
19.9.28.23:58: TANGUT DATABASE 3.2
1. Version 3.2 of my Tangut
database has nine corrected readings thanks to Andrew West. Details in the
changelog on sheet 2. More soon.
2. Viacheslav
Zaytsev compares the first and second printings of one of the most
important books I have ever used: Eric Grinstead's Analysis of the
Tangut Script.
I borrowed the second printing from the University of Hawaii library in
1994 and got my own copy a few years later. I have never seen the
first printing before:
My copy of the 1st printing has 3 inserts (2 of them are glued) with info in Danish. This allows us to know some more facts related to Grinstead’s biography: his PhD thesis was submitted to the Fac. of Philosophy at the U. of Copenhagen on 29 Nov 1971, and defended on 30 Jan 1973
That information has been incorporated into Grinstead's Wikipedia entry. I hope more facts about Grinstead emerge in the years to come.
It is a shame that no one in Copenhagen picked up his torch.
3. Could Tangut 𗼧 6037 1kew2
'to instruct' be a loan from Chinese 敎 'to instruct'? 1kew2
resembles keu, the Sino-Japanese reading of 敎 borrowed from
southern (not northwestern!) Chinese c. the 5-6th centuries. A few
modern Yue varieties have keu-like readings. (But Yue in
the south is only distantly related to the northwestern Chinese known
to the Tangut.)
There are two problems.
First, normally the rhyme of 敎 corresponds to Tangut -o2, not -ew2 (Gong 2002: 375).
Second, Li Fanwen's (2008: 949) Chinese glosses for 6037 do not match his English gloss 'to instruct':
誥 'admonition, to admonish'
詔 'decree, to decree'
The Combined Homophones-Tangraphic Sea entry for 6037 - with the only attestations of 6037 that I know of - may point to 'decree' since 6037 is something an emperor does.
19.9.27.23:57: MYŎNGDONG THEATER: LET'S MEET AT WALKERHILL
1. The photo I chose to illustrate my last post
is of 明洞劇場 Myŏngdong
Theater from 워_커힐에서 만납시다 Wŏ̄khŏhil esŏ mannapshida (Let's Meet at
Walkerhill, 1966). (Walkerhill is one word; it's the name
of this hotel.)
The entire
movie is on the
韓國映像資料院 Korean Film Archive's YouTube channel with Korean and
English subtitles - great for listening comprehension practice!
Let's look at the opening which is entirely in hanja with two exceptions.
0:55: The company name 株式會社東南亞映画公司 Chushik hoesa Tongnam A yŏnghwa kongsa 'Stock Company Southeast Asia Movie Company' is interesting in two ways. It combines the Japanese term 株式會社 'stock company' with the Chinese term 公司 'company'. And why is a Korean company called Southeast Asia Movie Company?
會 resembles 曾 with a closed 八 on top instead of 人 and an extra
horizontal stroke joined to the central vertical stroke.
The left-hand vertical strokes of 映 and 司 are elongated so 日 resembles 阝 and 口 resembles a squarish P.
画 (a simplification of 畵) has a vertical line that goes all the way to the bottom horizontal line.
The ㇆ stroke of 司 resembles the first two strokes of 可.
1:01: 泰 appears as 𣳾.
式 has its dot moved to the top left.
社 has a hook on the bottom left.
給 has the same closed 八 on top instead of 人 as 會 in this frame and 0:55.
1:06: 워_커힐 Wŏ̄khŏhil 'Walkerhill' has an underscore vowel length marker. There is no such marker after khŏ, even though Japanese would perceive Walker as ウォーカー Wōkā with two long vowels.
1:12: 7-stroke variant of 㓰, a simplification of 劃.
1:27: 崔 has a long bottom horizontal stroke extending leftward.
李 has a 子 resembling the bottom of 雪.
1:35: I feel sorry for the people whose names are illegible here. I
would write about their names if only I could make them out!
1:44: 玉 has a mirror-image dot.
后 is written entirely with straight lines. I didn't know it could be used in names.
2:00: The 重 of 勲 has a bottom horizontal line so long that it extends under the left half of 力.
梁 is missing its right dot, and the top right component looks like
(⿹㇆ 㐅).
2:15: The 卜 of 朴 resembles hangul ㅏ.
2:33: I've never seen 変 in a name before. The left and right dots of the top element 亦 are mirror-imaged and the central strokes are straightened.
2:47: 永 is written as 水 with 二 on top, resembling Khitan small script 004
with an extra horizontal line.
Blink and you'll miss what I assume is the surname 徐 based on the Korean Film Archive's credits listing.
투위스트 Thuwisŭthŭ 'Twist' is the only other hangul word in the
opening sequence.
2:57: 具 is missing one horizontal line, and two of the horizontal lines don't go all the way across to join the vertical lines. Those nonjoining lines are also in 貞 above, and 具, 貞, and 南 all have open left corners. In handwriting there can be a slight gap in that position, but in the stylized hand of these credits, that gap is bigger than usual.
The of 妊 looks like an angular ナ floating over an equally angular メ.
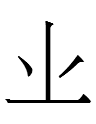
3:03: The 金 of 錫 has a bottom resembling 止 instead of Khitan small script 295 <p>:
The dot of 太 is moved leftward and overlaps with the lower left leg of 大.
The top left 丿 of 舞 has been reduced to a dot on top.
辰 is subtly different - the components under 厂 look like Γ atop Khitan small script 028 <sh>:
3:16: 星圃 Sŏng-pho 'Star-field' (if I'm reading correctly) is a nice name.
3:23: The top right of 監 looks like a horizontal line over ハ.
The ヰ of 韓 has a first horizontal stroke extending further to the left than the second one beneath it.
And skipping to the very end ...
1:36:34: 謝 has 扌 instead of 寸. I have never seen 扌 on the right of
any Chinese character before; it is the left-hand variant of 手.
2. Surprise! The
Dictionary of Chinese Character Variants has an entry for 媤 in its
appendix of made-in-Korea characters even though it already has an
entry for 媤 as a Chinese character.
3. Thirty years ago I believed I knew all the 常用漢字 jōyō kanji. But there were only 1,945 jōyō kanji then. 196 more were added (and 5 were subtracted) in 2010. I've seen all of the 196 before but one: 錮. Great, a Japanese ninth-grader knows that character but I don't.
I suspected 固 has been substituted for it, and I was right. Wiktionary explained that until 錮 became a jōyō kanji, the word 禁錮 kinko 'imprisonment without labor' was still written as 禁錮 in the criminal code, but in laws enacted (shortly?) after the announcement of the tōyō kanji (the predecessor of the jōyō kanji which excluded 錮), 禁錮 was written in mazegaki 'mixed writing' as 禁こ with hiragana こ <ko>. Newspapers, however, used 禁固 with kakikae: substituting the high-frequency tōyō and later jōyō kanji 固 for its homophone 錮.
大修館新漢和辞典 Taishūkan's New Sino-Japanese Dictionary gives only two words with 錮, 禁錮 and 錮疾, an alternate spelling of 痼疾 'chronic disease'. How common are these words? Google site:.jp stats:
禁固 1.14 million
禁錮 737,000
痼疾 10,100
禁こ 6,140
錮疾 168
It's looking to me as if 錮 is required in schools solely for the word 禁錮 (which is more frequently written 禁固).
Frequency stats for 錮 from Dmitry Shpika:
News: #1823
Wikipedia: #3349
Aozora: #4452
Twitter: #4490
錮 occurs just once in the entire Twitter corpus! I don't know how
meaningful #4490 is, since there's no real sense in ranking it higher
or lower than any other characters with only one instance in Twitter.
I think any kanji ranked lower than #2000 are not really worth
learning for most people. 錮 is ranked way lower than #2000 except in
the news, presumably due to reports about people imprisoned without
labor. The sort of thing I don't read. So I don't feel too bad about
not knowing it even existed until now.
I like Gakken's A New Dictionary of Kanji Usage (1982) which is frequency-based and includes frequent kanji regardless of whether they are jōyo or not. (It has an appendix of jōyō kanji that weren't frequent enough to make the cut for a main entry.) It doesn't include 錮. But would a new edition include it in the main section, or would it be in the appendix?
9.28.1:36: Just found that Windows 10's IME favors 禁固 over 禁錮,
specifying that the latter is a legal term. And 禁こ is not in the list
of potential spellings for kinko.
19.9.26.23:57: MYŎNGDONG THEATER (PART 1)
All topics from yesterday that I didn't have time for last night:
1. I'm afraid to look at this page of old 明洞劇場 Myŏngdong Theater-related images because it might be packed with variant hanja.
Before getting to those, let's look at the two maps at the top of the page:
1960년 명동극장 지도 1 (1960 Myŏngdong Theater Map 1)
1972년 명동극장 지도 2 (1972 Myŏngdong Theater Map 2)
(I can't figure out how to link to the maps, so I've copied their
titles which can be searched for.)
The 1960 map is entirely in hanja except for the non-Chinese word
유네스코 Yunesŭkho 'UNESCO' which can't be written in hanja and 극장 kŭkchang,
which can - but isn't, perhaps because its hanja 劇
場 would be almost illegible in a small space. The tiny characters are
not well-written and hard to read: e.g., I initially misread 市公舘 shigonggwan
'city public hall' as 市25舘 which makes no sense.
The 1972 map, on the other hand, is entirely in hangul. It is dangerous to make big claims based on just two items, but I cannot help but think the difference between the two maps reflects the shift away from hanja (which was far from complete in 1972 - the 1972 movie ads toward the bottom of the page still have hanja).
It's also telling that the two following announcements about the theater from 1953 and 1958 have had to be completely transcribed in hangul - something that wouldn't be necessary if hanja-heavy text were still the norm in 21st century Korea.
I haven't actually gotten around to discussing the variant hanja on
that page yet. Later.
2. When I started studying linguistics thirty years ago, I was put
off by an exercise whose answer was that Korean /s/ voices to [z]
intervocalically. No, it doesn't, which is why foreign z is
borrowed as /c/ which voices to [dʑ] intervocalically: e.g.,
브라질 <p.u r.a c.i.r> [puradʑil] 'Brazil'.
Or does it? T. Cho et al. (2002: 212) "in fact observed that about 46% of tokens of /s/ were fully voiced in this position". I have never heard [z] in Korean. Is this [z] a recent innovation?
Historically, *s did become [z] in intervocalic position, and that [z] then lenited to zero, which is why there are modern alternations such as
낫다 <nas ta> nat-ta get.better-FIN 'to get better'
나았다 <na Øat ta> naØ-at-ta get.better-PAST-FIN 'got better'
in which earlier *s survives as [t] before consonants but
vanishes between vowels.
Is history repeating itself?
I am very skeptical of intervocalic /s/ becoming long [sː]
according to Wikipedia.
I have never heard that /s/ sounding like Japanese ss.
3. I have no idea why the bound noun chabal in the expressions
자발(머리) 없다 chabal (mŏri) ŏpta (lit. 'X [head] lack')
자발 적다 chabal chŏkta (lit. 'X few')
both 'to be quick-tempered, impatient, restless' (Martin et al. 1967: 1379; is chabal 'patience'?)
has a variant 재발 chaebal. I'd expect a Cae-variant if the second syllable had i (e.g., 애기 aegi < 아기 agi 'baby'). ae is from *ai. But obviously there is no i in chabal. And a shift in the opposite direction (chaebal > chabal) has no precedent.
4. Martin et al.'s 1967 dictionary says 媤
<HUSBAND'S.FAMILY>
is a "Korea-made character", but Wiktionary gives
non-Korean readings for it: Mandarin sī, Cantonese si1,
and Japanese shi. The earliest attestation I can find is in 集韻 Jiyun (1037)
which
lists a variant 㚸.
The Korean reading 시 shi is unusual because Mandarin sī should
correspond to Korean sa. shi could theoretically be a borrowing
of an Early Middle Chinese *si rather than a c. 8th century
Late Middle Chinese *sz̩ that would have become the expected sa.
However, I can't find any evidence of 媤 before the 11th century. And if
媤 had existed in the Early Middle Chinese period, it would have been *sɨ
with a central vowel, not *si with a front vowel.
Moreover, I can't understand what would motivate reading 媤 as shi. Its phonetic is 思 sa, and no other characters with 思 are read shi. No, wait, no other common characters with 思 are read shi. There is a character 緦 <SACK.CLOTH> also read shi. 東國正韻 Tongguk chŏngun (Correct Rhymes of the Eastern Country, 1448) gives the prescriptive reading of 緦 as ᄉᆡ /sʌj/. Normally 15th century /ʌj/ becomes modern ae, but maybe in this instance it became i. 媤 is not in Tongguk chŏngun, but if it were, would its reading have been given as /sʌj/?
The correspondence of /ʌj/ to Mandarin i is unusual ...
unless ...
In Old Chinese, 緦 was *sə. If 媤 had existed in Old Chinese,
it too would have been *sə. That *sə should have
developed into Late Middle Chinese *sz̩ which would be borrowed
into Korean as /sʌ/ which would become modern sa.
But what if 緦 and 媤 had an Old Chinese variant *CAsə? (Perhaps such a sesquisyllable was actually original, and *sə is but a reduction.) The *A would condition the warping of *sə:
*CAsə > *CAsʌɰ > *sʌj
The end result matches the /sʌj/ for 緦 in Tongguk chŏngun. shi
for 緦 and its homophone 媤 would then reflect variation within Chinese
rather than a Korean-internal random change.
19.9.25.23:57: VARIANT HANJA C. 1963
No time to revise my Tangut database today, but Tangut turns out to
be marginally relevant in a most unexpected place: a
set of South Korean newspaper movie ads from c. 1963 (h/t ╹ω╹り
なれはあとい@衛兵るた)
with hanja variants that bring to mind Juha Janhunen's hypothetical
Parhae script. (No, I'm not drawing a direct line between the two.
Parhae characters did not survive into the 1960s. I'm merely pointing
out two sets of Chinese character variants from the greater Korean
cultural zone.)
1. This 人 + two strokes variant of 人 <PERSON> in an ad for 夫婦條約 Pubu choyak (The Husband-Wife Contract, 1963) reminds me of Eric Grinstead's (1972) hypothesis that the Tangut character component 𘢌 <PERSON> (in one out of five characters!) was derived from that variant.
Here's another example in an ad for 傷한 갈대를 꺾지 마라 Sanghan kaldaerŭl kkŏkkchi mara (Do Not Break a Damaged Reed, 1962).
A similar variant of 文 (Later Han example here) reminds me of Khitan small script character
327
which was pronounced something like [je] judging from its use in Chinese loans. Or was it? Kane (2009: 327) pointed out that in native words, 327 combines with a-graphs: e.g.,
327-123 <327.ar> (Xu 18.18).
327-261-051-189-123 <327.l.gha.a.ar> (Xu 33.2)
[je] coexisting with [a] is very un-'Altaic'. Did 327 have two readings, one for Chinese loans and another for Khitan words? Or are we still far from understanding how Khitan vowel harmony worked?
Dotless 文 326 (reading unknown) combines with both a- and e-graphs - again, very un-Altaic: e.g.,
326-100 ~ 326-361 <326.en>
- 100 and 361 are variants
326-261-51-189-290 <326.l.gha.a.an>
That last word looks like the feminine counterpart of masculine <327.l.gha.a.ar>. So is one word misspelled? In other words, was that word originally spelled with 326 or 327? Did 326 and 327 originally represent a harmonic pair? Was one [ja] and the other [je]? Compare with how Manchu differentiated a and e [ə] with a dot for the latter centuries later. The use of the dot in the Khitan small script to indicate grammatical masculine gender should also be taken into consideration when interpreting dotted 327.
2. This simplification of 演 as ⿰氵⿱𡧇儿 in an ad for 자이안트 Chaianthŭ = Giant (1956) is new to me. (A clearer comparison of the two.) ⿰氵⿱𡧇儿 is not in the Dictionary of Chinese Character Variants entry for 演.
Notice how the vertical part of ㄴ <n> in the logo for 자이안트 <ch.a Ø.i Ø.a.n th.ŭ> is barely visible. But the letter has to be ㄴ <n> because ㅡ <ŭ> is not possible in that position.
絕讚 chŏlchan 'highest praise' is written almost unrecognizably:
⿰⿱凵扌⿱一丷⿱(己) = 絕
⿱凵扌 doesn't look much like 糸
⿰言⿱(先)见 = 讚
the two 先 have been reduced to a single 先-like character with four strokes (no top left 丿, and the vertical line and bottom left 丿 are one stroke)
3. In the ad for Let No Man Write My Epitaph (1960) at the bottom left of this image, dots separate foreign names even though spaces would suffice. Such dots are commonly used to separate foreign names in Japanese, but I've never seen the practice in Korean before.
The character _ is used to indicate vowel length, much like Japanese ー (but note the different size and placement relative to the base line - and how it can go under the word divider dot):
진·세바그 <ch.i.n-·s.e p.a. k.ŭ> Jīn Sebagŭ [tɕiːn sʰebagɯ] 'Jean Seberg'
샤_리·윈타 <s.ya_r.i·Ø.u.i.n th.a> Shāri Wintha [ɕʰaːri wintʰa] 'Shelley Winters'
the name was Koreanized as if it were Shirley Winter;
the use of a for English /ɚ/ here and in Sebagŭ
is an older practice probably influenced by Japanese; modern Korean
converts English /ɚ/ into ŏ, an option absent from Japanese
9.26.0:48: Next to that ad is an all-text ad for 다이엘 Taniel (Daniel; Le Puits aux trois vérités, 1961) in Korean. It too has dots as name dividers. But its text is vertical, so its vowel length marker is also vertical 丨: e.g.
크
로
丨
드
<k.ŭ ro-t.ŭ> Kurōdŭ [kuroːdɯ] 'Claude'
Nowadays foreign /l/ and /r/ are borrowed differently in Korean in medial position (e.g., Claude is now 클로드 Khŭllodŭ), but at this point they seem to be both borrowed as Korean /r/ even when /r/ has a mismatching allophone: e.g., Morgan as 몰간 <m.o.r k.a.n> /morkan/ [molgan] (now 모간 <m.o k.a.n> is preferred). Another example is the aforementioned Shirley as 샤_리 <s.ya_r.i> /syaːri] [ɕʰaːri], now 셜리 <s.yŏ.r r.i> /syŏrri/ [ɕʰɔlli].
4. 禮 is normally simplified as 礼, but this ad for 江華道令 Kanghwa Toryŏng (The Reluctant Prince, 1963) has 𥘇 with an extra stroke.
Kanghwa Toryŏng doesn't mean 'The Reluctant Prince'; it is another name for King 哲宗 Chŏlchong (r. 1849-1863).
19.9.24.23:56: TANGUT DATABASE 3.1
1. Thanks yet again to Andrew West for submitting corrections for my Tangut database. Version 3.1 has
a sort column to facilitate restoring the original row order
after sorting
notes on cases when Li Fanwen's 1997 and 2008 dictionaries have
different numbers for the same character
a corrected reading for 𗂰 2li4
'west' (the Tangut translation of Andrew's name! - more to come).
2. What is the etymology of Cantonese aa6 'ten' in '31'-'99' (excluding the tens: '40', '50', etc.)?
三十 1saam1 sap6 'three ten' = 'thirty'
卅呀 saa1 aa6 X 'thirty 6aa X' = 'thirty-X'
卅 1saa is a contraction of the words for 三 'three' and 十
'ten' written as three 十 <TEN> fused together (into what
almost looks like <FOUR> in the Khitan large script). I
would have expected saam1 and sap6 to fuse into ˟saap.
The loss of -p is irregular in Cantonese.
Tone 6 points to a *voiced initial, presumably *ŋ- (呀 has a *ŋ-phonetic
牙). I wonder if aa6 is a linking particle related to the aa3
(not aa6!) in this list of items cited on Wiktionary:
因為國呀、權呀、榮呀、皆係你有、至到世世、誠心所願。
jan1.wai4 gwok3 aa3, kyun4 aa3, wing4 aa3, gaai1 hai6 nei5 jau5, zi3 dou3 sai3 sai3, sing4 sam1 so2 jyun6.
because kingdom aa3, power aa3, glory aa3, all is you have, reach to generation generation, sincere heart NMLZ wish.
'For thine is the kingdom, and the power, and the glory, for ever. Amen.' (1882 translation of the Gospel of Matthew)
But the tones are different: the linking particle is aa3, not aa6. Did tone 6 spread from 'ten' to the linking particle?
*saam1 sap6 aa3 > *saam1 sap6 aa6 > saa1 aa6?
3. I couldn't help but think Kage Baker was named after Japanese 影 kage 'shadow'. But her name is disyllabic:
Her unusual first name (pronounced like the word cage) is a combination of the names of her two grandmothers, Kate and Genevieve.
4. I'm surprised this concept came from the pen (or should I say word processor?) of a language teacher:
The cyborgs can recognize, understand, and speak any known human language instantly, including local variants and dialects.Their lingua franca is called "Cinema Standard", presumably the English spoken in 20th century movies, with which most Company operatives are obsessed.
The words are Wikipedia's and not Kage Baker's. Interestingly their
lingua franca wasn't Elizabeth English which was her specialty. I
suppose Cinema Standard was for the reader's convenience.
19.9.23.23:57: TANGUT DATABASE 3.0
Thanks again to Andrew West for submitting corrections for my Tangut database. Version 3.0 has
a column for Li Fanwen 1997 numbers
corrected entries for characters 5995-6074
no more ghost entries for characters 5995a, 5996a, 5997a, 5998a, 5999a, and 6075-6080
See the changelog on sheet 2 for details. Even more corrections soon.
19.9.22.23:57:
TANGUT DATABASE 2.1
Thanks to Andrew West
for submitting corrections for my Tangut database. Version 2.1 has corrected readings
for ten characters (see the changelog on sheet 2). More corrections
soon.


{kind=link}