

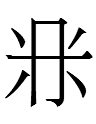
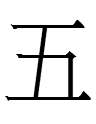

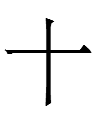
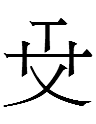
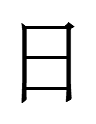
? qulugh ai tau sair par ish nyair
'white rat year, five month, ten nine day'
20.7.9.23:54: WHITE RAT 5.19
? qulugh ai tau sair par ish nyair
'white rat year, five month, ten nine day'
1. Last night I couldn't post on time because my battery was out of
power and I couldn't recharge. That turns out to have been for the best
since I was able to enlarge the post tonight.
What would the Tangut call a battery? I'm guessing they would borrow the Chinese word 電池 'lightning pond' for 'battery' (itself a borrowing from Japanese) in one of three ways:
1. via direct phonetic borrowing from Mandarin (either standard diànchí or its local equivalent)
2. via conversion into 'Sino-Tangut': the conventional Tangutization of early 2nd millennium Xia Chinese: e.g.,
𗽞𗳶
3666 1456 1then4 1chhi2
a phonetic approximation of Xia Chinese *3then4 'lightning'
and *1chhi3 'pond'.
3. via a calque such as
𗬔𗒈
3665 4707 1lhaq 2jen2 'lightning pond'
which contains the word for 'pond' I wrote about last night.
2. The word featured in this week's Star-Advertiser Japan section is リア充 riajū 'people leading a full life' which is in Windows 10's IME. It's in the English Wiktionary but not the Japanese Wiktionary. The word does, however, have its own Japanese Wikipedia article. The newspaper's definition which I give above doesn't make clear that 'full' means 'in real life'. riajū is an abbreviation of リアル riaru 'real (life)' and 充実 jūjitsu 'fullness'. riajū fits the frequent four-mora formula for Japanese abbrevations. (jū is one syllable but has two moras.)
20.7.8.23:59: WHITE RAT 5.18
? qulugh ai tau sair par nyêm nyair
'white rat year, five month, ten eight day'
I did something unprecedented. I did almost none of my language exercises on Sunday due to an emergency. And I did none on Monday and Tuesday because of my extracted tooth. I wasn't supposed to lie down after the surgery, and I handwrite lying down. I don't have a desk with a chair. So I slept sitting up for two nights in a row and neglected my languages. Today I did nearly four times the usual amount of exercises. I would do even more if I didn't have other things to do.
The Tangut exercises for today included part of the Tangut law code
(3.4.2. punishment for salt crimes). What leapt out at me was character
4707
𗒈
for 2jen2 'pool, pond'.
The Tangut script is supposed to be full of semantic compounds. In theory that should make the script easy to learn. All words in the same semantic field should be written with a common component. And the components of each character should play a part in a neat mnemonic 'story'. But that bears little resemblance to reality.
Here's the 'story' of 4707 according to the Tangraphic Sea:
𗒈=𗓰+𘌩
4707 2jen2 'pool, pond' =
top of 4693 1na1 'deep' (i.e., the grapheme of unknown function which I call the 'horned hat': 𘡊) +
all of 5088 1chhwi3 'salt'
'Deep salt'? That's not what first comes to mind when I think of
pools or ponds. Neither 1na1 nor 1chhwi3 sound like 2jen2,
so 'deep' and 'salt' cannot be phonetic.
What surprises me even more is the absence of the semantic element 𘠣 'water' derived from Chinese 氵 'water'. Compare 4707 with the Chinese character for its Chinese equivalent, 池 <WATER.也>, a transparent semantophonetic compound. (也 is phonetic.)
Conversely, 'water' turns up in Tangut characters for morphemes that have no obvious or inherent connection to water: e.g.,
the demonstrative 𗋕 2019 1tha4
7.9.22:45: then again, Chinese 汝 'thou' also has 氵 <WATER>, but that's because 汝 originally represented the name of a river and was repurposed to represent a homophonous pronoun
the perfective prefix 𗋚 2590 2vy3-
7.9.22:49: the Tangraphic Sea derives the left side of the demonstrative 𗋕 2019 1tha4 from 2590 which makes no semantic or phonetic sense
7.9.23:01: Did the inland Tangut think of countries as being
bordered by rivers? Oddly only one of three Tangut characters for
'river' words has 𘠣 <WATER>: 𗡴𗲌𗊧. And that character with 𘠣 <WATER> represents a Chinese loanword 1chhwan3
(< Xia Chinese 川 *1chhwan3).
What is 'water' doing in those characters? It serves no obvious
phonetic function, as those morphemes have no phonetic common
denominator in Tangut. Those last two words are key.
7.9.22:23: In Old Chinese, 也 was *Cilajʔ, and 池 was *RIlaj (with *I = a higher series vowel other than *i: *u and/or *ə). But the two have diverged considerably in modern languages: e.g., in Mandarin, 也 is yě and 池 is chí. The different rhymes reflect different minor syllable vowels:
Old Chinese *CiCaj > Mandarin ye, -ie
Old Chinese *CICaj > Mandarin -i
Old Chinese *(CA)Caj > Mandarin -e ~ -o ~ -uo ~ wo (depending on initial)
*A could have been *a or perhaps *e or *o
monosyllabic *Caj has the same reflexes as *CAcaj
The Mandarin spellings above are in pinyin and are not phonetic:
e.g., -o, -uo, and -wo are all [wo], but [wo] is
spelled o after labials, uo after other consonants, and
wo by itself.
20.7.7.23:47: WHITE RAT 5.17
? qulugh ai tau sair par ? nyair
'white rat year, five month, ten seven day'
1. Leftover from July 4th: Seeing only the English title of Dream of
the Emperor
led me to think that the Korean TV show was about a Chinese emperor or
one of the two rulers of the short-lived Korean Empire, but in fact the
Korean title is 대왕의 꿈 Taewang-ŭi kkum 'Dream of the Great King'
- specifically 武烈王 King Muyŏl of
Shilla (r. 654-661). Wikipedia's Muyŏl article translates the show
title as The King's Dream.
2. Yesterday I finally learned what oncology was.
And I found its translation equivalents using Wikipedia's left-hand
menu:
Japanese 腫瘍學 shuyōgaku 'swelling ulcer study'
Korean 腫瘍學 chongyanghak (< Japanese)
Chinese 腫瘤學 zhǒngliúxué 'swelling tumor study'
Vietnamese 癰疽學 ung thư học 'cancer (< 'ulcer ulcer') study'
Today I learned the Thai equivalent is วิทยามะเร็ง
<vidyāmaḥrĕṅa> wítthayaamareng 'study [of] cancer'. I'm
guessing มะเร็ง mareng is a loan from Khmer ម្រេញ
<mreña> mrɨɲ 'cancer'. (-ɲ is not a
possible Thai coda.)
3. Today I learned sofa is a borrowing from Arabic صفة ṣuffa 'long seat made of stone or brick' - but not 'sofa'! Wiktionary lists five distinct Arabic words for 'sofa' (the last is Iraqi):
أريكة 'arīka
(etymology unknown)
كنبة kanaba
(< French canapé)
تخت takht (< Persian)
ديوان dīwān
(cf. English divan
from Turkish, < ult. Sumerian 𒁾 dub 'clay tablet' + Old Persian vahana-
'house')
قنفة qanafa (< French canapé)
4. Another English furniture word of Arabic origin is mattress.
5. Wiktionary transliterates the Middle Persian ancestors of dīwan
and takht as <dywʾn'> and
<tʾht'>.
Mackenzie
(1971: xiv) calls <'> an "otiose stroke". Is
<'> truly superfluous like an extra dot in some Chinese character
variants?
6. Inscriptional
Parthian numbers remind me of how I used to avoid
writing certain numbers when I was very young: e.g., '5' is 𐭻𐭸
<4 1> (written from right to left). But the difference is
that Inscriptional Parthian
had no unique symbol <5> whereas I may not have wanted to write 5.
(I'm not certain 5 was on my list of taboo symbols.)
7. How did Proto-Iranian Hwah-
(ʔwah-?) 'dwell' become Middle Persian gyāg 'place'? I've
never seen the sound change Hw- > gy- before.
8. I wonder what it was like to be a Nanjing dialect enthusiast
from
the West watching the rise of the Beijing dialect. I can imagine after
reading what Gabelentz
wrote in 1881:
Only in recent times has the northern dialect, pek-kuān-hoá ['northern officer speech'], in the form [spoken] in the capital, kīng-hoá ['capital speech'], begun to strive for general acceptance, and the struggle seems to be decided in its favor. It is preferred by the officials and studied by the European diplomats. Scholarship must not follow this practise. The Peking dialect is phonetically the poorest of all dialects and therefore has the most homophones. This is why it is most unsuitable for scientific purposes.
9. Gabelentz would have been sad to see the Beijing-based standard taught worldwide. Conversely, it is not easy to find modern Nanjing forms despite the prestige of Nanjing in the past. Xiaoxuetang does not list Nanjing forms for 南 'south' and 京 'capital', the two morphemes that make up thename Nanjing. The English Wikipedia's article on the Nanjing dialect doesn't even sketch the phonology or given a single example word, much less a sentence. Fortunately that article does link to a couple of resources on the Nanjing dialect:
The title gives away key differences between Nanjing (Langjin) and Beijing:
Nanjing has merged *n- and *l- into l-: *nan > lang 'south'
Nanjing has merged *-an and *-ang into [ã]: again, *nan > lang [lã] 'south'
Nanjing has i instead of yi
Did the above mergers exist in Gabelentz' time? They would reduce the number of possible syllables in Nanjing.
cnvoicedic.com displays the pronunciations of Chinese characters in Guangyun (but in whose reconstruction?), Southern Min, Cantonese, Chaozhou, Hakka, Shanghainese, Suzhou, 围头 Weitou, 无锡 Wuxi, Nanjing, and the Beijing-based standard.
麻 mrä 'hemp' (level tone; no final tone letter)
马 mräx 'horse' (rising tone; -x)
骂 mräs 'scold' (departing tone; -s)
The use of -r- for Grade II reminds me of my
short-lived belief in 1994 that Middle Chinese still had medial -r-
(!). I assume -r- in this reconstruction is a notational
convention like the tone letters and not a literal medial liquid.
20.7.6.23:30: WHITE RAT 5.16
? qulugh ai tau sair par ? nyair
'white rat year, five month, ten six day'
Today I had my tooth extracted. Before my appointment I looked for cognates of Tangut 𘟗 0039 2korn1 'tooth' using STEDT's 'root canal' tool which was particularly fitting (because the tooth I lost had just undergone a root canal). STEDT derives the Tangut word from Proto-Tibeto-Burman *k(w/y)aŋ 'tusk/molar'.
Even if Proto-Tibeto-Burman (in the sense of an ancestor of all non-Chinese Sino-Tibetan languages) were valid, that etymology seems unlikely given my interpretation of Jacques' (2014) sound changes in Tangut:
| pre-Tangut |
Tangut |
Potential examples |
| *Rkaŋ |
1kor1 |
𘙴𗏬 |
| *Rk[a/o/u/e]mH |
2korn1 |
𘟗𗡹𘁩 |
(There is no Tangut syllable 2kor1 which would have developed from pre-Tangut *Rkaŋh.)
The nasal vowel of Tangut 2korn1 (pronounced something
like
[kõʳ]) points to an earlier *-m rather than an earlier *-ŋ.
Perhaps the true cognates of Tangut 2korn1 are those which
STEDT derives from Proto-Tibeto-Burman
*gam 'jaw, chin, molar'. A couple of forms of interest at
STEDT:
'eastern rGyalrong' tə swa kam 'tooth (incisor)' (Sun Hongkai 1991)
'rGyalrong' tə swa rgu 'molar' (Dai 1989)
The language labels are unfortunately not very specific.
kam looks like the pre-Tangut form, particularly if the
pre-Tangut vowel was *a (*RkamH).
rgu has an r- reminiscent of the *R- of the
pre-Tangut form, though I am not certain -gu is cognate to
pre-Tangut *-kVmH.
The swa in both rGyalrong forms is cognate to Tangut 𘘄 0169 1shwi3 'tooth'. Tangut -i is from pre-Tangut *a. Did pre-Tangut *s- palatalize before *i: *swa > *swi > shwi? That can't account for cases of s which did not palatalize before i: e.g.,
𗱂𗳎𗪏𗋃𗚌𗞉𗝦𗝠𗜫
are all read 1si4, not 1shi3. (Initial s-
is
associated with Grade IV and initial sh- with Grade III, so 1si3
and 1shi4 do not exist.)
The sequence of the s-k-roots for teeth in both rGyalrong
forms is identical in the Tangut collocation 𘘄𘟗 1shwi3 2korn1 'teeth' in Timely
Pearl 183.
Although I don't think there was a 'Proto-Tibeto-Burman' branch of
Sino-Tibetan, I still find STEDT's proposed cognate sets useful.
20.7.5.23:59: WHITE RAT 5.15
? qulugh ai tau sair par tau nyair
'white rat year, five month, ten five day'
I've long assumed that the dav·ḥ /daʍ/ (dav·ṃḥ
/ðaʍ/
with initial lenition) of Pyu
tar· dav·ḥ ~ tar· dav·ṃḥ ~ tdav·ṃḥ ~ tdaṃḥ¹ 'king'
might be cognate to Old Chinese 主 *CItoʔ 'master'. dav·ḥ
can occur without tar·: e.g., yaṁ dav·ḥ 'this ?' (12.3).
Today it occurred to me that if dav·ḥ in Pyu 'king' is a noun like 'master', then tar· dav·ḥ 'king' is a noun-noun compound '?-lord', and tar· in other contexts might be that mystery noun '?'.
7.7.0:31: Some examples of tar· without a following dav·ḥ ~ dav·ṃḥ:
tar· hak· 'good ?' (27.3)
Pyu adjectives follow nouns.
hmiṁ tar· miḥ '? ? ?' (19.1. 30.1)
the longest collocation I can find, not counting instances of tar· before ḅin·ṁḥ + verb
yaṁ dav·ḥ tar· 'this master? [and] ?'
¹7.6.12:56: In theory, a disyllabic form †ta
daṃḥ could appear in texts in the abbreviated style (i.e., the
script without subscripts), but so far the disyllabic form is only
found in texts in the full style with subscripts.


