07.2.9.23:59: LIP
SOUNDS LIGHT (PART 8)
Clauson's
interpretation of the second chapter of Homophones
(see the end of part 7)
sounded promising at first. It explained the initial variation among
transcriptions of members of 'homophone' groups: e.g. (using
Nishida's [1964: 82-83] numbering of the groups):
4a: dwi,
ywi
17: dwï,
bwi
21: l-wi, b-wi
27: dwi,
wwi, bwe
What mattered
in, say, group 21, was not l- or b-,
but the shared wi - the 'kernel', as David Boxenhorn
would call it.
There are two problems with Clauson's
hypothesis.
First, why are the only complex
transcribed initials b(-)w-, d(-)w-, l-w-, and yw-?
Why are there no instances of other initials like m(-)w-,
n(-)w-, (d)z(-)w-, j(-)w-, g(-)w-, or ng(-)w-
(assuming that only letters for voiced consonants could
precede w in the transcriptions)?
Why are there no combinations of voiceless initials followed
by -w-: p(h)(-)w-, t(h)(-)w-, (t)s(h)(-)w-, ch(h)-,
k(h)-? (The transcription wh-
could have represented [hw] or [xw].) Middle Chinese,
Tibetan, and more relevantly, Tangut's close relatives Mawo Qiang (Sun
1981) and rGyalrong (Jacques 2003)
all permit many consonants to combine with -w-
(examples added 07.2.10.1:44):
Middle
Chinese w-clusters:
| Dentals | Alveolars | Retroflexes
1 | Retroflexes 2 | Palatals | Velars | Glottals |
| tw- | tsw- | Tw- | Chw- | chw- | kw- | 'w- |
| thw- | tshw- | Thw- | Chhw- | chhw- | khw- | |
| dw- | dzw- | Dw- | Jw- | jw- | gw- | |
| nw- | | | | ñw- | ngw- | |
| sw- | | Shw- | shw- | xw- | |
| zw- | | | zhw- | Gw- | |
| lw- | | | | yw- | | |
(-w-
could be preceded by any MC initials except for labials and the rare
initials N- [retroflex n] and Zh-
[retroflex zh]. It is not clear whether
MC labials were followed by -w- or not. If there
was a -w- after labials, it was nonphonemic.)
Written
Tibetan w-clusters (Jacques 2003: 95-96 or this PDF;
excluding marginal clusters):
| Dentals | Alveolars | Palatals | Velars | Glottals |
| rtsw-
(but not tsw-!) | | | |
| tshw- | | khw- | |
| dw- | | | g(r)w- | |
| | ñw- | | |
| | shw- | | hw- |
| | zhw- | | |
| lw-,
rw- | | | | |
(Once
again, there are no labial-w clusters.)
Mawo
Qiang w-clusters (Sun 1981: 34-35):
| Labials | Dentals/Alveolars | Postalveolars | Retroflexes | Velars | Uvulars |
| tw- | (x)chw- | xChw-
(but not Chw-) | | qw- |
| | | GJw-
(but not Jw-) | | |
| mw- | nw- | | | ngw- | |
| sw- | | Shw- | | |
| (G,
R)zw- | | Zhw- | | |
| lw-,
rw- | | | | |
Japhug
rGyalrong w-clusters (Jacques 2003: 58, 62-63):
| Dentals/Alveolars | Palatals | Velars | Uvulars |
| | kw- | shqw- |
| | khw- | |
| | | Xw- |
| zw- | | | |
| lw-,
rw- | yw- | | |
Zbu
rGyalrong also has qw-, qhw- (2003: 309).
Proto-rGyalrong had even more clusters:
tw-,
thw-, (t)sw-, ndzw-, kw-, (ng)gw- but no labial-w
clusters (2003: 331-332).
Tangut
did not have to follow this trend, but the
limited number of possible w-sequences in
transcriptions for tangraphs within this chapter hints at another
explanation.
Second, Tangut apparently did
have other consonant-w clusters after all, but they
were assigned to other chapters of Homophones. Here
are the other complex-w- initial Tibetan
transcriptions I found in Nishida (1964):
Chapter
I. Labials: none
Chapter III. Dentals: Hdwi,
btwi
Chapter
IV. Retroflexes: none
Chapter V. Velars: rngwa,
bkhwe, rngwi
Chapter
VI. Alveolars: bswoH, Hdzwu, Hdzwui (sic), tshwi
Chapter
VII. Palatals: none
Chapter VIII. Laryngeals: ywe,
Hrgwe, d-wir, d-woH
Chapter IX. Liquids:
none
(Gong reconstructs Cw-
clusters for syllables found
throughout Homophones*,
but it would be circular to cite his reconstruction as evidence.)
If
Chapter II really contained all Tangut syllables with initial Cw-,
why were these Cw-syllables scattered among other
chapters?
Next: My answer to that question.
*07.2.10.2:02: Guillaume Jacques'
alphabetical index to Gong's (1997) reconstructions contains the
following w-clusters:
| Labials | Dentals | Alveolars | Palatals | Velars | Glottals |
| pyw-
(but not pw-) | t(y)w- | ts(y)w- | chyw- | k(y)w | '(y)w- |
| th(y)w- | tsh(y)w- | chhyw- | kh(y)w | |
| d(y)w- | dz(y)w- | jyw- | gyw-
(but not gw-) | |
| n(y)w- | | | ng(y)w- | |
| | s(y)w- | shyw- | x(y)w- | |
| | z(y)w- | zhyw- | G(y)w- | |
| l(y)w- | | yw- | | |
| lh(y)w- | | | | |
The
only Tangut initials that did not precede -w- in
Gong's reconstruction were all labials except p- (ph-,
b-, m-, w-) and r-. Perhaps
pre-Tangut rw- > Tangut w-
(cf. the Elmer Fudd pronunciation of rabbbit as wabbit).
07.2.8.23:54: CHINESE
EYES AND EARS (what does
this refer to?*)
Yes, I can still write
about topics other than Tangut. It's just that I only have so much time
to post, and I have to be selective.
A few parts of this
article about Chinese calligraphy got to me (emphasis mine).
Today
there are still professional calligrapher artists and it is a very
popular amateur pastime. Maybe its popularity has something to do with
the palaver that Chinese speakers need to go through to use a computer.
They have to spell out what they want to say phonetically, using the
Roman alphabet keyboard and a programme that will translate that into
Chinese characters. Even then Chinese is so sensitive to tone
that a choice of four translations may be offered.
It looks like the reporter heard that 'Chinese' (actually, Mandarin)
has four tones and concluded that there is one character per
syllable/tone combination: e.g., if I type "shi", I get four choices,
each with a different tone (that I indicate with a number):
shi1
失 'lose'
shi2 十 'ten'
shi3
使 'send / use / cause'
shi4 市
'city'
But in fact I have many
more choices. Even if I specify, for example, shi
with tone 1 only, here's what I get using Windows XP's Chinese (Taiwan)
input method:
失施師詩濕溼獅屍蝨噓虱尸蓍葹鳲邿湤絁鰤溮鶳箷褷襹螄瑡籭蒒釶
鍦褜魳鯴
(33 non-simplified characters)
师湿狮诗酾鲺鳁 (7 simplified characters)
plus
the phonetic symbol ㄕ
for sh- (doubling as the symbol for the syllable shi;
cf. 尸 shi 'corpse' above)
Now
let me drag Tangut into this. (It's inevitable!) If
there were a phonetic Tangut input method, I could type in we2
(we with tone 2 = rising tone) and get 18 choices
(from the first
homophone group of the labiodental chapter of Homophones)
including










TT3901 TEACH
TT0645
CITY
TT0624 FIFTH HEAVENLY-STEM (see the full list here)
TT5661
PERSONAL-SIGN (looks like WAIST
jyiw 1.45 [!?] plus the previous homophonous
tangraph as phonetic)
TT0631 KUMISS (phonetic 干丨? +
WATER)
TT0627 SLAVE (phonetic 干丨? + the phonetic
element ya [!?])
(Are 干 and 干丨 always phonetic symbols?**)
TT3213
(kind of grass; GRASS + what looks like the left of SLAVE above)
TT5286
CLIFF (BORDER + HIGH)
TT4029 DONKEY
(read on)
TT4527 SOIL, etc.
Not
specifying the
tone (1 or
2) would result in 31 different choices (18 we2
tangraphs + 13 we1 tangraphs).
In
everyday Chinese life a vocabulary of 3,000 characters will be enough
to get by, but calligraphers call on up to 50,000 in a
selection of scripts such as seal, official, running, regular and mad.
I
wouldn't call 3,000 characters "a vocabulary"
because that implies that characters equal words, whereas the reality
is that many, if not most characters only represent parts
of words. In everyday Chinese life, people use more than
3,000 words, but they can write nearly all of those words with only
3,000 characters.
I'm not sure whether the 50,000
figure includes different versions of a character in different
calligraphic styles (as if one counted print and cursive a
as two 'different' letters) or is one of those attempts to enumerate
all the Chinese characters that ever were, regardless of calligraphic
style.
He showed me 40
versions of the character for donkey, with its circular
component
referring to the millstone powered by a donkey in Ancient
China.
I
have no idea what this is talking about. Here are the complex
and simplified versions of 'donkey':
驢 驴
Neither
version contains any "circular component referring to [a]
millstone".
Both versions have the semantic
component 'horse' on the left (complex: 馬, simplified: 马).
The
complex version contains the phonetic component 盧 'food vessel' (mostly
used to write a homophonous surname). In late Old Chinese,
the surname 盧 la and 驢 lïa
'donkey' were nearly homophonous. (驢 is not attested in early
Old Chinese.) They are still similar in Mandarin today: the
surname 盧 is Lu and 驢
'donkey' is lü.
The
simplified version reduces the phonetic component 盧 to 戶 which looks
like the character 戶 for the unrelated word Md hu
'door' and vaguely resembles 石 Md shi 'stone'.
Maybe the reporter heard that 戶 'door'
resembled 石 'stone' and thought that 驴 'donkey' actually
contained 石 'stone'.
None of the eight
versions of 'donkey' at the Taiwanese goverment dictionary of
sinographic variation contain 石 'stone'.
The
Tangut word for 'donkey' was

TT3585
+ TT3561
lyị̈2we2
Its
tangraphs contained nothing that implied 'donkey':
Tangraph
1:
left: unknown element (Nishida's
radical 276) resembling PERSON:
Nishida's
(1966: 492) list of tangraphs with this element
includes FIGHT, HARM, the surname khyiy
1.36 (see below), HOWEVER, OLD, HOLD/HIDE, AGAIN,
DWELL, a place name thəw (Grinstead:
BUT/ALTHOUGH, Gong: dyiy 2.33), ABOLISH, MUSTARD,
CONQUER (Grinstead: TURKS [!?]), CONQUER
right: TT1730 tsyï
ALSO 1.30 (click
here to see it) which almost rhymed with TT3585 lyị̈2
2.61
Tangraph
2 (from the first homophone group in the labiodental chapter of Homophones):
left:
non-independent element EARTH
right: non-homophonous
(!) surname khyiy 1.36 (containing the same left
element as tangraph 1 above; click
here to see it)
The
first half of the word lyị̈2we2
'donkey' resembles 驢 Early Middle Chinese lïə,
Late Middle Chinese lüö,
and probable Tangut period NW Chn lü
'donkey', so it could be a Chinese borrowing. The
trouble is ... the tangraph (composed of plus could also mean
'hare', so it did double duty for a Chinese loan and a homophonous
native word for a different animal.
The second half
of the word is obscure. Perhaps the word lyï1we2
'donkey'is a redundant compound combining Chinese and native words for
'donkey'.
*Korean
唐나귀 tangnagwi
'donkey' sounds vaguely like English donkey.
The 唐 Tang refers to China's Tang
dynasty but in this context probably just means 'Chinese'. 나귀
nagwi is a native word for 'donkey'.
So 唐나귀 tangnagwi is literally
'Chinese donkey'.
"Eyes" refers to 나 na
which sounds like Korean 나 na 'I'.
(The Korean word for 'eye' is 눈 nun
which sounds like 'noon' - and looks like Korean 눈 nuun
'snow' which has a long vowel not indicated in the spelling.)
"Ears"
refers to 귀 -gwi which sounds like Korean
귀 kwi 'ear'. (Korean k
becomes g after a vowel: na
+ kwi = nagwi.
This change is not reflected in spelling: ㄱ can stand
for k or g
depending on its environment.
**07.2.9.2:30:
Sofronov (1968 II.292-293) has a list of 45 tangraphs
with 干(丨)
on the left. Here is how they are distributed among the
chapters of Homophones:
| Chapter
of Homophones | tangraphs
w/干 on left | tangraphs w/干丨on left |
| I
(labials) | 6: 0633,
0640, 0643, 0646, 0647, 0663 | 0 |
| II
(labiodentals) | 2: 0645, 0662 | 3:
0624, 0627, 0631 |
| III
(dentals) | 6: 0641, 0642, 0651,
0653, 0655, 0656 | 2: 0625, 0629 |
| IV
(retroflexes) | (no
examples; this chapter only has 20 tangraphs) |
| V
(velars) | 12: 0619, 0621, 0622,
0623, 0632, 0634, 0635, 0636, 0637, 0650, 0652, 0657 | 0 |
| VI
(alveolars) | 3:
0658, 0659, 0660 | 1: 0626 |
| VII
(palatals) | 1: 0620 | 1:
0628 |
| VIII
(laryngeals) | 4: 0638, 0649,
0654, 0661 | 1: 0630 |
| IX
(liquids) | 3: 0639, 0644, 0648 | 0 |
Their
rhymes are also all over the map:
1.16,
1.20, 1.29, 1.32, 1.36, 1.47, 1.49, 1.56, 1.57, 1.69, 1.74, 1.77, 1.80,
1.92
2.3, 2.4, 2.7, 2.23, 2.25, 2.28, 2.33,
2.40, 2.55, 2.73, 2.78
And they
have no unifying semantic link: e.g., what do the 干-graphs
above (CITY, FIFTH-HEAVENLY-STEM, KUMISS, SLAVE) have in common with
TT0640
po 1.49 HOE
TT0642 nyiy
2.33 WIND
TT0643 pyịy 2.55 SCOOP
TT0647
pya 1.20 BUTTERFLY
TT0648
rerw 2.78 REPENT
TT0651
nywiy 1.36 GULLET
TT0653 dyï
2.28 WITH (cognate to COMBINE below?)
TT0655 dyï
2.28
PROTECT
TT0656 thywï
2.28
COMBINE (cognate to WITH above?)
TT0659 syu
2.3 LIKE, etc.
(I
have cited every tangraph between 0640-0663 which Grinstead has glossed
other than TT0645 we 2.7
CITY which I've already mentioned.)
Thus 干(丨) has no
consistent semantic or phonetic value (from a Tangut A perspective).
***07.2.9.2:44: Schuessler (2006: 367)
reconstructs
驢 'donkey' in Old Chinese as ra. Although the graph
is not attested in earlier OC,
Unger
(Hao-ku 13, 1989) points out that the donkey must have been
known in China before its first mention during the Han dynasty because
'mule' [Md] luó 騾 ... occurs already in
[the pre-Han text] Lüshi chunqiu [Wikipedia].
騾
would be early OC roy
'mule' in my reconstruction, which would be hard to relate to a
hypothetical early OC 驢 ra
'donkey'. They have nothing in common beyond initial r-.
I don't know of any other OC word families with -oy
and -a words.
07.2.7.4:29: LIP
SOUNDS LIGHT (PART 7)
I've been thinking of
making a few minor changes to Gong's Tangut reconstruction (just as
Gong himself started tinkering with Sofronov's reconstruction before
releasing his own state-of-the-art reconstruction). Here's
one of those changes:
Like Li Fanwen before him, Gong
reconstructed only a single bilabial (not labiodental!) initial w-
for the syllables in the second chapter of Homophones.
I found this w- difficult to reconcile with the
Chinese and Tibetan transcription evidence:
-
Why would Tangut w- be transcribed with an f-initial
sinograph (口縛)? The diacritic suggests
that the sinograph was not supposed to be read with initial f-
(though Nishida reconstructed Tangut f- partly on
the basis of this transcription).
- Why would Tangut w-
be transcribed with wh-, ww-, bw- as well
as w-? wh- suggests a sound that
is w-like but is a fricative like h-.
ww- and bw- suggest a
sound that has more friction than the glide w-.
(The
use of chapter II tangraphs to transcribe Sanskrit v-syllables
does not tell us anything, since a language without a v-
could approximate Sanskrit v- with w-.
Written Tibetan, Thai, and Burmese use w-
for Indic v-.)
(Moreover,
the title of the chapter
is not necessarily meaningful. If the Tangut lacked f-
and v-, they could have placed their
native w- into the 'labiodental' category
in order to preserve the Chinese initial categories as closely as
possible.)
I concluded that
Gong's w- may have actually been a fricative v-.
Written Tibetan has no letter v,
so wh-, ww-, and bw-
may have been attempts to write a Tangut v-.
But
what about b-w-, d-w-, dw-, l-w-, and yw-?
Why would those Tibetan letter sequences be used to transcribe Tangut v-
(or w-)?
In 1964, Sir Gerard
Clauson wrote (p. 62; emphasis mine),
The
only native Tangut sound which can reasonably be brought within the
scope of Chapter II of the Homophones, with its
seventy-eight different word forms [= syllables which may or
may not have been independent words], is the bilabial
w. In [Classical] Tibetan less
than half a dozen words begin with this sound [there are more
now due to loanwords], but this initial was commoner in Nam
(see Thomas, op. cit.*)
and may have been fairly common in Tangut. Some of
the seventy-eight word forms, but perhaps not very many, no doubt
represent Chinese loan words, names, etc. with initial
f-. The only obviously possible explanation of the
remainder is that in Tangut medial
w was regarded as the principal sound in
an initial consonant cluster of which it was the second member and that
words containing it were included in this chapter.
This would of course be different from the practice in Tibetan where
medial -w- is represented by a subscript and the
consonant to which it is attached is regarded as the initial.
Next:
The consequences of Clauson's solution.
*Thomas, FW. 1948. Nam,
an Ancient Language of the Sino-Tibetan Borderland.
Publications of the Philological Society 14. London: Oxford
University Press. I would love to see this book because
Clauson (1964: 73) suggested that Nam might be "pre-1038
Tangut" (i.e., Tangut before tangraphy):
...
since the interpretation of these documents [in Nam and other
lost, 'unknown' languages] is at present no more than an
exercise in more or less inspired guessing, a great deal more progress
will have to be made with the reconstruction of the meanings [of
the words in those documents?] as well as the sounds of
Tangut words before any such identification becomes
plausible. This, however, can be said, that the phonetic
structures of Nam and of the language represented by the long text in
British Museum MS.Or. 8212 (188) are very much like what the phonetic
structure of [earlier] Tangut is likely to prove to
have been, with a considerable apparatus of initial and final
consonantal clusters and, at any rate prima facie, a fairly limited
stock of vowels [an artifact of an Indic writing
system?]
07.2.6.2:57: LIP
SOUNDS LIGHT (PART 6)
The most notable
thing about the transcription
data for labiodental homophone group 1 is the presence of
initial d- in the Tibetan material: dwi,
dwiH. The initial cluster dw-
is rare in Written Tibetan and as far as I know only occurs in
three syllables: dwa, dwags, dwang. Therefore I
don't believe that
-
there was a Tibetan syllable spelled dwi but
pronounced [wi]
- and that Tangut we
(or wI or vI) was transcribed
as Tibetan dwi [wi]
Is
there any Tibetan dialect today in which the written cluster dw-
is pronounced as [w]: i.e., a dialect in which d-
in dwa, etc. is as silent as the k-
in Eng knee?
In Goldstein's
(2001: 547-548) dictionary of modern standard (i.e., Lhasa) Tibetan, dw-
is pronounced as [t], not [w].
dw-
is not the only Tibetan cluster that appears in the transcriptions of
Tangut syllables in the labiodental chapter of Homophones.
Here is a complete list of all initial transcription data in
Nishida (1964: 82-83), organized by Nishida's reconstructed initials:
| Nishida's
(1964) reconstructed Tangut initials | Li (1986) and
Gong's (1997) reconstructed Tangut initial | Chinese
transcription initials (in their
pre-Tangut
pronunciation) | Tibetan transcription initials | Sanskrit
transcription initial |
| f- | w- | fH-
(口縛) | d-w- | (not used to transcribe
Sanskrit) |
| v- | nggw- | dw-,
d-w-, b-w-*, wh-, ww- | v-
(Sanskrit has no f-,
Mv-, or w-) |
| Mv-
(labiodental nasal-fricative cluster) | mbv-,
nggw-, 'w- | dw-, bw-, b-w-, l-w-,
w- |
| w- | w-,
yw-, 'w- | dw-, w-, ww-, yw- |
The
Chinese transcription initials are from pre-Tangut
northwestern Middle Chinese: e.g., PTNWMC nggw-, mv-, 'w-, yw-
may have simply been w- or v-
in Tangut-period NW Chinese. I believe that all of the Chinese
transcription initials are now w-
or v- in modern NW Chinese dialects (with
the exception of fH- which has simplified
to f-).
bw-
does not occur in Written Tibetan to the best of my knowledge.
d-w-,
b-w-, l-w- represent the un-Tibetan letter sequences
da-wa-, ba-wa-, la-wa- without any subscripts (or
syllabic division-indicating tsheg dots) rather
than as dw-, bw-, lw- (da, ba, la
plus subscript w). (The syllable sequences da.wa.,
ba.wa., and la.wa. would be divided
by tsheg dots.)
Did
Tibetans really hear w- (and perhaps also f-,
v-, Mv-) and write it (them?) as d(-)w-,
b(-)w-, l-w- with non-labial initial letters?
Next:
Clauson's solution.
07.2.5.3:06: LIP
SOUNDS LIGHT (PART 5): INTERLUDE
I
don't have time to do a full post tonight, so I'll just post a couple
of notes:
First, I left out one type of main
tangraph-clarifier pattern which Nishida (1964: 21) noted.
I'll call this the
TER
lude in
type
since the main tangraph represents the second syllable of a trisyllabic
word: e.g., Homophones
entry
24B78
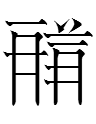


jywiy2khwə1naa2
translated
as 半春菜 'half spring
vegetable' in the Pearl. The tangraphs are read in
the sequence
2
khwə1
3
1
naa2 jywiy2
i.e.,
from the bottom right to the top center and then down to the bottom
left.
Second,
I asked whether the syllables in
group 1 of Homophones' labiodental chapter could be
reconstructed as vI (Nishida 1964: 85).
Sofronov,
Li Fanwen, and Gong Hwang-cherng's answer would be 'no'.
Here's how they reconstructed the pronunciation of
TT3901 TEACH 2.7
the
first tangraph in group 1. Everyone agrees on the rhyme
(rising tone, rhyme 7) but only Sofronov and Gong's reconstructions are
identical:
Scholar | Reconstruction
of TT3901 TEACH | Rhyme |
Nishida
(1964: 85) | vI | 2.7 |
Sofronov
(1968 II: 363) | we |
Li
Fanwen (1986: 240*) | wI |
Gong
Hwang-cherng (1997) | we |
Note
that Li Fanwen has abandoned his 1986 reconstruction in favor of
Gong's. I cite it to show the diversity of existing reconstructions.
Li
Fanwen reconstructed all the other syllables in group
1 as (near-)homophones of TEACH. (Recall that some
of them had the level tone instead of the rising tone. He
reconstructed those syllables as wI 1.8
with the same segments w and I.)
Similarly, Nishida reconstructed all group 1 syllables as
either vI 2.7 or vI
1.8. I assume that Sofronov and Gong also reconstructed
identical readings (except for tone) in this group. (I don't
have time to check 58 [< 29 x 2] readings tonight. Li
and Nishida's reconstructions can be easily accessed at a glance,
whereas Sofronov's and Gong's are scattered.)
Which
reconstruction, if any, is correct? Here's the foreign transcription
evidence that Nishida collected for group 1:
Chinese
transcriptions: o嵬, 外
Tibetan
transcriptions: dwi, dwiH, whï
Sanskrit
transcription value: none known
Unfortunately,
Nishida did not specify which transcriptions were used for which
tangraph (probably due to a lack of space).
Notes:
-
the only evidence we have for Tangut-period northwestern Chinese is in
Tangut, so we risk circularity by citing reconstructions and must turn
to non-Tangut based sources: i.e., pre-Tangut and post-Tangut Chinese
dialects of the region
-
in northwestern Late Middle Chinese prior to the Tangut period, 嵬 (no
circle) and 外 were nggwi and nggwai
(the sources of Sino-Japanese nggwi, nggwai
> modern gi and gai) but
in modern northwestern dialects, 外 is wE
or vE (Coblin 1994: 186) and 嵬 is probably
something like wey or vey,
judging from its near-homophone 危 (Coblin 1994: 216)
-
pre-Tangut Tibetan transcriptions of 外 (Hgwe
[nggwe?], gwe) imply that -ai
had monophthongized to -E (Coblin
reconstructed -Ei) even before the rise of the
Tangut; the alternate transcription HgoHi
[nggoy?] implies a different shift of wa
> o: nggway > nggoy
-
it's not clear to me when the -i of 嵬
broke to -ey; maybe it occurred during/by the
Tangut period, explaining why o嵬 (-ey?)
and 外
(-E[y]?) were used to transcribe the same Tangut
rhyme (2.7; rhyme 1.8 tangraphs were only transcribed with o嵬)
-
the function of the
superscript circle in o嵬 is uncertain;
presumably it means 'pronounce like 嵬, but not quite like 嵬'
-
wh- is not a normal Tibetan initial cluster
-
the sound value of the letter transcribed as ï
(gi-gu inversé; gi-gu phyir-log) is uncertain.
So
how do you think group 1 was pronounced?
Next:
What about the other labiodental groups?
*Li
Fanwen reconstructs rhyme 2.7
elsewhere in his study of Homophones as -IUI
(1986: 188). I don't know why he didn't reconstruct TEACH and
its (near-)homophones as wIUI. Perhaps he
thought the rhyme -IUI was simplified to -I
after w.
[07.2.7.3:57: I misread
Li. I think -IUI is really -I
-UI - the rhyme without and with a preceding medial -U-.]
Strangely,
there is no
rhyme with simple -i in Li's rhyme table (1986:
188-89), though he did reconstruct long -ii for
rhymes 1.30 and 2.28 (equivalent to Nishida's -ïH,
Sofronov's -I, and Gong's -yï).
07.2.4.5:11: LIP
SOUNDS LIGHT (PART 4)
When I color-coded the first
page of the labiodental section of Homophones
in part 3, I
regretted not color-coding the clarifier
characters written beneath the main characters. The
color-coded graphic erroneously indicates that the syllables
represented by the main characters and their clarifiers had the same
tones. This is not always the case. For example, the syllable
represented by the first labiodental tangraph in group 1 (09B21)
had a rising tone but one of its clarifiers had a level tone:


Main tangraph: TT3901 教 TEACH we
2.7
Clarifier 1 (bottom right): TT3924 教 TEACH tshow
1.54 (1 = level tone, not 2 = rising tone; should have been marked with
grey)
Clarifier
2 (bottom left): TT3589 指數 INDEX? lyïy 2.37
(In
Li Fanwen [1986: 672], the second clarifier is miswritten as

TT3584 SMALL tsəy
1.40.)
All three tangraphs put
together represent a trisyllabic word we2tshow1lyïy2
'instruct'.
If English were written in tangraphy, the
character for the syllable in- of instruction
would be found in the glottal section (since it has initial glottal
stop) with clarifiers for -struc- and -tion
(read from right to left):
IN
TION STRUC
Most
main tangraphs have only one clarifier. This clarifier can
either be on the bottom left or the bottom right. Its
position indicates whether the clarifier is to be read before or after
the main tangraph:
CLARIFIER ON BOTTOM RIGHT: the
second labiodental tangraph in group 1 (09B22):
_____
Main
tangraph: TT0645 城 CITY we 2.7
Clarifier:
TT4793 牆 WALL dzywï 1.69
These
two tangraphs form the word dzywï1we2
城壁 'city wall', 城堡 'castle'. The clarifier is read before
the main tangraph above it.
(The
translations are Li Fanwen's [1986: 240]. I was initially inclined to
translate it as 'walled city', since Tangut noun1-noun2 sequences are
modifier-modified sequences: 'wall' describes the 'city', just as
'dharma' in


tsyiir1baar1
法鼓 'dharma drum' [Pearl 212]
specifies
the type of drum [Nishida 1966: 266, 568]. However, perhaps
this is a noun-adjective sequence: Tangut 'wall city' = Eng 'urban
wall'.)
CLARIFIER ON BOTTOM LEFT: the first
labiodental tangraph in group 2 (09B22):


Main
tangraph: TT2393 塞 BLOCK we 1.8
Clarifier:
TT2699 滿 FULL sə 1.27
These
two tangraphs form the word (phrase?) 塞滿 we1
sə1 'be
fully stuffed'. The clarifier is read after
the main tangraph above it.
Not all clarifiers form
words or phrases with the head tangraph. Some are explanatory
notes: e.g.,



Main tangraph: TT4962 we
2.7 (a surname)
Clarifier 1 (bottom right): TT0029 myïr
1.86 (< earlier r-myï? cf.
rGyalrong tU rme 'person' [Jacques 2003: 13],
Written Tibetan mi 'person')
Clarifier
2 (bottom left): TT3890 SURNAME/CLAN mə 2.25
Li
Fanwen (1986: 241) translated the clarifiers myïr1mə2
(lit. 'person-surname') as a word meaning 族姓 'clan surname'. There is
no trisyllabic word we2myïr1mə2
- the sequence is to be interpreted as
WE
NAME SUR
i.e.,
as 'We - a surname'.
Nishida
(1966: 21) lists other two-tangraph clarifier sequences which do not
form words with the main tangraph: 'personal name', 'place name',
'Sanskrit', 助語 'help word' (i.e., a grammatical morpheme), 'mantra',
and the puzzling (to me)

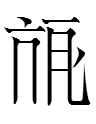
NOT GO
There
are also two-clarifier sequences that serve as phonetic-graphic fanqie
explanations: e.g.,
initial of
clarifier 1 + rhyme of clarifier 2 = reading of main tangraph
part
of clarifier 1 + part of clarifier 2 = main tangraph



thya 2.17 =
th(yi 1.11) + ya 2.17
Main
tangraph: TT0504 thya 2.17 (phonetic symbol for Skt
tya [sic!; for thya?; Grinstead
1972: 196]; 反 MOUTH + phonetic symbol ya; similar
to many phonetic symbol sinographs which consist of 口 mouth + phonetic:
e.g., 咖啡 Md kafei 'coffee' ['mouth' is arguably
even semantic in that case])
Clarifier 1 (bottom
right): TT0510 DRINK thyi 1.11 (反 MOUTH is
semantic; according to Tangraphic Sea, the right
side is from the slightly different-looking bottom left of

TT1941 尋找 SEARCH bẹ
2.58! [!? why not, say, LIQUID?])
Clarifier
2 (bottom left): TT2156 ya 2.17 (phonetic symbol;
cf. Chn 羊 [pron. yang in Md])
To
review the different types of clarifiers, here's what the [fi] group in
an English version of Homophones might look like:
FEA
ble si
PHOE
nix
FY
__taf
FEE
name
sur
(OK, it's actually an
Irish surname, but it has been Anglicized.)
The
syllable fi in a foreign name (Mufi
comes to mind) might be written as a fanqie
character to visually distinguish it from [fi] in foreign words.
I
selected [fi] for my example because Nishida (1966: 85) reconstructed
the syllables of Homophones labiodental group 1 as vI,
and I can't think of many English words with [vI]: e.g., video
[vIdiow]. Moreover, [vI] ends in [I] which cannot appear at
the end of an English monosyllabic word, and I wanted a monosyllabic
example (which ended up being the surname Fee
above).
Next: Was group 1 really vI?
Copyright
2002-2007 Amritavision{kind=link}
{kind=link}
{kind=link}
{kind=link}