH-RESPECT? chywo 1.48
TT5754 EAST wyị 1.67 (< *l-w- or *l-p- with dropped prefix?)
looks like TT3087 WAIST jyiw 1.45 + TT5000 MASTER lhyi 2.10!
After all that, can you guess the meaning and reading of
TT4990?
In Pearl 252, TT4990 is equivalent to Chinese 皮 'skin' and has the phonetic gloss 尼責 combining
尼: pre-Tangut Tibetan transcriptions Hji, Hjï, lï (sic; for [ñji]?); my (sic), ni, nyi in modern NW Chn dialects
責: no pre-Tangut Tibetan transcriptions; tsei in modern Xi'an dialect
Gong reconstructed its reading as jyï 1.30. It is clearly phonetic in its homophones
TT0953 and TT4993.
Doubling TT4990 SKIN jyï 1.30 results in
TT5047 kyï 1.30
which is a verbal prefix, not 'two layers of skin'. Nishida (1966: 579) thought it represented "a condition in which it is desirable that an action be carried out" but Sofronov (1968 I.200) called it a 'perfective aspect marker' that "designates an action that has been performed from start to finish". Those interpretations are complete opposites! Nevsky (1960 II.556) gave it the Chinese gloss 已 'already'. In any case, 'double-SKIN' has nothing to do with 'skin' (apart from a shared rhyme - but even if that is noncoincidental, why reduplicate SKIN?).
The Tangraphic Sea analyzed TT5047 as all of SKIN plus the left of the verbal prefix
TT5042 ryir 2.77
which Nishida (1966: 579) interpreted as indicating "the object of the action". Sofronov (1968: I.194) regarded it as a past prefix for verbs indicating actions that took place in the past but have results in the present.
Inserting TT3344 PERSON dzywo 2.44 between SKIN and SKIN results in
TT5037 DEAF ba 1.17
Surely if tangraphy were semantocentric, DEAF would be NOT-HEAR or DEAD-EAR. But
TT1832 EAR nyu 1.3
bears no resemblance to DEAF. If anything, it looks like
TT1850 EYE mey 1.33 (cf. Written Tibetan mig 'eye')
According to Tangraphic Sea, DEAF is from
+
the left of TT5053 STOP-UP-EAR* piẹ 1.66 +
the bottom of TT0889 DYE/DEFILE laa 1.22
The latter has PLANT over
TT3869 COLOR laa 1.22 (the same root with a different spelling?)
which looks like TT3344 PERSON dzywo 2.44 plus SKIN but was analzyed as
+
the left [PERSON] of TT3797 COLOR tsə̣ 1.68 +
the left [SKIN] of TT4997 I/MYSELF myo 2.44
What does I/MYSELF have to do with colors? Why does it look like
+
SKIN HIGH?
And why do most of these graphs share SKIN with
TT5000 MASTER lhyi 2.10?
assuming it means MASTER? Li Fanwen (1986: 435) glossed it as 生 LIFE, 本 ORIGIN. Nevsky (1960 I.557) quoted its usage in Buddhist texts in the compound
TT4858 5000
TEACHER MASTER
dzyiiy 2.35 lhyi 2.10?
which he glossed as 師 'teacher' (in the Lotus Sutra) and as 師主 'teacher-master' (in the 目得迦 Muktaka).
Next: The ORIGIN of ORIGIN.
07.3.7.00:52: ADDENDUM: In Homophones, TT5000 MASTER lhyi 2.10? has the clarifier
TT3579 nyoor 1.95
Li Fanwen (1986: 435) reconstructed MASTER plus its clarifier
TT5000 3579
as lhi nyã 根源 SOURCE, 根本 FOUNDATION. He glossed TT3579 by itself as 根 ROOT.
I cannot understand how TT5000 could be interpreted as MASTER in that compound if it meant SOURCE or FOUNDATION. I suspect that the first tangraph has been confused with (was interchangeable with?) TT3870 本源 SOURCE, a homophone of TT5000 MASTER:
Ironically, TT3870 SOURCE has the PERSON element even though it doesn't (necessarily?) refer to a person, whereas TT5000 lacks the PERSON element even though it does refer to a person! This implies that PERSON has a nonsemantic (i.e., Tangut B phonetic) function in TT3870 SOURCE.
Placing PERSON to the right of MASTER results in the tangraph for another homophone
TT5001 PEACEFUL lhyi 2.10
which of course does not refer to a person.
TT1832 5053
EAR STOP-UP-EAR
nyu 1.3 piẹ 1.66
is glossed as 耳塞 'earplug'. Nishida's (1964: 205) gloss "ear" is presumably a typo.
07.3.5.23:56: ORIGINAL MASTERS
In the previous post, I analyzed the second tangraph for the ritual language word
TT0405 3739 TANGUT
lhywịy 1.61 jyï (rhyme unknown)
Although TT3739 is not in the Tangraphic Sea or the Precious Rhymes of the Tangraphic Sea, its semantic compound structure (PERSON dzywo 2.44 + TANGUT myi 2.10) seems obvious:
<
+
The structure of TT0405 is in the Tangraphic Sea:
TT0405 lhywịy 1.61 <
right of TT5000 MASTER lhyi 2.10?* +
right of TT4484 ORIGIN mər 2.76
(The Mojikyo glyph for TT5000 is practically identical to TT4714, a totally different character. I have created my own TT5000 out of the glyphs for TT4999 ASK 'yïr 2.77 and TT4340 YOUNG lhyi 2.10 [see below].)
The right side of MASTER appears to be phonetic in TT0405. It is a somewhat low-frequency element found on the right of only five other tangraphs (Grinstead 1972: 131; some glosses from Li Fanwen 1986 and Shi et al. 2000):
TT0982 (a kind of tree) kew 2.38
TT4340 幼 YOUNG lhyi 2.10
TT5606 晚產 LATE-BIRTH? jyïr 2.77 (< *C-l-?)
TT3870 SOURCE lhyi 2.10
combines PERSON with TT5000 MASTER
TT5754 EAST wyị 1.67 (< *l-w- or *l-p- with dropped prefix?)
combines TT3087 WAIST jyiw 1.45 (! - a Tangut B phonetic?) with TT5000 MASTER
This element also appears in other positions in
TT0403 敏捷 QUICK lhyi 2.10
TT0552 FRIEND lhyi 2.10
TT0554 FLY (the insect) lhyi 2.10
(cf. Old Chinese 蠅 mə-ləng 'fly')
TT0594 PEACEFUL lhyi 2.10
TT0401 早產 EARLY-BIRTH pə̣ 1.68
(Nishida [1966: 500] has 先師 DECEASED-MASTER and 解く UNTIE with a question mark!)
The right side of ORIGIN appears on the right of surname tangraphs (Grinstead 1972: 88). Following Nishida (1966: 244), I will gloss it as 種族 TRIBE.
Hence TT0405 TANGUT lhywịy 1.61 could be analyzed as 'the TRIBE whose name sounds like lhyi 2.10'. It is tempting to link TT0405 TANGUT lhywịy 1.61 to the Chinese surname 李 Li of the Tangut imperial family. There might be a connection if Li was a Sinicized form of lhywịy 1.61, but the reverse is unlikely. Why would the Tangut take a simple syllable Li** and transform it into lhywịy 1.61 with a voiceless initial, a labial medial***, and what is believed to be a tense vowel? (I would like to explore alternatives to 'intensity' in a later post.)
The Tangraphic Sea defined TT0405 as
lhywịy 1.61 tya 1.20 lhywịy 1.61 jyï (rhyme unknown) lyï 1.29 myï 2.28
nyaa 2.18 lyï 1.29 myi 2.10 dzywo 2.44 'yiy 1.36 'yï 1.30
'TANGUT (subject suffix) TANGUT IS. TAN-
GUT IS. TANGUT PERSON (genitive suffix) SAY.'
'As for the Lhwi, [they] are the Lhwiji. [They] are the Minyaa. [Lwi] is a word for Mi people.'
(I am interpreting [genitive] SAY as a nominalized verb: 'saying': i.e., 'saying of Mi people' = 'what Mi people are called'. Cf. Classical Chinese 之謂 [genitive] 'say'.)
using the other terms for 'Tangut'.
The graphs for three of these terms for 'Tangut' apparently contain flattering elements. Besides MASTER and ORIGIN in TT0405 lhywịy 1.61, TT3301 HOLY/SAGE shyïy 2.37 is in TT3316 myi 2.10 and its graphic derivative TT3536 myï 2.28:
>
>
One might think that the Tangut thought highly of themselves, whereas the Chinese were mere insects. These three tangraphs for 'Chinese' all contain INSECT and SMALL:
+
>
TT1730 ONLY tsyï 1.30 +
(used as component in SMALL graphs; cf. shapes of Chn 小 'small' and 少 'few')
TT1887 INSECT kyiy 1.36 >
TT1760 CHINESE zar 1.80
(etymology unknown; does not sound like any Chinese autonym; homophonous with
TT0407 BITTER/辣 SPICY zar 1.80
TT0639 羞愧 ASHAMED zar 1.80
TT2075 赤面 RED-FACED, 祖宗 ANCESTOR zar 1.80
The latter is surprising since
TT4760 1205
FACE RED
nyiry 2.68 nyiy 1.36 (see the Tangut origin poem)
refers to the 'red-faced' tribe of Tangut.
Tangraphic Sea 1.84A51 defined TT2075 as the 'foundation [lit. 'origin-root'] [of] previous generations' and does not mention 'red' or 'face'.)
TT3102 漢人 CHINESE-PERSON khwa 2.14
(etymology unknown; does not sound like any Chinese autonym; no relevant native homophones)
(the left hand element looks like Chn 亻 'person' and is not the normal Tangut element PERSON! Were the Chinese not worthy of PERSON?)
TT1761 CHINESE xã 1.24
(< Chn 漢 'Chinese', transcribed in Tibetan as han in the pre-Tangut period and pronounced xã, xæ̃, xẼ in modern NW dialects)
TT1760 with unknown right element taken from the surname TT0649 Gu 2.4
TT2122 CHINESE gywi 2.10
(< Chn 魏 [Northern] Wei?; pronounced something like nggwi in the pre-Tangut period)
(Another possible etymology is from the native homophone
TT3962 獸 BEAST gywi 2.10.)
TT1760 with FINGER (Nishida 1966: 244, 469) taken from an unknown sinograph (the Tangraphic Sea analysis is not available)
Next: ORIGIN of the MASTER.
Someday?: Tangut exonyms for other ethnic groups.
*Gong apparently has no reconstruction for TT5000 in Li (1997). I have supplied lhyi 2.10 because TT5000 is in the same homophone group as other lhyi 2.10 tangraphs.
**One should not use modern standard Mandarin in Tangut-Chinese comparisons, but in this case, I am using Li as is because
- the pre-Tangut period transcriptions of the surname 李 were li and lï, presumably representing something not far from Li
- the modern northwestern dialects have forms like Li (though Xining has syllabic L and Lanzhou has nyi [because it has no initial l-]).
***07.3.6.2:2:12: Although Gong and Sofronov reconstructed -w- in this word, Nishida (1966: 500) reconstructed lhẸ and Li Fanwen (1986: 440) reconstructed lhIE before he adopted Gong's reconstruction. The presence or absence of a -w- can only be confirmed through a study of transcriptions involving this homophone group and its fanqie spellers. I cannot take a stand on this issue without firsthand study of this problem.
07.3.4.23:42: A-MYI-RICA!?
If the Tangut had come to America, they might have called it
TT1594 COUNTRY lhyịy (rhyme unknown)
TT1164 BEAUTIFUL mer 2.711
a calque of Chinese 美國 'America' = 'beautiful country'. (美 Md mei 'beautiful' is a phonetic approximation of the -me- of America.) Grinstead (1972: 203) glossed ten tangraphs as BEAUTIFUL2, but I picked the one that sounded like Md mei3.
According to Joseph AP Wilson's "Relatives Halfway Round the World", the Tangut did come to America:
Xi-Xia, a Northeast Tibetan kingdom, fell to Genghis Khan in 1227. Orthodox history maintains that the men were slaughtered and the women enslaved. [Ethel] Stewart [bio], however, argued that the warriors of Xia may have fled to America after the conflict. On the basis of similarities she identified in historical and oral traditions, Stewart believed that these warriors were responsible for the introduction of the Athabascan languages to the continent, sometime after the thirteenth century, making them relatively new to America.
First, the Tangut (why does he use the Mandarin term 西夏 "Xi-Xia"?) were not a "Tibetan" kingdom. They had a Tangut kingdom, the
TT5461 1309 1594 0971
phiow1 byiy2 lhyịy? lyịy2
WHITE HIGH STATE GREAT
'Great State of the White and Lofty'
Second, they did not call themselves '夏 Xia' or '西夏 Western (Xi) Xia' (with one exception after the fall of the Great State; see Kepping 2003: 111). They were the
TT3316 myi 2.10 (hence the title)
or
TT3536 5745
myï 2.28 nyaa 2.18 'Tangut' (cf. Tibetan miñag)
in the common language and the
TT0405 37395
lhywịy 1.61 jyï (rhyme unknown)
in the ritual language. (The second syllable may be dropped.)
I would prefer to use these autonyms once their reconstructions are relatively secure. Until then, I will continue to use Tangut to avoid the Sinocentric terms Xia which could be confused with a Chinese dynasty and Xixia which indicates that the Tangut were to the west of China.
Those two points are less than trivial compared to the third:
The Tangut did not introduce Athabaskan to North America!
Even before looking at any language data, the diversity of Athabaskan languages is far beyond what would be expected for a recent arrival to America. The Proto-Athabaskan (PA) consonant inventory is quite unlike Tangut:
- PA had only two bilabials, *m and *w. Tangut also had three or four different bilabial stops: p, ph, b, and perhaps mb.
- PA had glottalized consonants; Tangut didn't.
- PA had labiopalatals and labiouvulars; Tangut didn't.
- PA had uvulars and most reconstructions of Tangut have no uvulars (this is an open issue I'd like to explore later).
One might expect Wilson and/or Stewart to supply specific linguistic evidence (i.e., regular sound correspondences) for the Tangut-Athabaskan 'connection'. There isn't any in Wilson's paper beyond one proposed pair of 'cognates':
Navajo chindre 'dangerous ghost' : Written Tibetan shi Hdre (< 'dead' + 'ghost')
I don't know what the morphological structure of chindre is, but I would not be surprised if it were monomorphemic.
I have not seen Stewart's book The Dene and Na-Dene Indian Migration 1233 A.D.: Escape from Genghis Khan to America, but linguist William Poser, a specialist in the Northern Athabaskan language Carrier, has. He called it "near gibberish":
Her most general argument can be summarized as follows: "Athabaskan languages are tonal. Chinese is tonal. Therefore the Athabaskans came from Central Asia." Since about 50% of the world's languages are tonal, that two groups of languages should both be tonal proves is likely to be pure coincidence.
Ironically, Chinese turns out to be originally atonal, though it was tonal during the period of this supposed 'migration'.
Most African languages are also tonal - should we conclude that the Athabaskans came from Africa? Furthermore, although China has at times expanded into Central Asia, Chinese is not the indigenous language of Central Asia.
Most of Stewart's linguistic arguments are even worse. She takes Athabaskan names of tribes and places, analyzes them into pieces from Asian languages, and considers this proof that they came from Asia. For example, she thinks that the Carrier Indians of British Columbia are called "Taculi". She says that these are obviously the people of the Li clan of the city of Tagu. This is far too easy a game to play and proves nothing, but in any case she ignores the fact that "Taculi" is not the correct form of the name and that the correct form has an etymology inconsistent with hers. "Taculi" is a distortion of the way that Father Adrien-Gabriel Morice [Wikipedia bio] wrote the self-designation of the Carrier, which in the current practical spelling is "Dakelh", where the "lh" represents a voiceless lateral fricative (like Welsh "ll"). It means "the people who go by boat on the water" and consists of two parts, da and kelh.
Her book is filled with "arguments" of this sort. In some cases she even assigns each of the three syllables of a word to a different language. Arguments of this type prove nothing other than that the author has an imagination.
Suffice it to say that Carrier is nothing like Tangut, and that the differences don't stop at the consonant inventory either.
Wilson mentions Sapir's, Shafer's, and more recently "Soviet" (i.e., Starostin's) attempts to hook up Sino-Tibetan with Na-Dene (of which Athabascan is a part) but does not mention that this viewpoint has never been widely accepted.
I seriously wonder whether Wilson or Stewart understand Asian language diversity. In his introduction, Wilson begins talking about "Xia", switches to "Tibetan", and then uses the neologism "Xia-Tibetan". I often see Tangut regarded as Tibetan by nonspecialists. Surely Wilson should know the difference, but I don't think he does. He equates "Tangut" with "Xia Tibetan" and then switches to the term "Tangut Tibetan":
Tangut Tibetan is so 'archaic' in appearance that it has been dubbed 'proto-Tibetan'.
He cites Andrea and Overfield (1994), which I have not seen. I have never heard of a language called 'Tangut Tibetan'. I doubt he was referring to the Tibetan dialect(s) spoken within the borders of the Tangut Empire. Nothing is known about those dialects. Tangut definitely is not "proto-Tibetan".
With one exception, none of the arguments in his paper revolve around anything specifically Tangut. It is as if he assumes 'Tibetan' and 'Tangut' were interchangeable. The exception involves prefixes. His argument seems to boil down to:
Athabascan has prefixes (which ones?) that look like "Xia Tibetan" prefixes (which ones?)
He quotes Wolfenden's article on Tangut prefixes -
He [Wolfenden] states that the first consonant in Tangut compounds [!?] is not a simple prefix, but 'the main element of the group, to which the following syllable was merely an appendage'
- without understanding it. In that passage, Wolfenden was explaining how the Tangut transcribed Sanskrit initial clusters like mr- (an initial cluster which was not possible even in the prefix-preserving varieti[es] of Tangut).
Guillaume Jacques would not be amused by this line:
For further evidence, Sino-Dene scholars need to pay particular attention to Jyarung [rGyalrong], and to other Central Asian languages.
rGyalrong is not a Central Asian language! Of course, Turkic and Mongolic languages are Central Asian, and they too play a part in Wilson and Stewart's, uh, vision:
Conventionally [!?], all cognates [alleged to exist between Sino-Tibetan and Na-Dene] are considered to be ancient in origin and the usual assumption therefore, is that Na-Dene speakers left the Old-World prior to the Neolithic.The Stewart hypothesis provided an elegant alternative; Na-Dene is a blending of Tibetan, Chinese, Turkic, and Mongolian dialects, with Indo-European influences, which developed on the Silk Road route between the Tarim Basin and Xi-Xia in the early Common Era.
Later in his paper, Wilson mentions that Stewart believed
that the divergence between Haida (a Turkic [!?] form of Chinese 'Hei T'a-T'a' [a unintentional mixture of 韃靼 Dada and 塔塔兒 Tataer?] or Black Tartar) and Athabascan may reflect the differences between the languages of the main army of Xi-Xia and those of their later Jurchen allies ... She speculated that these later Jurchen arrivals maintained their distinctive language [in North America!].
The 黑韃靼 Hei Dada Mongols (not Turkic, despite their name) were not the Tungusic-speaking 女眞 Jurchen, and Haida is, as you would expect, nothing like Jurchen.
Apparently Stewart also believed that the Jurchen were the Na-Dene 'black people'6, as opposed to the Dene or Diné 'people' who were the Tangut (who, as we have seen above, never called themselves anything like Dene or Diné). But wouldn't that make the Tangut the Haida as opposed to the Na-Dene Jurchen? I'm lost ...
Then again, wasn't Na-Dene supposed to be "a blending"? That idea is very 'attractive' because it allows one to find lookalikes between any Na-Dene language and anything in Sino-Tibetan, Turkic, Mongolic, and even Indo-European (yet Tungusic, which Jurchen belongs to, isn't even mentioned!). The possibilities are endless! How 'exciting'! How unconstrained - and unscientific!
Science has little to do with this. Wilson opens with a Vine Deloria quotation:
I personally feel that unless and until we [Native Americans] are in some way connected with world history as early peoples, perhaps even as refugees from Old World turmoils and persecutions, we will never be accorded full humanity. We cannot be primitive peoples who were suddenly discovered half a millennium ago.
I find this statement to be Eurocentric, though that was surely not Deloria's intent. Why must indigenous peoples of the Americas be 'validated' by linking them to the "Old World" (itself a loaded term)? It is as if Eurasia were the 'standard'. Why 'colonize' their history by implanting alien elements? Why can't the First Nations be recognized on their own terms? Why attempt to appease racists?
The biggest surprise of the paper - aside from its central claim - is not the fact that it was published in a peer-reviewed journal (that "encourages creative methodologies"!) but that it was based on the author's University of London MA thesis7!
Next: Back to real Tangutology, or at least my best shot at it ...
07.3.5.4:21: ADDENDUM: If you need more of this sort of thing, look at the articles listed under "For the Ethel Stewart Reader" at the Midwestern Epigraphic Society: e.g.,
The male ancestors of the Dene tribes were remnants of the shattered Hsi-Hsia army.
That article also reveals Stewart's etymology of Athabaskan:
Atha begins with the Tibetan noun prefix, a [for family terms!], also used in the Tarim, and tha is the Hsi-Hsia word for Buddha [it is], -baska is a transcription from sound of bskyan [does she mean bskyang?], a N.E. [really?] Tibetan verb meaning protect. In the old Tokharian [as opposed to a nonexistent new Tocharian?], there was no final n [can someone check this?], and it appears that language habits in the Tarim survived in spoken dialects. Atha-bskyan was Atha -bskya. and with the conjecture that is necessary [!] in arriving at the meaning in Tibetan, Atha-bskya(n) means Protected by Buddha.
So obviously Ramtha must be the dancing Buddha. (Thai รำ ram is 'dance'.)
I never got around to reviewing the book 1421 two years ago. You can look at this page from the book's official site and guess why I didn't bother:
Ethel Stewart provides a convincing case that the Navajo were Chinese fleeing Genghis Khan.
Tibetan, Tangut, Chinese - what's the difference? All them Sino-Tibetans, er, Sino-Dene are alike. How alike?
"… The Tartar Chinese [the who?] speak the dialect of the Apaches ... In about the year 1885, W. B. Horton, who had served as County Superintendent of Schools, at Tucson, was appointed Post Trader at Camp Apache, and went to San Francisco to purchase his stock, where he hired a Chinese cook ... [He] found his cook conversing with an Apache. He asked his cook where he had acquired the Indian language. The cook said: "He speak all same me. I Tartar Chinese; he speak same me, little different, not much." At Williams, in Navajo County, is another Tartar Chinaman, Gee Jim, who converses freely with the Apaches in his native language. From these facts it would seem that the Apache is of Tartar origin. From the fact that the Apache language was practically the same as that of the Tartar Chinese, colour is given to the theory advanced by Bancroft in his "Native Races," Volume 5, p. 33, et seq., that Western America was "originally peopled by the Chinese, or, at least, that the greater part of the new world civilization may be attributed to these people…"
On p. 488 of 1421, we learn that Navajo "elders to this day understand Chinese".
So you're sold on Sino-Dene, or better yet, Eurasian-Everything-Dene. What lies next along your path of enlightenment? The Algonquin-Irish-Turkish connection? "Egyptian traces in Hawaii"? Be brave. Open your mind. Learn Earth Mother Sacred Language!
Seriously, the phenomenon of paralinguistics deserves to be examined as a cultural phenomenon. Why did people feel compelled to bombard the late Basque linguist Larry Trask with
[their] latest proof that Basque is related to Iberian / Etruscan / Pictish / Sumerian / Minoan / Tibetan / Isthmus Zapotec / Martian
[their] discovery that Basque is the secret key to understanding the Ogam inscriptions / the Phaistos disc / the Easter Island carvings / the Egyptian Book of the Dead / the Qabbala / the prophecies of Nostradamus / your PC manual / the movements of the New York Stock Exchange
[their] belief that Basque is the ancestral language of all humankind / a remnant of the speech of lost Atlantis / the language of the vanished civilization of Antarctica / evidence of visitors from Proxima Centauri
I am surprised that there haven't been more Tangut fantasies. If only the Tangut were as famous as the Basques ...
1I don't actually think TT1164 means BEAUTIFUL (Grinstead 1972: 136), but I thought it's appropriate to have a dubious gloss in a post about a very dubious proposition.
In Homophones, TT1164 mer 2.71 has the clarifier
TT2692 TOPKNOT rer 2.71
mer2 rer2 might be a rhyming binom.
Li Fanwen (1986: 214) reconstructed it as mI2 rə̣i2 (with rhyme 2.7 for the first syllable!4) and glossed it as 鬘飾 'hair decoration'. He glossed its halves as
TT1164: 飾 'decoration'
TT2692: 纓 'tassel', 鬘 'beautiful (hair)/floral headdress', 網 'net', 捲 'roll'
Nevsky (1960 II.367) glossed TT2692 as 镸+曼, one of many variants of 鬘 as well as 纓 and 鬘 itself.
Both Nishida (1966: 472) and Shi et al. (2000: 306) glossed TT2692 as 鬘.
Shi et al. did not gloss TT1164, since it is not in Precious Rhymes of the Tangraphic Sea.
Nevsky (1960 II.367) also did not gloss TT1164. In his entry for TT1164, he provided a six-tangraph line (a gloss?) presumably copied from an unknown source:
? ?
ADORNED ? ? WORD ESTABLISH ALSO
I cannot identify the second and third tangraphs which resemble TT1698 BROAD and TT1745 WEAKEN.
TT1164-2692
may be a N-Adj sequence ('decoration beautiful') or a N-N compound ('decoration-headdress').
Like Grinstead, Nishida (1966: 423) glossed TT1164 as an adjective (莊嚴 'solemn') but this implies that TT1164-2692 is an Adj-N sequence which is odd though not impossible in Tangut.
Trying to figure out what a tangraph represented can make me rather
TT0413 CONFUSED mer 2.71
This may or may not be a homophone of TT1164 BEAUTIFUL mer 2.7 (or should I say 2.7[1]?4).
The structure of CONFUSED is confusing. Its left half appears to be BIRD (why?) and its right half appears in negative tangraphs:
TT4856 ENEMY za 1.17
TT3225 POISON do 2.42 (loan from 毒 Late Old Chinese douk or Middle Chinese dok 'poison'?)
TT4514 POSSESSED (by a spirit?) tsyụ 1.59
TT3763 HATE zhyïï 1.32
TT4558 HURT chyu 1.7
TT4618 CURSE zhier 1.78
TT4688 CURSE/RESENTMENT nyïï 2.29
TT0122 SPELL xya 1.19
TT3178 EVIL niow 2.48
TT3363 (deprecatory first person pronoun) gyï 2.28
Ssee Grinstead (1972: 128).
I wonder if CONFUSED sounded like the Tangut B word for BIRD: i.e., its structure is
BIRD (phonetic) + BAD (semantic)
Not all tangraphs with the BAD element have obviously negative meanings: e.g..,
TT1511 COARSE byạ 1.64
TT4828 FAT wọ 1.70
TT4935 SET/GO-DOWN bə (rhyme unknown)
TT4506 SILENT dwerw 2.78
TT0505 INFORM tshyar 1.82
TT1797 (a surname) tshyiy 1.36
TT2539 A-TIME/(transcription tangraph) zhya 2.16
TT0769 (a kind of tree) Gor 1.89
The vague phonetic resemblance of some of those syllables to Middle Chinese 邪 zya 'evil' is probably coincidental. The pre-Tangut period Tibetan transcriptions of 邪 are zya and sya. The z to s shift was probably complete by the Tangut period. 邪 is pronounced with sh- (< *sy-) in modern northwestern Chinese dialects. So it is doubtful that the Tangut would use a native phonetic element BAD to represent syllables with initial z-.
2Grinstead (1972: 199) observed that he was surprised by
the frequency of multiple Tangut solutions to a simple English word. Given that the Tangut vocabulary (sic!) was about 5800 characters [but characters can represent parts of words as well as words!], this richness of synonyms is worth further investigation.
Some of these synonyms later on turned out to be part of the Tangut ritual language. Since
- according to Kepping, ritual language words are "usually" disyllabic
- Grinstead apparently counted syllables as 'words'
this means that Grinstead saw three 'synonyms' when there may have actually been only two (the monosyllabic normal word and the two tangraphs for its disyllabic ritual language synonym). I will explore the statistical implications of ritual language disyllabism in a future post.
CONFUSED itself formed the bottom of another tangraph with a similar meaning:
<
+
TT4374 CONFUSED lha 2.57 <
top of TT4530 TORMENT lyu 2.2 +
all of TT0413 CONFUSED mer 2.71
Did the 그 element represent a Tangut B prefix in TT4374 CONFUSED?
TT0413 CONFUSED: Tangut A mer 2.71 : Tangut B X (sounded like the Tangut B word for 'bird'?)
TT4374 CONFUSED: Tangut A lyu 2.2 : Tangut B Y-X (had same first element as 'torment')
TT4530 TORMENT: Tangut A lha 2.57 : Tangut B Y...?
Colons signify rough translational equivalence.
The bottom of TT4530 TORMENT does not occur independently, suggesting that the 그 element represented either part of the root or an inseparable prefix in Tangut B. (Its sole function from a Tangut A perspective was to distinguish between two phonetically dissimilar but semantically similar syllables, mer 2.71 [written without 그] and lyu 2.2 [written with 그].)
3美 Md mei < Old Chinese *mrəy' 'beautiful' may even be cognate to Tangut mer 2.71, assuming that the latter actually did mean 'beautiful'. The retroflex vowel of Tangut mer 2.71 implies an earlier *rme, *mre, or *mer. But the retroflexion of the vowel is not certain. See the next note.
4Since TT1164 BEAUTIFUL mer 2.71 is not in any extant volume ofTangraphic Sea, there is no way to be certain about its rhyme. In Homophones, it is listed in the same group as
TT3567 SHINE me 2.7
TT3929 (a surname) me 2.7
TT3730 (a surname) mey (sic; -ey is rhyme 2.30; should be me) 2.7
TT3124 (the trigram 巽) me 2.7
TT3122 DUST me 2.7
TT3123 (a star) me 2.7
TT3127 RUBBISH me 2.7
TT0156 YOUNGER-SISTER me 2.7
All but two (TT3123 and TT3127) were listed under rhyme 2.7 in Precious Rhymes of the Tangraphic Sea. I do not know how Sofronov and Gong determined that BEAUTIFUL, (a star), and RUBBISH respectively belonged to rhymes 2.71, 2.7, and 2.7. Li Fanwen assumed that all members of the group belonged to the same rhyme (2.7). Since other 2.71 rhyme syllables are not mixed in the group, I would guess that TT1164 is not a lone 2.71 syllable but is a 2.7 syllable like the others.
If TT1164 belongs to rhyme 2.7 (me) rather than 2.71 (mer), it would be more difficult to relate it to Old Chinese *mrəy' 'beautiful' since me lacks a retroflex vowel implying an earlier *r corresponding to Old Chinese *-r-.
TT3739 jyï (rhyme unknown)
is the only nonobscure tangraph I've never been able to find in Grinstead (1972). It should be on p. 130 next to
TT3316 TANGUT myi 2.10
since Grinstead indexes from the bottom right corner.
TT3739 is obviously a compound of PERSON and TANGUT:
There is nothing special about this ritual language character in terms of its graphic components which both represent common language words.
TT3316 TANGUT appears to be a compound of
TT3301 HOLY/SAGE shyïy 2.37)
(loan from Chn 聖 'holy'?; its pre-Tangut period pronunciation was transcribed in Tibetan as she, shing, sheng, zheng and in Khotanese Brahmi as she; pronounced Shə̃ or Shəng in modern northwestern dialects)
with a right element of unknown function.
6Psssst, don't tell Wilson that one Tangut word for 'black' is
TT4479 nyaa 1.21
which sounds like the Na of Na-Dene ('black people' according to Stewart). But
- Tangut nyaa follows the noun it modifies, unlike this Na-
- na actually means 'to live; house' in Haida.
Sapir's term 'Na-Dene' is a combination of Haida na, Tlingit na 'people', and dene ('person' in Athabaskan languages) (Cook and Rice 1989: 50).
707.3.5.3:39: "Nan-pa'i-Chos-ni, A-lHa-bsKyans sam: The Buddhist Chos: Protected by a Celestial Lord? The Nabaxu: Athabaskan?"
"Nan-pa" 'Buddhist' should be nang-pa.
"A-lHa-bsKyans" is Wilson's attempt at Tibetanizing Athabaskan. "-ns" is not possible in Tibetan. (But see the addendum!)
The title is literally
Buddhist-(genitive) dharma-(topic marker) Athabaskan (question marker)
I don't know why Wilson inserted a hyphen between the genitive (-'i) and the following noun (Chos).
The title on the University of London page omits the first half.