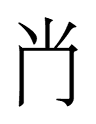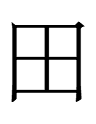
0819 (I'm going to follow Andrew's lead and start using N4631 numbers.)
19.1.26.22:22:
FIELD OF FORTUNE
No one is going to give me an award for awareness. Obliviousness, maybe.
I don't know how I missed Andrew West's latest Khitan post from last month. At least I'm only a month late.
He deals with two inscriptions in the Khitan large script. The last graph in the first inscription is
0819 (I'm going to follow Andrew's lead and start using N4631 numbers.)
which looks exactly like Chinese 田 'field'.
Andrew wrote,
Liu Fengzhu and Wang Yunlong 2004 propose the reading [ku].
I am confused. I have not been able to find 0819 in 劉鳳翥 Liu Fengzhu and 王雲龍 Wang Yunlong's 契丹大字《耶律昌允墓誌銘》之研究 (2004) or in Andrew's index to their appendix of Khitan large script characters and readings. This is the first time I have seen the reading [ku].
For many years I have assumed 0819 was read [ʊʁ] (ugh in the
loose transcription style I've been using on this site) on the basis of
two readings in Kane (2009: 183):
0729 0819 Nirug (Kane; 耶律褀墓誌 17; 23:36: corresponding to the name of a 耶律 Yelü clan member transcribed as 涅魯古 *nje lu ku in 遼史 History of the Liao Dynasty? related to Written Mongolian nirughun 'back, spine, mountain range'?)
1254 0819 Qudug (Kane; name of a general in 多蘿里本郎君墓誌銘 14, name of someone's son in 耶律褀墓誌 14 and perhaps the same person again in line 16 of the same inscription)
Kane does not cite sources for either of these forms (or many others
in his book), so I have supplied attestations that I have seen. (I
can't say I've seen many Khitan large script texts.)
The large script name Qudug seems to correspond to Kane's
(2009: 81) reading qudug 'happiness, good fortune' for the
unusually complex small script character 380 (Kane's number)
that "Liu, Chinggeltei, Aisin Gioro and others identify [...] with“
the northern Chinese transcription 胡覩古 *xu tu ku¹.
Normally I expect single logographs in the large script to correspond
to two-character blocks in the small script, but this is the only case
of the reverse that I can think of.
How can the [ku] reading of 0819 be reconciled with Kane's -ug / my [ʊʁ]? Here are two solutions:
1. Reversible readings
0819 was like Old Turkic 𐰸 which could be read as qu ~ qo
~ uq ~ oq ~ q depending on context (Tekin 1968:
24).
For years I have assumed that Khitan characters of this type were read as CV after vowels and VC after consonants. So Nirug and Qudug in the large script were <nir.ʊʁ> and <qʊd.ʊʁ>.
I would expect the [ku] reading (my [ʁʊ]) to be after a vowel, but I
don't know what the context was and can't test my guess.
2. Only one reading
What if the northern Chinese transcription 胡覩古 *xu tu ku
represented a Khitan [qʰʊdʊʁʊ]? Then 0819 could have been [ʁʊ]
everywhere.
The trouble is the alternate transcription 胡都 *xu tu reflecting another strategy to deal with final consonants absent in northern Chinese: namely, ignore them. This zero ~ *ku alternation implies a Kitan final [k]-like consonant. The word has an uvular initial in later languages, and in this region uvulars generally forbid following velars. So the final consonant has to be uvular [qʰ] or [ʁ], not velar [kʰ] or [g]. And that final consonant has to be [ʁ], since Chinese unaspirated obstruents were used to approximate Khitan voiced obstruents.
For now I think solution 1 is probably right. However, to be sure I
would need to see the context for which the [ku] reading was proposed.
¹Why not interpret the underlying Khitan word as [xutuku]? The limited northern Chinese syllabary was unable to cope with Khitan phonetics:
1. There was no northern Chinese [qʰ]. Chinese *x- (possibly [χ]) was the closest equivalent.
2. There was no northern Chinese [ʊ], at least in open syllables.
3. There was no northern Chinese [d].
4. There was no northern Chinese [ʁ].
5. There were no final stops in northern Chinese, so foreign final consonants were either rendered with CV-syllables or ignored (as in an alternate transcription of the Khitan word as 胡都 *xu tu).
I will discuss the Turkic, Mongolian, Jurchen, and Manchu evidence for this word in a separate post. Without that evidence, it would not be unreasonable to reconstruct *[xudug] without any uvulars or [ʊ].
19.1.25.23:59: I HAVE SHIMUNEK'S BOOK!
I thought I'd never see a copy of Andrew Shimunek's Languages of Ancient Southern Mongolia and North China (2017). I thank Prof. Victor Mair for reminding me about it. I then finally realized I could borrow it from the SOAS library. Duh. It wasn't on the shelves, so I had to order it from offsite. I picked it up today. Here's the photographic proof:

It is HUGE. 517 pages - more than two hundred pages longer than
Daniel Kane's The
Kitan Language and Script (2009) which has almost always been
at my side since 2011. (I didn't
take it with me when I studied in Thailand and Burma. Shame on me?)
I'm running out of time tonight, so I just want to say one thing about the book. (If I had all the time in the world, I'd write a book about the book.) Since 2019 is the 900th anniversary of the Jurchen large script, I went to the index in search of the Jurchen script. Seven pages are listed (xxv, 99, 105-108, 362), but flipping through the book, I've seen more Jurchen than that. I should write a Jurchen index for the book which has no indexes for language names and subjects but not specific words. I'll post the index here when I'm done.
1.26.3:13: Of course I'd like to write other indexes for the book as
well.
19.1.25.23:36: DO PYU AND PA-O SHARE A WORD FOR 'TO POUR'?
One of the many frustrating things about Pyu is that there are two
styles of writing it: full and abbreviated. And no one has yet figured
out why there were two styles¹, much less why
they were mixed in one
text (PYU 8). The problem is reminiscent
of the mystery of the Khitan large and small scripts. In 2010, Andrew
West wrote,
Having looked at and discounted the various possibilities outlined above, we seem to be none the wiser about why there were two completely different ways of writing the Khitan language. Both scripts are complex enough to require a considerable investment of time and effort to learn to read and write, so how is it possible that both scripts managed to coexist and flourish for so long ? Did the Khitan education system require students to learn both scripts, or were Khitan scholars only able to read and write one or other of the two scripts ? It makes no sense to me ...
One major difference - besides the fact that the Pyu writing styles involve only a single script - is that I presume both Khitan scripts provide more or less the same amount of phonological information in their non-logographic characters. That is not true of the two Pyu styles.
The abbreviated style omits all subscript consonants representing codas²: e.g., in PYU 8, the one text mixing the styles³, 'to be named' appears as rmiṅ·⁴ on line 3 but as rmi without subscript ṅ· on line 4. (All lines of PYU 8 after 3 are in the abbreviated style.) Until Arlo Griffiths' recent identification of the subscript consonants, Pyu was thought to be an exclusively open syllable language like Tangut⁵. Arlo also identified the r- atop rmiṅ·. So until he came along, the word was thought to be /mi/. Now I interpret it as /r.miŋ/.
If a Pyu text has no subscript consonants, it is most likely in the abbreviated style (though it is also possible that the text happened to have no closed syllables requiring subscript consonants⁶, particularly if it is very short).
The word cha 'to pour' appears in PYU 7.18 and 8.18. (PYU 7 is nearly identical to 8; one major difference is that PYU 7 is completely in the abbreviated style.) If the word had only appeared here, it would not be possible to determine if cha had a coda or not. However, there is a word chai 'to pour' in PYU 7.22 and 8.23. Scholars disagree on whether cha and chai mean the same thing. I belong to the school of thought that regards them as semantically identical. I go further and also regard them as phonemically identical: two different abbreviations of a hypothetical full spelling for /cʰaj/.
If I am correct, then /cʰaj/ cannot be compared to Written Burmese
ဆမ်း chamḥ 'to pour on food'; the codas cannot be reconciled.
But could /cʰaj/ be compared to Pa-O chjā 'to pour' which I found in Solnit's 1989 wordlist today? Pa-O is a Karenic language, and both Katō (2005) and Krech (2012) have proposed that Pyu is Karenic. So this is not a case of me finding a potential cognate in some random Sino-Tibetan language far from Pyu. If the distribution of Karenic languages in the past were like their distribution today, Pyu may have had Karenic neighbors. Or should I say relatives?
For now I continue to regard Pyu as an isolate within Sino-Tibetan - the family's equivalent of Albanian - or if an equlaly extinct parallel is desired, Tocharian. However, that doesn't mean I am not on the lookout for any lexical parallels which could be inherited or borrowed.
I don't think Pa-O chjā 'to pour' is one of those parallels. The word appears to be isolated within Pa-O, unless it is somehow related to other Karenic words with a *stopped tone⁷. Worse yet, Luangthongkum (2014: 9) regards Proto-Karenic *-e as the reflex of Proto-Tibeto-Burman *-a(ː)j. (But then where does her Proto-Karenic *-aj on p. 5 come from?) And her *-e apparently remained -e in northern Pa-O but warped to -ei in southern Pa-O (Shintani 2012: 31):
Proto-Karenic *ble A 'tongue' >
Northern Pa-O phre 33
Southern Pa-O plei 53
(It's not clear to me what sort of Pa-O is in Solnit 1989. I'm
guessing northern since 'tongue' in his Pa-O is phrē.)
I don't believe in Proto-Tibeto-Burman (i.e., a common ancestor of all non-Chinese Sino-Tibetan languages), but if I assume that Pyu /aj/ is a retention from Proto-Sino-Tibetan, then I would expect it to correspond to Pa-O -e(i), not -a. And I would expect Pa-O a to correspond to Pyu a; cf. 'moon':
Proto-Karen (Luangthongkum 2013) *ʔla A >
Northern Pa-O la 21
Southern Pa-O la 42
Pyu rla /r.la/ (PYU 4-6)
The initial ch- of 'pour' may also be a red flag, as it is extremely rare in Pyu, appearing only in three late texts (PYU 7, 8, and 39) and a single undated molded tablet (PYU 86). It almost always occurs in grammatical morphemes with variant forms in c. I suspect the ch-forms are sandhi variants. That leaves cha(i) as the only content word with ch-. Might it be a loanword? Perhaps it was borrowed from some Karenic language that broke *-e to *-aj. Or that ch- is from some rare Old Pyu cluster that fused into a simple onset in Late Pyu. (1.26.1:46: But no other such fusions are known to have occurred. However, Pyu spelling may be conservative. Could the ch- of 'to pour' be an 'error' revealing the 12th century pronunciation of an earlier cluster?)
¹1.26.1:11: All known molded tablets are in the abbreviated style. I have suggested that the abbreviated style was used due to the small amount of space on the tablets. However, there are also inscriptions with the abbreviated style despite ample space for the full style (e.g., PYU 2-6). And there are inscriptions in the full style squeezed onto small surfaces (e.g., the bottom edge of PYU 24). So space was not always a factor in the choice of style.
²1.26.2:00: All subscript consonants represent the codas, but the reverse may not have been true if the nonsubscript character -ḥ represented a glottal coda /h/ (or /ʔ/?). I also think ḥ indicated the voicelessness of sonorant codas: e.g., the honorific ḅay·ṁḥ was /ɓäj̊/ (and was abbreviated as ḅaṁḥ with the ḥ indicating a voiceless but unwritten /j/).
³1.26.1:11: On the other hand, the two Khitan scripts are never mixed.
⁴The middle dot indicates that the preceding
consonant letter is written as a subscript character.
⁵My Tangut notation does not make this clear since I use -n, -q, -r, and -' after vowels to indicate nasalization, tenseness, retroflexion, and an unknown quality of vowels that are not followed by codas.
⁶1.26.2:06: In other words, the only closed syllables in the text were those ending in ḥ /h/ and in voiceless sonorants (whose voicelessness was written as ḥ). If ḥ turns out to have been a marker of phonation or tone, then the text would only have open syllables.
⁷1.26.2:13: Katō (2005: 5) proposes that cha
'to pour' is cognate to Eastern Pwo chè, Western Pwo sheʔ,
and Sgaw chɛ̄ʔ, all in the H3 (*high stopped) tone category. I don't
think any of those Karenic forms are cognate to cha because I
would expect a Proto-Karenic final stop to correspond to a Pyu final
stop or /h/ (which might have really been /ʔ/).
19.1.24.23:59: DOES PYU ṄA 'TO SPEAK' HAVE A TANGUT COGNATE?
Today I realized that Pyu ṅa /ŋa(C)/, a verb of saying (PYU 7.14, 8.14) might be cognate to Written Tibetan ngag 'speech' and Old Chinese 語 *ŋ(r)aʔ 'to speak' and 言 *ŋa[n] 'speech'. Might ṅa also be cognate to the Tangut ngwu'-word family?
| Li Fanwen number |
Tangraph |
Reading |
Gloss |
| 445 |
𗕺 |
2ngwu'1 |
language, speech |
| 1014 |
𗟲 | 1ngwu'1 |
speech, word (cf. 4902 below) |
| 1822 |
𗖸 | to say, to eulogize |
|
| 4902 |
𗑾 | speech, word (how is this different from 1014?) |
One problem is the vowel. Tangut -u'1 is either from
pre-Tangut *-oX or *-əX¹.
The late EG Pulleyblank might
suggest *a/*ə-ablaut: Pyu, Tibetan, and Chinese had *a
whereas pre-Tangut had *ə. Perhaps comparative work with closer
relatives of Tangut will point to one vowel or the other.
Another problem is the medial *-w- which is from pre-Tangut *P-. None of the other languages have preinitial or presyllabic p-. Contrast with Tangut 𗏁 1ngwy1 < pre-Tangut *P-ŋa² 'five' whose *P- corresponds to p- in Pyu piṁṅa /pïŋa/ 'id.'
¹1.25.0:52: -' represents an unknown Tangut
phonetic quality and *-X represents its equally unknown
pre-Tangut source.
²1.25.1:05: The vowel of 'five' irregularly
changed to match that of the adjacent numeral 𗥃
1lyr'3 'four', presumably at a stage when 'four' was something
like *R-ly' before *R- conditioned a retroflex vowel
and was lost. If not for that change, 'five' would have been †1ngwi1.
19.1.24.23:48: THE JURCHEN NAME OF EMPEROR SHIZONG (PART 4)
In parts 2 and 3 I
covered the possibility of
as a Jurchen single-character spelling for the Jurchen name of 金世宗 Emperor Shizong (r. 1161-1189) which is only known to me as a Chinese transcription 烏祿 *u lu.
I don't know of any other single-character candidates for the spelling, so I'm going to move on to potential parts of a two-character spelling.
N3696 has a handy index of Jurchen characters organized by Jin Qizong's readings. It lists five types of u-characters (variants not shown here):
Why would Jurchen need five u when it could have done with
one? Maybe because it didn't have just one? If Jin Jurchen had a /ʊ/ :
/u/ distinction and a vowel length distinction, then four of the five
could stand for /ʊ ʊː u uː/. And the fifth might not have stood for u
in the Jin dynasty; it might have been a logogram for a word beginning
with u- that was later spelled with it plus one or more
phonograms, leading to its reanalysis as an u-character.
Another possibility is that the Jurchen script inherited a set of characters from the Parhae script that somehow made more sense for the language it originally represented but became redundant for Jurchen.
I'll keep those scenarios in mind as I examine the u-characters
in depth from part 5 onward.
19.1.23.23:56: NATIONAL HANDWRITING DAY: JURCHEN EDITION
Today is National Handwriting Day.This year is the 900th anniversary of the Jurchen large script.
Intersect the two, and you get me writing gurun ni ngala herge inenggi, my attempt to translate 'national handwriting day' in Jurchen.
 |
gur |
gurun | nation |
| un |
|||
| ni |
ni |
genitive |
|
| nga |
ngala | hand |
|
| la |
|||
| her |
herge | shape, possibly script
like Manchu hergen? |
|
| ge |
|||
| DAY |
inenggi |
day |
I'd like to comment on those eight graphs, but I'm out of time, and
I want to get back to the Emperor Shizong series
tomorrow. And I still have to write the later parts of "The Jurchen Script: Innovation or
Derivation?".
19.1.22.23:33: THE JURCHEN NAME OF EMPEROR SHIZONG (PART 3)
Moving on to the first half of
<? ? fushe den>
from the end of part 2, the antepenultimate character appears in two entries in the Bureau of Translators vocabulary: 强盛 'strong and prosperous' above, and 'sword' which was translated as
hanma (Kiyose and Jin Qizong's reading; I have converted Jin's notation into mine which in this case is identical to Kiyose's)
and transcribed into Ming Mandarin as 罕麻 *xan ma
(#217). Hanma doesn't look like Manchu loho 'sword',
but it does resemble Manchu halmari 'a sword used by shamans'.
There was no Ming Mandarin syllable *xal, so *xan may
correspond to a Jurchen hal-. (See Kane 1989: 130 for other
cases of this type of correspondence.)
The -ri of halmari may be a noun suffix of unknown
function. See Gorelova (2000: 114) for other examples of -ri. The
Bureau of
Translators vocabulary dialect may have preserved the bare stem halma
without a suffix. See Kane (1989: 116) for other instances of zero in
this dialect corresponding to Manchu -ri.
On the other hand, the character
only appears at the ends of the aforementioned two words, 'sword' and 'strong'. If it were simply read ma, it should be more common as a phonogram. Could it have represented maa with a long vowel or even mar? Kane (1989: 130) noted that Jurchen syllable-final-r was sometimes omitted in Chinese transcription but does not give any word-final examples.
Could that character (for mar?) be derived from the Chinese
character 犮 which would have been read as *pɦar in northern
Late Middle Chinese?
Jin Qizong (1984: 202) proposed mam as an alternate reading of that character but did not give any context for that alternate reading. (Norman 1978 lists only three Manchu words ending in -m, so I am skeptical of -m as a final in Jurchen.)
In any case, that character's reading contained a, so vowel harmony dictates that there was a break between
Let's go back to the Ming Mandarin transcription for that phrase:
and
the a-word <? ma(a/r?)> 'strong' and the e-word <fushe den> 'prosperous'.
兀魯麻弗塞登 *u lu ma fu sə təŋ
The first character
must correspond to 兀魯 *u lu. Or so Kiyose and Jin thought;
both glossed it as 'strong' (which then raises the question of what the
-ma after it was).
But wait. It just occurred to me that
might be -lma. If so, then the two words with it could be interpreted as
<SWORD.lma> = halma, transcribed as Ming Mandarin 罕麻 *xan ma
<STRONG.lma> = ulma, transcribed as Ming Mandarin 兀魯麻 *u lu ma
Compare the shape of <STRONG> to the right side 𧈧 of the Chinese character 強 'strong'.
I think the first characters of those words were originally
standalone logograms. Those Ming spellings have a final phonogram that
might not have been present when the script was originally developed in
the early 12th century. If the final phonogram was <lma>, then my
attempt to link it to 犮 *pɦar will have to be abandoned.
If <STRONG> was a standalone logogram for ulma (or ulumaa,
urumar, etc.) then the early 13th century name
Aotun Ulu (Jin Qizong's reading)
may have been Aotun Ulma (or urumaa, ulumar, etc. - notice I haven't repeated the possible permutations). Unfortunately I don't know of any Tungusic cognates of the Jurchen u-word for 'strong' that could narrow down the possibilities. Could the word be non-Tungusic: i.e., Khitanic? (Not necessarily from literary Khitan but either some nonstandard dialect of Khitan or a related, unwritten language - the source of the Jurchen numerals 'eleven' through 'nineteen' which are para-Mongolic but not literary Khitan.)
It's also possible that <STRONG> is functioning as a phonogram for ulu or uru in that name. The character may give connotations of 'strong', but ulu or uru by itself may not mean 'strong'; that disyllable could be an unrelated partial homophone of 'strong'.
Even if <STRONG> in that name was ulu or uru, that still doesn't mean that was the name of 金世宗 Emperor Shizong (r. 1161-1189) - the character reading could have had l whereas the emperor's name could have had r - or vice versa.
And if even the two names have the same liquid, they might not have
had the same vowels! Manchu had two allophones of /u/, [ʊ] and [u], in
accordance with the rules of vowel harmony. Kiyose (1977: 45-47) argues
on the basis of Ming Jurchen spelling that the Bureau of Translators
dialect had a single /u/. Kane (1989) similarly posits a single /u/ for
the Bureau of Interpreters solely on the basis of Chinese
transcriptions (since the Interpreters' dialect was not also recorded
in Jurchen spelling). However, Kiyose (1977) believes Jin Jurchen had a
more complex vowel system than Ming Jurchen. My guess is that this
system had seven vowels: three 'feminine', three 'masculine', and one
'neutral' (but who knows, maybe there was a 'masculine ī /ɪ/
too):
| 'feminine' vowels |
i /i/ |
e /ə/ |
o /o/ |
u /u/ |
| 'masculine' vowels |
(ī /ɪ/?) | a /a/ |
ō /ɔ/ |
ū /ʊ/ |
(The macron does not signfy length. Möllendorf used a macron to
transliterate Manchu <ū> [ʊ], and I have used it for other
'masculine' vowels except for a - ā would be redundant.)
In theory Jin Jurchen might have had a phonemic distinction between
/ʊ/ and /u/. If so, then perhaps the emperor's name was Ulu
/ulu/
with feminine vowels and the name of the successful 進士 jinshi
candidate was Aūtūn Ūlū /aʊtʊn ʊlʊ/ with masculine vowels. (I
think the u-vowel of <STRONG> was [ʊ] to harmonize with
the masculine a-vowel.)
As we will see in the next parts, the Jurchen script has multiple
characters for what seem to be u- and lu-syllables from
a Ming Jurchen perspective. Such apparent redundancy may reflect Jin
Jurchen distinctions between /ʊ/ and /u/ on the one hand and /lʊ/ and
/lu/ on the other. But does the evidence support that hypothesis? We
shall see.
19.1.21.22:10:
THE JURCHEN NAME OF EMPEROR SHIZONG (PART 2)
The most obvious candidate for the Jurchen spelling of the name of 金世宗 Emperor Shizong (r. 1161-1189) who died 830 years ago yesterday is
ulu (Jin Qizong's reading)
which appears in the name
Aotun Ulu (Jin Qizong's reading)
from a 1224 list of successful candidates for the degree of 進士 jinshi
in the imperial
examinations. (Alas, as of this writing the article does not cover
examinations in the Jurchen Empire.)
Problem solved? No, not quite.
In part 1 I already mentioned the problem of whether 烏祿 *u lu, the Chinese transcription of Emperor Shizong's name, represented Jurchen Ulu or Uru. How do we know that his name was Uru and not Ulu? We don't.
But let's suppose it was Ulu. Did Ulu have to be written with the character
?
Perhaps not.
Let's look at how that character's reading was reconstructed.
I am unaware of any Jin dynasty Chinese transcriptions of the character. The only transcription I know of is from the Bureau of Translators vocabulary in which 强盛 'strong and prosperous' was translated as
uluma (or uruma) fusheden (Kiyose)
uluma fuseden (Jin Qizong)
and transcribed into Ming Mandarin as 兀魯麻弗塞登 *u lu ma fu sə təŋ (#761).
There is no word spacing in the Jurchen script. How did Kiyose and Jin decide where to make a break between 'strong' and 'prosperous'? My guess is vowel harmony. Normally in Jurchen, a and e do not coexist within a root.
But how do we know that there were different vowels a and e in the two roots? Let's work backwards from the last character which also appears in
geden 'leave'
and transcribed into Ming Mandarin as 革登 *kə təŋ (#862). Both transcriptions have 登 *təŋ in common, so
must have sounded like 登 *təŋ: i.e., it was den [təɴ] in the transcription system I use on this site.
One character down, three to go:

<? ? ? den>
The penultimate character also appears in
fushegu 'fan' (cf. Manchu fusheku 'id.'; I can't explain the g : k mismatch)
transcribed into Ming Mandarin as 伏塞古 *fu sə ku (#221). Both transcriptions have 弗塞/伏塞 *fu sə in common, so
must have sounded like 弗塞/伏塞 *fu sə: i.e., it was fushe [fusxə] in the transcription system I use on this site.
(I follow Kiyose in supplying an h [x] after s on
the basis of Manchu fusheku. It is possible that the
Ming Jurchen dialect of the vocabulary
lost the h that standard Manchu retained from another Ming
Jurchen dialect. In any case, there were no Ming Mandarin syllables *fus
or *sxə,
so 伏塞 *fu sə may or may not have stood for Jurchen fushe
rather than fuse.)
Halfway there:
<? ? fushe den>
Fushe and den are in vocalic harmony (no a to
conflict with e in
either reading) and are likely to have been part of the same word. But
was fusheden by itself 'prosperous', or did the second
character represent one or more syllables at the beginning of
'prosperous'? (We can assume that at least the first character
represented the Jurchen word for 'strong'.) Kiyose and Jin give away
the answer above. However, if you want to learn the probable logic
behind their answer, watch for part 3.
19.1.20.22:59: THE JURCHEN NAME OF EMPEROR SHIZONG (PART 1)
金世宗 Emperor Shizong (r. 1161-1189) of the Jin dynasty died 830 years ago today. He was a great advocate of the Jurchen language and culture. He had the Chinese classics translated into Jurchen. Unfortunately, none of those translations have been found. I know of only nine or ten dated Jurchen texts from his reign, the 大定 Dading 'Great Settlement' period:
| Year |
Name |
# of Jurchen characters |
| 1167 |
海龍 Hailong rock inscriptions |
~20 + ~80 = ~100 total |
| 1176 |
河頭胡論河 Hetouhulunhe 100-household seal |
6 |
| 1178 |
和拙海欒 Hezhuohailuan 100-household seal |
8 |
| 1178 |
夾渾山 Jiahunshan 100-household seal |
7 |
| 1178 |
可陳山 Kechenshan 100-household seal |
13 |
| 1179 |
迷里迭河 Milidiehe 100-household seal |
unknown |
| 1179 |
移改達葛河 Yigaidagehe 100-household seal |
7 |
| 1185 |
Jin Victory Memorial Stele |
~1500 |
| 1186 |
Zhaoyong General Memorial |
21 |
Further details are at Wikipedia.
The last dated Khitan large and small script texts are also from his period:
- the epitaph for 李爱郎君 Court Attendant Li Ai (1176; 470 large script characters)
- the epitaph for the 博州防禦使 Defense Commissioner of Bozhou (1171; 1,570 small script blocks)
Again, further details are at Wikipedia.
Emperor Shizong's successor 金章宗 Emperor Zhangzong (r. 1189-1208)
abolished
the Khitan scripts.
But back to Jurchen - I've been wondering what Emperor Shizong's
name was in
the Jurchen script. The History of the Jin Dynasty (Basic
Annals 5 and 6) presents it as 烏祿 *ulu in the Chinese
script. Chinese transcriptions of Jurchen do not differentiate between
Jurchen l and r since Jin Chinese had no *r. So
his name could have been Ulu or Uru in Jurchen. The
ambiguities do not stop there. In theory there are many ways to spell
both Ulu and Uru in the Jurchen script. I'll be
examining the possibilities in the following parts: 2,
3, 4, 5 (link to be
added).