
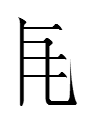
TT1955 LITERATURE 'ywïr 2.77
(Tibetan transcription d-wïr [Nevsky 1926 #55])
07.2.17.23:59: D-BRI(S) (PART 2)
In part 1, I proposed that Tangut
TT1955 LITERATURE 'ywïr 2.77
(Tibetan transcription d-wïr [Nevsky 1926 #55])
was from some form of Written Tibetan (WT) Hbri-ba [mbri ba] 'write' (root bri; past/imperative bris, future bri)?
The Tangut retroflex vowel rhyme -ïr 2.77 implies that 'ywïr originally had an r somewhere in it. It could have once been something like'wrï or 'wïr. (I believe that the -y- is secondary, if it existed at all*). 'wrï is not very far from the WT root bri 'write'.
As far as I know, no one has looked into Tibetan loanwords in Tangut, though many Tibetan-Tangut cognates (not loanwords) have been proposed. It is possible that some of those cognates are actually loanwords from Tibetan rather than genuine inherited vocabulary.
Tangut may have been like rGyalrong, which contains both words inherited from the common ancestor of rGyalrong and Tibetan and words borrowed from Tibetan. Guillaume Jacques' 2003 study "An preliminary study of Tibetan loanwords and cognates in Japhug rGyalrong (hereafter JG)" (p. 2) attempted
... to develop a technique to distinguish [Tibetan] loanwords from cognates, and to analyse the stratification of the [Tibetan] loanwords [in JG].
According to Guillaume (p. 5), WT b- corresponded to JG p- initially and to JG -w- after a presyllable: e.g.,
This is not unlike my proposal:WT pho-brang : JG pho-wrang 'palace'
WT (H)bri(s) : Tangut də-bri(s) > də-wïr, 'ywïr (with a native prefix of unknown meaning attached)
WT Hbr- (mbr-) corresponded to JG mbr- with one exceptions involving the word in question:
WT Hbri-ba : JG kë-rët 'write'
I am not sure this actually is an exception, because the rhyme correspondence (WT -i : JG -ët) is very odd. JG -ët corresponds to WT -od (p. 8) and it is hard to imagine why a WT open syllable would have a final -t attached to it in JG (unless the -t were a JG suffix). WT -i corresponds to JG -i in
WT rtsi : JG kë-rtsi 'to count'
I would expect 'write' to be JG pri, mbri, or kë-wri (cf. pho-wrang 'palace' above). Perhaps kë-rët is a native JG word.
Looking at Guillaume's paper made me wonder if I could find any instances of correspondences like
WT br- : JG p-, -w- : Tangut '(y)w-
WT Hbr- : JG mbr- : Tangut '(y)w-
I looked in Guillaume's "Essai de comparaison des rimes du tangoute et du rGyalrong" (2003) and could not find any examples of Tangut 'yw- words with proposed JG cognates. However, I did find that Tangut (')w- generally corresponded to JG p:
| Gloss | Tangut Telecode | Tangut | Tangut rhyme | Japhug rGyalrong of gDong-brgyad |
| to do | 2413 | wyi (< -a) | 1.10 | kë pa |
| 3666 | wyo (< -wyi [< -a] + -o) | 1.51 | ||
| bird | 2483 | we (< -a?) | 1.8 | pGa < pk- |
| year | 1605 | wyi (< -a) | 1.10 | xpa < qp- |
| snow | 0606 | wyị (< -a) | 1.67 | të ypa |
| axe | 5203 | wyị (< -a) | 1.67 | tU rpa |
| know how to | 4996 | wyị (< -a) | 2.60 | kë spa |
| pig | 5360 | wa | 1.17 | paR |
| shoulder | 2695 | wạ | 1.63 | tu rpaR |
| carry | 0978 | wạ | 2.56 | kë më rpaR 'carry on the shoulder' |
| guest | 3715 | wyi | 1.10 | tU pi (in gSar-rdzong dialect) |
| soft | 1185 | wəə | 1.31 | kU mpU |
| small intenstines | 1263 | wyu | 2.2 | tU pu |
| thick | 4828 | 'wọ | 1.70 | kU ypum |
| ice | 0600 | 'wọ | 1.19 | të pGom < ... pk- |
Proto-Tibeto-Burman kyam 'ice' [Matisoff 2003: 655] > p-kyam > pkywam > pkom > Tangut 'wọ, JG të pGom
But Matisoff [2003: 641] doesn't reconstruct any k-initial word for 'bird' in PTB. The Tangut word we 1.8 'bird' might be from PTB bya or wa 'bird' whereas proto-rGyalrong pka (?) 'bird' [> JG pGa] might be unrelated.)
(All but the last two Tangut syllables in the chart above were written with tangraphs listed in Chapter II of Homophones. I still want to write part 12 of "Lip Sounds Light". This almost counts as part 12 because it lists so many Chapter II syllables. 'w-syllables such as 'ywïr 2.77 'literature'were listed in Chapter VIII ["Gullet Sounds"] of Homophones.)
There were a few exceptions to the correlation between Tangut w and JG p [chart added 07.2.18]:
| Gloss | Tangut Telecode | Tangut | Tangut rhyme | Japhug rGyalrong of gDong-brgyad |
| rust | 2585 | wẹ | 1.65 | sGa < sə-w- (Jacques 2004: 328) |
| father | 1999 | wya | 1.19 | a wa |
| fart | 2304 | wiəy | 2.36 | tU phe (in gSar-rdzong dialect) |
| to spit | 0559 | wya | 1.19 | kë mU yphët |
| old | 4906 | wə̣ | 1.68 | ku mbe |
| 5699 | wyị̈ | 1.69 |
The odds are that 'ywïr 2.77 'literature' originally had an p- (though the minority of correspondences suggest other labials: w-, ph-, mb-). But if earlier p-, ph-, mb- became (')w-, then where did Tangut p-, ph-, b- come from? Tangut p- also corresponds to JG p-:
| Gloss | Tangut Telecode | Tangut | Tangut rhyme | Japhug rGyalrong of gDong-brgyad |
| sorcerer, exorcism | 3337 | pyịy | 1.61 | të rpi 'sutra' (presumably a derivative or redefinition of a native word having to do with magic) |
| pus | 2309 | pə̣ | 1.68 | të spU |
| burn | 0993 | pyu | 2.3 | kë pu 'roast in cinders' |
| 0604 | pyo | 1.51 |
Assuming that
- Tangut and JG shared an ancestor
- early Tangut and JG prefixes do not necessarily match
perhaps
- early Tangut p lenited (= weakened) to w after a prefix that later dropped (in the Homophones/Tangraphic Sea dialect[s] but perhaps not in the more conservative dialect reflected in the Tibetan transcriptions). If Tangut was like JG, it had lots of prefixes.
Cf. the lenition of proto-rGyalrong p- in JG if preceded by k- or t- (Jacques 2004: 272):
proto-rGyalrong kp- > JG VG-
proto-rGyalrong tp- > JG tG-
- early Tangut p remained intact if there was no prefix
Similar processes may have affected other early Tangut labials:
early Tangut C-ph-, C-mb- > Tangut w-
but
early Tangut ph-, mb- > Tangut ph-, b-.
The cases of Tangut w corresponding to JG w may reflect early Tangut 'primary' w (as opposed to 'secondary' w originating from earlier p after prefixes).
JG mbr- (< proto-rGyalrong m(b)r- [Jacques 2003: 281] corresponds to Tangut b- (5 times) and r- (2 times) [chart added 07.2.18.1:21]:
| Gloss | Tangut Telecode | Tangut | Tangut rhyme | Japhug rGyalrong of gDong-brgyad |
| string | 5008 | byi | 2.10 | tU mbri |
| willow | 0983 | biə | 1.28 | qa zhmbri |
| 3469 | biẹ | 1.66 | ||
| high | 0494 | byï | 1.30 | kU mbro |
| 1309 | byiy | 2.33 | ||
| horse | 5233 | ryiry | 1.74 | mbro |
| 4789 | ryar | 2.74 |
'Horse' originally had mr- (cf. Written Burmese mrang 'horse' and perhaps early WT rmang** [with rm-!]) so it seems that
mbr- > JG mbr-, Tangut b-
but
mr- > JG mbr-, Tangut r- (not mbr-).
Some reconstruct mb- instead of simple b- in Tangut. Tibetan transcriptions with Hb- [mb] and b- in Nevsky (1926) suggest that both pronunciations may have existed simulaneously (as variants within the same dialect and/or as variants among dialects?):
Hbi [mbi] ~ Hbhi [mbhi] ~ dbhi 'below' (#125; TT3591; Gong: byi 2.10)
Hbu [mbu] ~ dbu 'according to' (#164; TT4614; Gong: byu 2.3)
HbhiH [mbhii?] ~ dbri 'brilliant' (#247; TT1648; Gong: byi 1.11; no retroflex vowel, despite the -r- in the transcription which Nevsky wasn't sure about)
(I don't think there was mb- ~ db- variation. m and d are too different. Perhaps the actual alternation was between mb- and d-mb- [a cluster not in WT].)
If
WT Hbr- : JG mbr-
and
JG mbr- : Tangut b- (mostly)
I would expect
WT Hbr- [mbr-] : JG mbr- : Tangut b-
And since the Tangut word for 'literature' does not start with b-, I don't think it is from WT Hbri [mbri]. It must be from one of the b-initial forms: bris 'wrote/write!' or bri 'will write'.
JG seems to have borrowed the present or past forms of WT verbs (Jacques 2003: 11). If Tangut was like JG, then presumably 'ywïr 2.77 'literature' may have been from the WT past form bris with an added prefix:
WT bris > early Tangut də-bri(s) > later Tangut də-wïr (transcribed as d-wïr), 'ywïr (with a native prefix of unknown meaning attached)
07.2.18.00:07: Could the final -s of WT bris be reflected in the second tone ('rising tone') of Tangut 'ywïr 2.77?
The origin of Tangut tones (phonation? - as I suggested ten years ago) is still unknown. If Tangut was like its neighbors (Tibetan and Chinese), it would have developed phonemic tones to compensate for lost initial and final consonant contrasts: e.g.,
syllables without final -s > first / 'level' tone
syllables with final -s > second / 'rising' tone
The above scheme is too simplistic, as it cannot account for the fact that about half the syllables in Tangut had a rising tone. For comparison, only about a quarter or fifth of the syllables in Old Chinese had final -s, and the figure of final -s syllables in WT is much less than half (though -s is not uncommon either, as it is a past and imperative suffix: bri-s 'wrote/write!'). Tangut rising tone may therefore reflect more than one lost final consonant: e.g., a glottal stop -' as well as -s.
*The absence of the -y- in the Tibetan transcription d-wïr does not tell us anyhing about the presence or absence of -y- in Tangut since it is possible that
- the -y- was ignored, since -wy- and -yw- are not possible letter combinations in Tibetan (though do note that the transcriber was not reluctant to use other un-Tibetan combinations such as d-w- [as opposed to dw-])
- the -y- was not in the transcribed Tangut dialect but was in other dialects
**07.2.18.00:21: As far as I know, WT doesn't allow initial mr- (see Guillaume's chart of WT initials), so it is possible that rm- is from earlier mr-. I would like to read Coblin's 1974 article "An Early Tibetan Word for 'Horse' " but I don't have access to a library.
Although WT does not permit mr-, WT does permit the labial + r combinations phr- and br-. So why wouldn't mr- be retained as is? Perhaps mr- was regarded as being like wr- (another currently non-WT combination; rw- is possible). I wonder if WT rw- < wr- in some cases; if so, then maybe some rm- < mr-.
07.2.16.5:44: D-BRI(S) (PART 1)
It occurred to me last night that the word
TT1955 LITERATURE 'ywïr 2.77
(Tibetan transcription d-wïr [Nevsky 1926 #55])
which forms part of the title
Tangraphic Sea (with TT5280 SEA ngyow 2.48)
and the word mentioned at the end of "Educharacters"
'character' (with TT3309 CHARACTER dyi 2.10)
might be a borrowing from Tibetan: cf. Written Tibetan Hbri-ba 'write' (root bri; past/imperative bris, future bri).
At first, 'ywïr 2.77 and WT Hbri [mbri] don't look much alike, but they contain a suggestive correspondence:
T 'y-r : WT br- (before i): cf. T 'yar 1.82 : WT brgyad 'eight'
(in which br- is before the i-like vowel -y-, with an intrusive -g-: bry- > brGy- > brgy-)
The medial -r- has left a trace in the retroflex vowel of 'ywïr. (See part 3 of "Retroflexion: Right or Wrong".)
Then again, I suspect that the -y- of 'ywïr was secondary for reasons I won't go into here. So I can't really compare 'ywïr (< 'wïr?) with 'yar whose -y- is primary (i.e., original), not secondary.
Perhaps the original Tangut form was something like də-bri, combining the root of the Tibetan loanword with a native Tangut prefix of unknown meaning. The Tibetan transcription d-wïr represented a dialect in which də-bri became də-ywïr, with -b- weakening to -w- (phonetically [v]?) after a prefix. The Homophones dialect may have had a different prefix that reduced to a glottal stop: Qə-ywïr > 'ywïr (Q = an unknown back consonant, possibly a glottal or uvular stop; cf. rGyalrong q-).
Next: What's wrong with this scenario?
07.2.15.3:05: EDUCHARACTERS
The tangraphs missing from "Glagolloon" are up now. Actually, they were up - but in the wrong directory!
While looking in my PC's tangraphic directory, I noticed that I had made 822 GIFs of Tangut characters over the past year. That's about a seventh of the c. 6,000 tangraphs in existence. If this site ran for six more years, every single tangraph might eventually show up.
How many tangraphs did the average literate Tangut know? About half the characters were for the Tangut ritual language (Kepping 1996). Were those tangraphs part of the normal literate Tangut's repetoire? The fact that the ritual language tangraphs weren't kept out of Tangraphic Sea and Homophones indicates that they weren't some closely guarded secret. But inclusion doesn't entail widespread knowledge either.
How did the Tangut acquire a knowledge of their writing system? The figure of 822 GIFs reminded me of the 881 (now 1,006) 敎育漢字 kyouiku kanji 'educational Chinese characters' taught to Japanese primary school students. Compare the first grade kyouiku kanji with their Tangut equivalents:
TT3709 ABOVE phyu 2.3 (13 strokes; cf. Chn 上 'above'; 3 strokes)
TT3591 BELOW myiiy 2.35 (13 strokes; cf. Chn 下 'below', 3 strokes)
TT1564 LEFT zhyị̈ 1.69 (11 strokes; cf. Chn 左 'left', 5 strokes)
TT3303 RIGHT chier 1.78 (12 strokes; cf. Chn 右 'right', 5 strokes)
TT5241 MIDDLE gu 2.1 (13 strokes; cf. Chn 中 'middle', 3 strokes)

TT0971 BIG lyịy 2.54? (thạ 2.54 is a mistake) and its 'mirror image'
TT5660 BIG khwey 2.30 (both 15 strokes; cf. Chn 大 'big'; 3 strokes)
TT3584 SMALL tsəy 1.40 (10 strokes; cf. Chn 小 'small', 3 strokes)
TT3313 MOON/MONTH lhyịy 2.60 (12 strokes; cf. Chn 月 'moon/month', 4 strokes)
TT5678 DAY nyïï 2.29 (11 strokes; cf. Chn 日 'sun/day', 4 strokes)
TT3548 YEAR kyiw 1.45 (10 strokes; cf. Chn 年 'year', 6 strokes)
In the above sample, the average kyoiku kanji has 3.9 strokes, whereas the average tangraph has 12.3 strokes. The average Chinese character may have about 10 strokes, but nearly all tangraphs seem to have about 10 or more strokes with rare exceptions like
WAIST, PERSON (not the default character which is TT4105 with 10 strokes), ONE, HOLY, and HIGH (cf. Chn 人 聖 一 高; Tangut can be simpler in a few cases!).
Moreover, all of the kyouiku kanji in the examples above were simple, whereas all of the tangraphs (except for the four directly above) were compounds of graphic elements: e.g.,
WAIST in BIG (but not SMALL) and DAY (but not MOON/MONTH)
PERSON in ABOVE, RIGHT (but not LEFT), MIDDLE, SMALL (but not BIG), and YEAR
HOLY in MOON/MONTH and DAY
Other elements still elude identification: e.g., the ヒ on the right side of MOON/MONTH.
Presumably the elements that do not make semantic sense (like WAIST!) were phonetic symbols (for Tangut B readings, analogus to the kun [native Japanese] readings of the kyouiku kanji?). I am reluctant to envision Tangut students memorizing semi-random element combinations with no obvious semantic or phonetic relationship to Tangut (A).
For further comparisons of tangraphs and sinographs, go to Kotaka Yuuji's Cyberpearl to see 1,000 tangraphs (column 4) with their Chinese equivalents (column 8). According to Kotaka, those thousand tangraphs are sufficient to write 90% of (non-ritual) Tangut texts. Perhaps I could call them the
TEACH-REAR LITERATURE-CHARACTER
we2'yiw1 'ywïr2dyi2
a calque of 敎育文字 kyouiku moji 'educational characters'.
(Li Fanwen [1986: 425] translated TT0395 'yiw1 with 育 'to rear'. [It is even remotely possible that 'yiw1 was borrowed from Late Middle Chinese 育 yiwk, but that etymology does not explain the initial glottal stop in Tangut.] However, Shi et al. [2000: 123] translated TT0395 as 選種 'selecting seeds'. Tangraphic Sea analyzed TT0395 as
all of SEED + right of DOMESTIC-ANIMAL (something to be raised?)
Neither Shi et al. [1983: 476] nor Nevsky [1960 II: 641] translated TT0395, and Nishida [1966] did not include the tangraph in his dictionary.)
07.2.14.3:15: GLAGOLLOON
This has nothing to do with Tangut, but somethng this bizarre has to be quoted:
In Western Europe, Glagolitic is one of the least known Eastern European alphabets. It also has a particularly exotic appearance to Western eyes, as (unlike Cyrillic or Greek) few of the letters bear any resemblance to Roman letters. It may be for this reason that Glagolitic was selected as the script used by an extraterrestrial species in the 3-D IMAX movie, Alien Adventure. Not only did the aliens write in Glagolitic, but their leader was called "Cyrillus" [after St. Cyrus, one of the creators of Glagolithic]. (However, the alien language was unrelated to Slavonic, as in fact they spoke the Walloon language, a dialect from the production company's homeland, Belgium).
It illustrates how script and language are separate entities. In theory, any language can be written (badly*) in any script:
э.г. дис из ват инглиш вуд лук лайк ин сирилик.
e.g., this is what English would look like in Cyrillic.
恩德迪斯資伊英格利史印斯諾格拉菲。
and this is English in sinography.
(The characters are read in Mandarin as
en-de di-si yi-zi ying-ge-li-shi yin si-nuo-ge-la-fei.)
English could even be written in tangraphy:
TT4354 (a surname) 'yĩ 1.16
(has PERSON on right as semantic element)
TT5687 (a surname) gyii 1.14
(has PERSON on left as semantic element?)
TT4361 長大 GROW UP/MATURE lyi 1.10
(rel. to Old Chinese 大 lats 'large'?; Tangut i can come from earlier a)
TT4594 MESSENGER** shyï 1.29
(has WORDS on left as semantic element plus left of TT0433 TURN/PASS/CHRONICLE dey 1.37 on right)
(I found all four tangraphs in Grinstead's [1972] list of tangraphs used to represent Chinese syllables.)
A Serbian student compared the future fate of Cyrillic in Serbia to Glagolitic:
"If any script is going to die here [in Serbia] it will be Cyrillic, sad but true. The reasons are purely practical. Cyrillic is going to become like the Glagolic script used in Croatia until the XIX Century and now obsolete."
The article ("Dueling Scripts") goes on to say,
The new schooling system is based on learning two foreign languages from the first grade, which will mean that [the] Latin [alphabet] will be widely present in the future.
I assume that English is one of those two languages. Is Russian the other one?
The final paragraph contains a particularly offensive statement:
One well traveled foreigner, Matthew Theisen, recently quipped, “Are they still using Cyrillic or did they switch back to normal?”
He may be "well traveled", but he sounds ethnocentric. Why would Cyrillic be abnormal for Serbia?
*In the sense that not all major phonemic distinctions may be represented unambiguously. This is not necessarily fatal, as readers can 'fill in' what is not written. Fr yxmpl, yw cn rd ths.
**TT4594 shyï 1.29 MESSENGER is probably a loan from Middle Chinese 使 Shïh 'envoy'. (Tangut had no retroflex Sh-, so palatal sh- was the best available approximation of the Chinese initial consonant.)
It so happens that the phonetic element of MC 使 Shïh 'envoy' is MC 史 Shï' 'history', which I used as a phonetic symbol for -sh in my sinographic transcription of the word English. These two words share a root (rə' in Old Chinese; cf. Schuessler 2007: 350):
使 OC s-rə'-s > MC Shïh > Md shi 'envoy'
史 OC s-rə' 'scribe' > MC Shï' >Md shi 'history'
07.2.13.23:59: LIP SOUNDS LIGHT (PART 11)
I left out one more point that I should have made before I reveal my solution:
In part 10, I listed tangraphs from Homophones' Chapter II (labiodentals) that were used to represent northwestern Chinese velar-initial syllables. There is also a tangraph from Chapter VIII ("Gullet Sounds") that was used to transcribe northwestern Chinese labiodental-initial syllables (as well as a velar-initial syllable):
TT5559 PERFUME xyow 1.56 for northwestern Chinese
方 fO?; fang, fã, fÕ in modern dialects (Pearl 34.6)
transcribed in Tibetan before the Tangut period as Hbwang [mbwang], Hpwo [mpwo] (Tibetan has no letter f)
房 (Pearl 34.4; homophonous with 方 except for tone)
向 xyO?; shyang, shyã, shyÕ in modern dialects (Pearl 36.1)
transcribed in Tibetan before the Tangut period as hong, ho (Tibetan has no letter x)
xyow 1.56 appears to be a loan* from Chinese 香 'perfume' which was pronounced something like xyO during the Tangut period (cf. its pre-Tangut period Tibetan transcriptions hong, ho and its Khotanese Brahmi transcription hyuu; it is shyang, shyã, shyÕ in modern dialects).
Its fanqie is
TT5559 xyow 1.56 < TT3371 xu 1.1 + TT4128 lyow 1.56
I wonder if xyow could be reinterpreted as xwyow < xw- + -yow. There is no xwu in Gong's reconstruction. Perhaps xu was [xwu] and was being used as an initial speller for xw-.
(Gong did, however, reconstruct an -u : -wu distinction after other velars [k, kh, ng but not g] in some rhymes. The fanqie for xu is
TT3371 xu 1.1 < TT2184 xyi 1.11 + TT4139 ku 1.1
Since Gong did not reconstruct an -u : -wu distinction after k in rhyme 1.1, perhaps ku 1.1 was [kwu].)
I see three solutions to the Chapter II/VIII crossover problem:
1. The compiler of Homophones placed Chapter VIII tangraphs with x(w)- in Chapter II (listed in Part 10) because he knew they were used to represent Chinese f-initial (i.e., labiodental) syllables. That might have been the case for some of those tangraphs, but others (TT1022, TT2708, TT5299, TT5300) are not attested as Chinese transcription characters.
TT5299 wyï (vyï?; homophonous with xyï in Tangraphic Sea) 1.29 BUDDHA
also used to transcribe Chn 佛 'Buddha' (Pearl 36.3)
may have been a special case with two readings, possibly from different periods:
wyï (vyï?) 1.29? < 佛 NW Late Middle Chinese vur 'Buddha' (< ult. late Old Chinese but)
(Not homophonous with TT5299 xyï 1.29; hence the isolatangraph [no-homophone] status of TT5300 in Homophones)
xwyï? 1.29? < 佛 NW Late Middle Chinese fur, Tangut period NW Chn fu? 'Buddha' (cf. modern dialects: fë, fO, fo, fu)
(The second reading is based on the Tangraphic Sea entry for TT5299 which lists it as a homophone of TT5300 xyï (xwyï?) 1.29 whose fanqie contains TT3371 xu 1.1, a possible initial speller for xw- [see above].)
2. Tangut dialects had w- ~ xw- variation similar to [w] ~ [hw] variation in English. For some English speakers, wear and where are both [wer], but for others they are distinct: [wer] and [hwer]. Speakers of Tangut dialects with xw- used xw-tangraphs to transcribe Chinese f-, whereas speakers of Tangut dialects with w- for those syllables (i.e., the author of Homophones) regarded those tangraphs as labial-initial (or labiodental-initial, if Gong's w- was phonetically [v]).
3. Tangut dialects had f- ~ xw- variation; cf. how Irish Ó Faoláin was Anglicized as both Phelan with [f] and Whelan with [hw] (> [w] for some speakers). Perhaps f- was in the speech of more Sinified Tangut speakers but not in the speech of less Sinified Tangut speakers who substituted xw- for that alien sound. (07.2.14.00:27: Or there could have been native Tangut words with xw- that were pronounced as f- by some speakers: cf. the xw- > f- shift in Cantonese: 火 fo 'fire' corresponding to Md huo [xwo].)
07.2.14.00:23: There are even more possibilities if w were [w] or [v] depending on dialect: e.g., f- ~ v- ~ w- ~ xw- variation! In any case, we cannot assume that there was one uniform pronunciation of Tangut underlying all the native reference works as well as the various transcriptions of Chinese (in the Pearl, the Forest of Classes, and elsewhere) and the Tibetan transcriptions of Tangut.
Next: A f-ew more Tangut transcriptions of Chinese.
*07.2.14.00:39: Native words with similar semantics were TT0700 FRAGRANT lyi 2.9 (Pearl 14.4) and TT0793 INCENSE shya 1.19 (Pearl 21.3, 21.4). Both corresponded to Chinese 香 'perfume, fragrant, incense' in the Pearl.
TT0793 INCENSE shya 1.19 superficially resembles modern northwestern Chn 香 shyã but this is coincidental since the Tangut word predates the shift of xy- > sh- in northern Chinese. One might propose that Tangut shya was from xya, but then one would expect no xya in Tangut (except as archaisms that hadn't undergone the shift or borrowings postdating the shift). However, Gong (1997) reconstructed seven xya and one xyar (< earlier r-xya or xyar?) in Tangut as well as 22 other xy-syllables. There is nothing leading me to believe that xy- > shy- in Tangut, though it could have happened (and if it had, then Tangut xy- must have come from something other than xy-).
07.2.12.23:43: LIP SOUNDS LIGHT (PART 10)
Part 9 may have given you the impression that I've at least attempted to resolve all the issues regarding the initials of Chapter II of Homophones.
As if that were possible!
A new twist awaits us in the last section of Chapter II called
TT0484 LIPS mər 1.84
TT0099 SOUND Giẹ 1.59
TT3590 LIGHT 'yiy 1.36
TT3309 CHARACTER dyi 2.10
TT2507 ONE/ALONE tyịy 1.61
consisting of unique syllables which have no homophones. Unlike Nishida (1966), Sofronov (1968), Li (1986), and Gong (1997) reconstructed several of these tangraphs with velar initials in spite of their inclusion in the labiodental chapter. Some of those tangraphs were used to represent velar fricative-initial Chinese syllables in the Tangut translation of the Forest of Classes (Md 類林 Leilin; Gong 2002: 436-437):
| Homophones | Tangut Telecode | Rhyme | Nishida (1966) | Sofronov (1968) | Li (1986) | Gong (1997) | used to transcribe NW Chinese |
| 11B34 | 2708 | 2.53 | ? (sic) | xwỊ | xyẸ?* | xywị̈y | |
| 11B38 | 1933 | 2.14 | wa | xwa | xaa | xwa | 何 xO? |
| 11B43 | 3016 | 1.10 | wi | xywe | xye | xywi | 非 妃費 fey?, 惠 xwey? |
| 11B47 | 1022 | 1.2 | none | xywu | xyu | xyu | |
| 11B51 | 0822 | 1.16 | fywə̃ | xwên | xyẽ | xywĩ | 汾 fẽ?, 訓 xywẽ? |
| 11B61 | 5300 | 1.29 | none | vye | xïï | xyï | |
| 11B62 | 5299 | 1.29 | none | vye | xïï | wyï |
(The
NW Chn initials are fairly certain, but the exact qualities of the
finals aren't.)
Now look at these fanqie from Tangraphic Sea for of those tangraphs (in Gong's reconstruction):
TT0822 xywĩ 1.16 < TT3552 xu 1.1 + TT1987 kywĩ 1.16
TT5299 xyï 1.29 < TT3371 xu 1.1 + TT0049 shywï 1.29
TT5300 wyï 1.29 < TT3371 xu 1.1 + TT0049 shywï 1.29
The tangraphs representing the initials are from chapter VIII ("Gullet Sounds"), not II ("Light Lip Sounds")!
(The other fanqie for the characters in the table either use those characters as initial spellers or are unknown.)
What is going on here? Why would the author of Homophones mix velars with labiodentals?
Next: My solution. (Don't mail me yours yet. Let's see if we can come up with similar answers independently.)
*Li (1986: 251) actually listed xyOw as the reconstruction, but I suspect this is a mistake for xyẸ since he reconstructed rhyme 2.53 as yẸ on p. 189.
**07.2.13.1:24: Tangraphic Sea has the same fanqie for both TT5299 and TT5300, even though they are listed as non-homophonous 'solitary tangraphs' (solitangraphs?) in Homophones. This implies that they were homophonous in the dialect of the TS author but distinct in the dialect of the Homophones author.
I do not know how Gong determined the difference between TT5299 and TT5300. I don't know of any transcriptional evidence pointing toward w- for TT5299 as opposed to x- for TT5300.
07.2.11.23:23: LIP SOUNDS LIGHT (PART 9)
In part 8, I asked,
If Chapter II [of Homophones] really contained all Tangut syllables with initial Cw-, why were these Cw-syllables scattered among other chapters?
My answer is:
Tangut had two types of syllables:
complex: with a presyllable Cə- (reducible to C- or zero)
simple: no presyllable
(This is like Sagart's [1999] Old Chinese reconstruction.)
Chapter II contained ([Cə]-v-) syllables (i.e., presyllable + v- syllables) which might have been reduced to Cv- syllables in rapid speech.
Cv- syllables without longer presyllable + v-forms were assigned to the class of their C-.
The basic pattern would be:
| Homophones chapter | Tibetan transcription | Initial in Tangut dialect being transcribed | Initial in Homophones dialect |
| II | (C(-))w- | Cə-v- (reducible to Cv-, v-) or v- | (Cə-?)v-, v- |
| Other than II | Cw- | Cv- | Cv- |
If this answer were correct, here's what the various Tibetan initial transcriptions for Chapter II syllables might have represented:
| Tibetan transcription | Initial in Tangut dialect being transcribed | Initial in Homophones dialect |
| w- | v- | v- |
| wh- | ||
| ww- | ||
| bw- | v- or bv- (reduction of bə-v-) | v- (and/or bə-v-?) |
| b-w- | bə-v- | |
| dw- | dv- (reduction of də-v-) | v- (and/or də-v-?) |
| d-w- | də-v- | |
| l-w- | lə-v- and/or də-v- (l and d are phonetically similar) | v- (and/or lə-v- and/or də-v-?) |
| yw- | yv- (reduction of yə-v-?) and/or palatalized allophone vy- of v-? | v- (a palatalized allophone vy- and/or yə-v- , yv-?) |
Notes:
1. Tibetan has no letter for v, so the non-Tibetan letter sequences wh-, ww-, and perhaps also bw- might have represented v-. If the Tangut initial were w, there would be no reason to use these unusual digraphs for w.
2. v- could have had an allophone [w] after a consonant. One could argue that this was the case, since there are no transcriptions of the type Cwh-, Cww-, Cbw- which might imply Cv-. But Tibetan did borrow Sanskrit Cv- clusters as Cw-, so it would be possible for Tibetan -w- to represent a foreign -v-.
3. yw- only occurs in transcriptions for group 4a (9B78-10A24) whose rhymes (1.67, 2.60) were transcribed in Tibetan as -i. Gong reconstructed rhymes 1.67 and 2.60 as -yị with a tense vowel (indicated by a subscript dot). Since group 4a syllables were transcribed as dwi as well as ywi, the members of this group may have been pronounced as (də-)vyyị (The palatalization of v- was probably automatic after the glide y, and will be omitted below.) It is also possible that the transcriber's dialect had several distinct syllables which were merged in the Homophones dialect:
| Homophones group | Rhymes | Transcriptions | Transcriber's dialect | Homophones dialect |
| 4a | 1.67 | dwi, ywi | vyị, d(ə)-vyị, y(ə)-vyị | vyị |
| 2.60 |
A cluster yv- would be like the yw- in Japhug rGyalrong or in Proto-rGyalrong (Jacques 2003: 410).
This proposal still does not solve the following problem: Why are there no instances of g(-)w-, s(-)w-, etc. in the Tibetan transcriptions of chapter II syllables?
Perhaps Tangut had a restricted set of presyllable initials which was much smaller than its set of 'kernel' initials. In my database of Nevsky's (1926) collection of 502 Tibetan transcriptions (which is not identical to Nishida's), the set of possible presyllable initials appears to consists of
g-, d-, b-, m-, r-, s-
and s- only occurs once (in #235 sti; Nishida [1964: 88] lists at least two cases, both within homophone group 59 of chapter IV).
y- occurs only twice before a consonant (w only) in chapter II homophone group 1 (ywi above) and in chapter VIII homophone group 8: ywe, g-yu, yu (Gong's 'yu). The presyllable in the latter case is probably gə-, and y is part of the 'kernel'. The former case is ambiguous - it could have represented y(ə)-vyị, but I favor simply interpreting it as vyị.
I could not find anything in Nishida (1964) suggesting any further initials.
I am assuming that hC and HC-clusters and lth-, ld-, ldth- represented single initials.
The only other l-sequence in the transcriptions is l-w- (implying Tangut lə-v- and/or də-v-). If there were a presyllable lə-, it would occur before initials other than v-, so I am inclined to view l-w- as an attempt to write Tangut də-v-.
The Tangut presyllable initial inventory is nearly identical to Matisoff's (2003: 88) inventory of Proto-Tibeto-Burman (PTB) prefixes, at least in phonetic terms:
g-, d-, b-, m-, r-, s-, a-
(and perhaps l- [Matisoff 2003: 129]; cf the Tangut lə- I proposed above)
Since Matisoff apparently did not take the Tibetan transcriptions of Tangut into consideration, the similarity may be significant if there are semantic matches between the presyllable initials and the PTB prefixes. Unfortunately, the semantics of the Tangut presyllable initials are unknown, and the semantics for the PTB prefixes are diverse, vague, and in some cases simply unknown, though there are a couple of possible matches*.
The set of probable presyllable initials before Tangut v- (or w-) is very small:
d-, b- (no g-, m-, r-, s-, and l- is disputable)
Looking at the transcriptions for chapter VIII syllables (Nishida 1964: 127-129), I noticed that the set of probable presyllable initials before Tangut (')y- has only one member: g-:
g- (in g-yi, g-ye, g-yu)
g- is one of the presyllable initials that does not occur with w-. Conversely, d- and b- are presyllable initials that do occur with w- but not with y- in transcriptions. This complementary distribution may imply some sort of relationship between Tangut v- and y-. This reminds me of w/y relationships in nearby languages: e.g.,
Chinese: 宛 appears as a phonetic in both w- and y-graphs, and has two Mandarin readings wan and yuan (from Old Chinese 'on' and 'on); another example is 尉 Md wei with another reading yu (from Old Chinese 'uts and 'ut)
Written Tibetan y- is cognate to w- elsewhere and may come from earlier w- (Schuessler 2007: 130).
If I posit a generic pre-Tangut glide, perhaps:
gə-GLIDE- > gə-y-
but
də-GLIDE- > də-v-
bə-GLIDE- > bə-v-
Perhaps assimilation and lenition were involved:
gə-GLIDE- > Gə-G- (G = voiced velar fricative) > Gə-y- (> y- in some dialects)
də-GLIDE- > ðə-ð- > ðə-v- (> v- in some dialects)
bə-GLIDE- > Bə-B- > Bə-v- (B = voiced bilabial fricative) (> v- in some dialects)
(23:29: Double fricative stages added for the d- and b- sequences.)
What happened to the presyllables mə-, rə-, sə- (and lə-?) before glides?
mə- may have merged with the glide:
mə-v- > mv- > v-
mə-y- > my- > y-
just as NW Late Middle Chinese mv- > modern NW dialects' w- or v-
and Vietnamese my- > y- (later dy- > and now [z] or [y] depending on dialect, though still spelled d)
rə- may have disappeared before v-, leaving a trace in the rhyme: e.g.,
rə-va > r-var > var
Gong did not reconstruct any rw-clusters (see part 8), so original rw-syllables may be hidden among w + retroflex rhyme syllables.
There are, however, many ry-syllables in Gong's reconstruction, so rə- may have reduced to r- before -y- without disappearing. All these syllables had retroflex rhymes due to autoretroflexion. It is not clear why 'eight' (Proto-Tibeto-Burman ryat [Matisoff 2003: 648]) has initial glottal stop instead of ry- (but see here***).
sə- may have disappeared before v-, but it too may have left a trace in the rhyme: e.g.,
sə-va > s-va > s-vạ > vạ
Gong ("Tangut tense vowels and their origin", examples #111-115) demonstrated a correspondence between Tangut second cycle (subscript dotted; usu. interpreted as 'tense vowel') rhymes and Written Tibetan s-. If this correspondence is non-coincidental, s-prefixes may be one source of second cycle rhymes. (23:27: For counterexamples, see Gong's #116-118.)
Gong reconstructed sw- only before first cycle (non-tense, non-retroflex) rhymes. These sw- may postdate the s- > second cycle shift (SSCS?) and so their rhymes remain in the first cycle.
There are many ry-syllables in Gong's reconstruction, so sə- may have reduced to s- before -y- without disappearing. Some sy-syllables belong to the second cycle and others belong to the first, third (retroflex), and fourth (retroflex?) cycles. Perhaps:
Original sy- > first cycle sy-
sə-y- > s-y- > second cycle sy- (with 'tense vowel' [?] rhymes)
r-s(ə-)y- > third and fourth cycle sy- (with retroflex rhymes)
lə-, if it even existed at all, could have merged with də-.
Next: Velar vexation.
 *Tangut
has its own prefix (not presyllable) 'a- (right) in
the family terms
*Tangut
has its own prefix (not presyllable) 'a- (right) in
the family terms
'a ? pya 2.20 'father'
'a ? mya 2.20 'mother'
'a ? ko 1.49 'elder brother'
'a ? tsya 1.20 'elder sister'
though this may reflect Chinese 阿 a-, as all four (or at least the last two) may be Chinese loanwords: cf. Mandarin
阿 爸 aba [apa] 'father'
阿媽 ama 'mother'
阿哥 age < 'a-ko 'elder brother'
阿姐 ajie < 'a-tsya 'elder sister'
(The rhyme and tone of 'a- are unknown.) Tangut 'a- (and Chinese a-) could also be related to the Tibeto-Burman kinship prefix a- described in Matisoff (2003: 105).
 There is a homophonous native
Tangut prefix 'a- indicating perfective momentary
aspect (Sofronov 1968 I.203) which Nishida (1966: 578) interpreted as
showing "that an action has already taken place, and that,
morever, its condition is still continuing".
This prefix is written with the same tangraph as ONE (right) and might
be derived from ONE ('one' > 'once' > perfective) rather
than
from the Tibeto-Burman aspectual prefix described in Matisoff (2003:
107). (Matisoff did not reconstruct any PTB word for 'one'
like 'a.)
There is a homophonous native
Tangut prefix 'a- indicating perfective momentary
aspect (Sofronov 1968 I.203) which Nishida (1966: 578) interpreted as
showing "that an action has already taken place, and that,
morever, its condition is still continuing".
This prefix is written with the same tangraph as ONE (right) and might
be derived from ONE ('one' > 'once' > perfective) rather
than
from the Tibeto-Burman aspectual prefix described in Matisoff (2003:
107). (Matisoff did not reconstruct any PTB word for 'one'
like 'a.)
The aforementioned family term prefix is written with a combination of PERSON (semantic) and the tangraph for ONE (phonetic).
**English bathe [beyð] has become Hawai'i Pijin [beyf]. A similar shift occurred in Latin:
Proto-Indo-European dh > Latin f
presumably with intermediate steps:
dh > ð > Θ > f
or
dh > ð > v (not to be confused with Latin v = [w]) > f
David Boxenhorn suggested that the dw- transcriptions may have been an attempt to write ð-. ð- would obviously not be a labiodental, but it would correspond to labiodental v- in the Homophones dialect. If so, then maybe the un-Tibetan d-w- spellings do not actually reflect a presyllable + initial combination də-v- but were meant to symbolize 'something like d-' (i.e., ð-).
I cannot, however, think of any other case in which ð- has been equated with dw- in another language. The two patterns I know of are
ð- : d- (Pijin da for Eng the)
ð- : z- (Jpn za for Eng the)
(Then again, Japanese lacks dw-, and it's marginal in Pijin [as in English].)
There is nothing labial about ð-. Before I received David's suggestion, I wondered if d(-)w- stood for Tangut ðB- < earlier db- (a cluster which does exist in Tibetan) with a -B- corresponding to -w- in the transcription.
pə-ryat (?) > 'yar 1.82
if the initial Tangut glottal stop is a remnant of p-.
Cf. Written Tibetan brgyad < earlier b-ryat 'eight' (like me but unlike Matisoff 2003, Schuessler 2007: 152 doesn't view the WT form as from b-r-gyat).




























{kind=link}