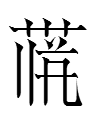
2152 3284 1ʂɨi 2lɨa
14.10.18.23:08:
THE TANGUT NAMES OF KUMĀRAJĪVA (PART 1)
Having just written about Chinese transcriptions of Indic, I thought it was neat that I then stumbled upon KJ Solonin's tentative identification of
2152 3284 1ʂɨi 2lɨa
as a Tangut transcription of the name of Kumārajīva (1998: 411, 414 #80), translator of the Lotus Sutra and other Buddhist texts into Chinese. Kumārajīva's Chinese name was 鳩摩羅什, pronounced *kumaladʑip in the 4th century AD. In the Tangut period northwestern dialect of Chinese, it would have been read as *kɨwmɔlɔʂɨi. If the two names are connected, the Tangut name might be an accidental inversion of
*3284 2152 2lɨa 1ʂɨi
corresponding to 羅什 *lɔʂɨi, an abbreviation of 鳩摩羅什 *kɨwmɔlɔʂɨi.
(This abbreviation was obviously created by a Chinese speaker, as a
natural break in the Sanskrit would be between Kumāra 'prince'
and jīva 'life'.)
Unfortunately, the name 2lɨa 1ʂɨi only appears once in the
text that Solonin translated. However, a transcription of the full name
鳩摩羅什 *kɨwmɔlɔʂɨi does appear in the Hongchuan preface of
the Lotus Sutra (Li 2008: 533; see Nishida 2004
on the Tangut Lotus Sutra):
3948 3369 3284 2152 3284 (again!) 1kɨa' 1mia 2lɨa 1ʂɨi 2lɨa
There are several things that are odd about this spelling.
First, 3948 1kɨa' is a poor match for Chinese 鳩 *kɨw. It is a transcription character for Sanskrit ka and kya (Arakawa 1997: 110, 116; Kychanov and Arakawa 2006: 692). In the Tangut translation of the Forest of Categories, 鳩 *kɨw was transcribed as
1429 1kiew
which is a much better match (Gong 2002: 438). 1429 is also a
transcription character for Sanskrit (?) kyu (Grinstead 1972:
111) and is the first character in a different transcription I'll
examine tomorrow.
Second, 3369 1mia (rhyme 20) has an -i- that
corresponds to zero in Chinese 摩 *mɔ and Sanskrit and Tibetan ma
(Arakawa 1997: 110, Kychanov and Arakawa 2006: 234).
Maybe I should follow Sofronov and Arakawa and stop reconstructing -i- in rhyme 20.
Third, 3284 2lɨa (rhyme 19) has an -ɨ- that corresponds to zero in Chinese 羅 *lɔ and Sanskrit la (Arakawa 1997: 110).
I have yet to see a fully satisfactory solution to the problem of
reconstructed Tangut medials seemingly reflecting nothing in
transcriptions of Chinese and Sanskrit.
Fourth, 3284 appears again, corresponding to zero in the
four-syllable Chinese name. The first four syllables of this longer
Tangut name are obviously based on Chinese (hence 2lɨa for 羅 *lɔ
rather than *raʳ for Sanskrit ra). I would have
expected a fifth syllable to be
a transcription of Chinese 婆 *phɔ < *ba for Sanskrit va in longer Chinese names for Kumārajīva:
2640 1pho
鳩摩羅什婆 *kɨwmɔlɔʂɨiphɔ < *kumaladʑipba
鳩摩羅時婆 *kɨwmɔlɔʂɨiphɔ < *kumaladʑɨba
鳩摩羅耆婆 *kɨwmɔlɔtʂɨiphɔ < *kumalatɕiba
Having not seen the text where Li found this longer transcription, I don't know if this second 3284 is a typo (I doubt that, as even the Chinese translation has a doubled syllable: 鳩摩羅什羅) or in the orignal. Kychanov and Arakawa (2006: 692) do not list any words beginning with 3948. Maybe this longer name is a confused blend of *1kɨa' 1mia 2lɨa 1ʂɨi and the short inverted name 1ʂɨi 2lɨa.
At least 2152 1ʂɨi is a perfect match for Chinese 什 *ʂɨi, and is attested as a transcription of the last syllable of the name 李七什 *lɨi tshi ʂɨi (Li 2008: 356).
Next: Another Tangut name for Kumārajīva.
14.10.17.22:51: TESTING STAROSTIN'S 'LATE-RAL' SCENARIO
(I rhyme lateral [ˈlætəɹo] and scenario [səˈnæɹio]. 'Late-ral' is [ˈlejtəɹo] with a linking schwa to preserve the resemblance to [ˈlætəɹo].)
One of the biggest sound changes in Chinese was the loss of laterals:Old Chinese *l- in type A syllables > Middle Chinese *d-
Old Chinese *hl- in type A syllables > Middle Chinese *th-
Old Chinese *l- in type B syllables > Middle Chinese *j-
Old Chinese *hl- in type B syllables > Middle Chinese *ɕ-
(The nature of the Old Chinese type A/B distinction is disputed, but the Middle Chinese initials are uncontroversial.)
In my last entry, I mentioned two conflicting chronologies for the lateral shift in Chinese. Schuessler (2009) reconstructed Middle Chinese-like initials (*j-, *ɕ-, *d-, *th-) in his Later Han Chinese (i.e., Eastern Han / Late Old Chinese), whereas Starostin mostly reconstructed transitional fricatives or laterals for that period:
| Old Chinese syllable type | Early Old Chinese | Late Old Chinese | Middle Chinese | |
| Starostin | Schuessler | |||
| A | *l- (Starostin: *l- and dɮ-) | *l- | *d- | |
| *hl- (Starostin: *tɬ-) | *hl- | *th- | ||
| A and B | *r- | *l- | ||
| B | *l- | *ʑ- | *j- | |
| *hl- (Starostin: *tɬ-) | *ɕ- | |||
(I use the same notation regardless of scholar for ease of comparison. I list Starostin's reflexes of his Early Old Chinese *tɬ- and *dɮ- because they correspond to *hl- and *l- in others' reconstructions. Starostin's EOC *hl- behaved differently from others' *hl-; it became Late Old Chinese and Middle Chinese *h- [= others' *x-]. For arguments against Starostin's lateral affricates, see Sagart 1999. I have included EOC *r- for comparison.)
To test Starostin and Schuessler's reconstructions of Late Old Chinese (LOC), let's look at Eastern Han transcriptions of Indic from Coblin (1983).
If Starostin is right:- LOC *l- should transcribe Indic l
If Schuessler is right:- LOC *hl- shouldn't be used in transcription because there was no Indic voiceless hl
- LOC *r- should transcribe Indic r
- LOC *d- from EOC *l- could transcribe Indic d
- LOC *th- from EOC *hl- could transcribe Indic th
- LOC *l- from EOC *r- should transcribe both Indic *l and *r (since LOC no longer had *r-)
Both would agree that LOC *ɕ- should transcribe Sanskrit ś [ɕ].
As I already noted last time, the correspondence of Starostin's *ʑ- / Schuessler's *j- to Indic y- [j] is ambiguous since Starostin would have said that *ʑ- was the closest available initial due to the absence of *j- in his LOC. Correspondences between this LOC initial and Sanskrit c-, j- [ɟ], ś- [ɕ], and s- suggest that it was "a fricative or affricate of some sort" (Coblin 1983: 63): e.g., Starostin's *ʑ-.
In the transcriptions of 安世高 An Shigao (mid-2nd c. AD) we find that:
- Indic d and even intervocalic -t- were transcribed with Starostin's LOC *l- / Schuessler's *d- (18, 19; the numbers are from Coblin 1983)
- Indic l was transcribed with Starostin's LOC *r- / Schuessler's *l- (13, 15, 28)
These pattern are not quirks of An Shigao; they can also be found in the transcriptions of 支婁迦淺 Zhi Loujiachen/Lokakṣema (mid-2nd c. AD; his name has 婁 Starostin's LOC *r- / Schuessler's *l- for Sanskrit l-) and 康孟詳 Kang Mengxiang (late 2nd-early 3rd c. AD). All three men were non-Chinese who settled in Luoyang, so their transcriptions probably represent the same dialect.
The only Indic th in An Shigao's transcriptions was transcribed with 替 whose EOC initial is ambiguous. It definitely had *th- in Middle Chinese and must have had *th- here. Starostin might have taken that as evidence for reconstructing 替 with *th- in EOC.
th is a low-frequency consonant, so it's not surprising that there are no instances of it transcribed with original or secondary *th-. (Oddly Lokakṣema transcribed it as the coda-onset sequence -t s- in 55.)
I conclude that the following chain shift had occurred in the Luoyang dialect of LOC by the mid-2nd century AD:
*r- > *l- (type A) > *d-
This is contrary to Starostin's 'late-ral' scenario in which the laterals hardened later.
I also reconstruct a parallel change*hl- (type A) > *th-
on the grounds that it would be odd if *hl- lagged behind its voiced counterpart *l-. Unfortunately there is no Indic transcription evidence for that.
Phonetic glosses such as
indicate that *hl- did not harden in other LOC dialects during the early centuries of the first millennium AD. The glosses would not make sense if *hl- had already become *th-.'聖 *hlieŋh (type B; > MC *ɕieŋʰ) is read like 通 *hloŋ (type A; > MC *thoŋ)' (Xu Shen 1063, b. in 召陵 Zhaoling 200 km SE of Luoyang, fl. c. 100 AD)
'天 *hlein (type A; > MC *then) read as 身 *hlin (type B; > MC *ɕin)' (Gao You 243, b. in 涿 Zhuo, fl. c. 200 AD)
10.17.23:17: Some LOC glosses that seem bizarre might make more sense if we don't try to shove the words into the standard paradigm defined by the Chinese lexicographical tradition. For instance, perhaps Xu Shen pronounced 通 as something like *hliøŋ with a front diphthong similar to 聖 *hlieŋh. The expected Old Chinese reconstruction 通 *hloŋ is mechanically derived from Middle Chinese *thoŋ, whereas my hypothetical *hliøŋ would have vowel warping conditioned by a presyllable in an Old Chinese variant *Cɯ-hloŋ or *Hɯ-loŋ. Perhaps *Hɯ-loŋ was the earliest form which developed along two paths:
Early fusion: i.e., before *ɯ conditioned vowel warping
*Hɯ-loŋ > *hloŋ > *thoŋ (Middle Chinese prestige form recorded in dictionaries)
Late fusion: i.e., after *ɯ conditioned vowel warping
*Hɯ-loŋ > *Hɯ-luoŋ > *hluoŋ > *hlioŋ > *hliøŋ (> Middle Chinese *ɕyøŋ?; nonprestige and extinct?)
For more examples of variation between fused and unfused presyllables, see the discussion of Phan Rang Cham (Austronesian) and Ruc and Nha Heun (Austroasiatic) in Sagart (1999: 15-17).
14.10.16.23:12: TILTED TONGUE
On Monday, I wrote,
Last night I mentionedI wrote the pre-Tangut source of ld- as *L-. External evidence may help us identify what *L- was.
=(
+
)
3190 1ldwia 'tongue' = (4226 1ldwị + 0537 1pia) + 1223 2phɤo' (Mixed Categories of the Tangraphic Sea 11.122)
as one of the syllables with a fanqie including the mysterious additional character 1223.
1ldwia is probably related to the many l-words for 'tongue' in Sino-Tibetan: e.g.,
Old Chinese 舌 *mɯ-lat or *m(ɯ)-ljat (Baxter and Sagart 2014: *mə.lat)
also cf. 舐/舓/咶 *mɯ-leʔ or *m(ɯ)-ljeʔ (B&S 2014: *Cə.leʔ) 'to lick'
and perhaps 舔 *hlˁimʔ < *qlimʔ or *Hʌ-limʔ (? - I can't find any attestations before the 13th century AD; nonetheless it resembles lem-words for 'tongue' elsewhere in Sino-Tibetan and may be very old) 'to lick'
It is not possible to determine whether Middle Chinese *ʑ- in 'tongue' and 'lick' is from *mɯ-l- or *m(ɯ)-lj-. Coblin (1986) reconstructed medial *-i- for 'tongue' at the Proto-Sino-Tibetan level.
If the third word is related, and if the root was *√lj, then I can reconstruct
*m(ɯ)-lj-a-t (a-grade)*m(ɯ)-lj-e-ʔ (e-grade)
It is tempting to reconstruct *m(ɯ)-lj-a-j-ʔ (a-grade), but the phonetics 氏 and 易 point to *e.
*qli-m-ʔ or *Hʌ-li-m-ʔ (zero grade; the *j of the root became *i if no vowel followed)
Classical Tibetan ljags /ldʑags/ < *n-ljaks (Jacques, "The laterals in Tibetan")
CT j is an affricate /dʑ/, whereas pre-Tibetan *j is a glide.
Although it would be nice if Tibetan had *m- like Chinese, *m-lj- would have developed into mj- /mdʑ/, not lj- /ldʑ/ (Jacques, "The laterals in Tibetan").
Written Burmese hlyā
I cannot explain the variation in final consonants (Old Chinese *-t and *-[m?]ʔ, pre-Tibetan *-ks, Written Burmese zero). I presume they are all suffixes.
The pre-Tangut source of 1ldwia must be a combination of the following elements:
ld- may be from a consonant prefix plus root *l-
-w- is from a labial prefix *P- (and that prefix might have combined with *l- to form ld-)
-i- is from *-j- and/or a presyllabic *-ɯ-
a final stop could have been lost without a trace
the tone indicates there was no final *-H
If the root was *√lj, that narrows down the possibilities.
The simplest reconstruction would be *m-lja whose *m- would combine with *l- to form ld- and condition the medial glide -w-.
A more complex reconstruction *P-N-lja would have separate sources of -d- and -w-.
Forms for 'tongue' in Horpa varieties seem to be from *P-lj-: fʑa, vɮɛ, etc. See STEDT and the rGyalrongic Languages Database (item #36).
According to Guillaume Jacques ("The laterals in Tibetan"), Li Fang-Kuei, Coblin, and Gong all reconstructed *n-l- as the source of Written Tibetan ld- (whereas Jacques reconstructed *d-l- since his *n-l- became WT Hd- /nd/.) Perhaps *N-l- similarly became ld- in Tangut. *N- may have been an *n- as in pre-Tibetan *n-ljaks 'tongue' or an *m- as in Chinese *m(ɯ)-ljat.
The only other word out of the eight I discussed yesterday that might have a cognate - with emphasis on might - is
+
)
0841 1ɬwiẹ 'oblique, slanting, inclined' = (2814 2ɬị + 3439 1piẹ) + 1223 2phɤo' (Mixed Categories of the Tangraphic Sea 12.122)
Before I go on to a possible cognate, I realize what 1223 is doing here and in various other cases. I think 1223 in such contexts means 'combine the initial of one syllable with a labial-initial syllable to form a syllable with medial -w-': e.g.,
1ɬiẹ + 1piẹ = 1ɬpiẹ > 1ɬwiẹ ̣
Could this suggest that -w- was [v] or [β] and that Tangut labials lenited in coherent speech (as opposed to words pronounced in isolation): i.e., 1ɬiẹ 1piẹ was pronounced [ɬiẹ viẹ] or [ɬiẹ βiẹ]?
Another possibility is that labials were followed by a subphonemic glide [w]: e.g., 1piẹ /piẹ/ was [pwiẹ] and
1ɬiẹ + [1pwiẹ] = 1ɬwiẹ
There was no contrast between /P/ and /Pw/ in Tangut.
That does not explain the highly anomalous fanqie for 2417 (which does not have a labial-initial final speller; moreover, its final speller has a different rhyme with the wrong tone!):
+
)
2417 1ʂwɨọ 'to need, want' = (0245 2ʂwɨi + 1449 2tʂhwɨoʳ̣̣) + 1223 2phɤo' (Tangraphic Sea 55.222)
Moreover, 1223 is redundant in cases like the one above and
=(
+
)
5679 1khwɤa 'remnants' = (2554 1khwɤe + 4314 1bɤa) + 1223 2phɤo' (Tangraphic Sea 26.211)
in which the initial speller has -w-. Perhaps this use of 1223 originated in fanqie for words like 0841 and was overextended.
Back to cognates: 0841 1ɬwiẹ could go back to *S-P-KE-la:
*S- conditioned the tense vowel
*P- conditioned -w-
*K- fused with *l- to form ɬ-*-E- conditioned the raising and breaking of *a to ie
The root *la would be shared with Old Chinese 邪 'awry' *sla (spelled 斜 from the 2nd century BC onwards for 'slanted'). But it is not clear if 邪 had an *l-root.
First, other *l-less reconstructions of 邪 are possible: e.g.,
*sja (Schuessler 2009 and this site)
*sə.ɢA (B&S 2014, which reconstructs the left side 牙 of 邪 as *m-ɢˤ<r>a; Schuessler 2009 reconstructs *ŋrâ and I reconstruct *ŋra)
Second, the lateral phonetic 余 *la of the later spelling 斜 is not strong evidence for an *l-root if
- Baxter and Sagart's *sə.ɢa is correct
- *l- had shifted to *ʑ- by the 2nd century BC
- *sə.l-, *s-l-, *s-ɢ-, and *sə.ɢ- had merged into something like *sj- or *zj- (i.e., a *ʑ-like cluster) by the 2nd century BC
However, Starostin reconstructed a different chronology in which laterals remained lateral as late as the 2nd century BC (i.e., during the Western Han):
邪 *lhia > 邪/斜 Western Han *lhia > Eastern Han *zhia
余 *dɮa > Western Han *la > Eastern Han *ʑa
Eastern Han transcriptions of Sanskrit y- are ambiguous. Starostin might have said that Chinese *ʑ- was used for Sanskrit y- because there was no *j-. On the other hand, Schuessler would say that Chinese *j- was used for Sanskrit y-.
14.10.15.23:20: BIRD WORDS
At the end of my last entry, I asked what 1223 was doing in this Tangut fanqie:
=(
+
1363 1swia 'time' = (5323 1swi + 0537 1pia) + 1223 2phɤo' (Tangraphic Sea 29.132)
The analysis of 1223 2phɤo' 'gentle, harmonious, together, pair' is unknown, but it looks like 'bird' + 'word':
=
+
It is in eight fanqie in the first and third surviving volumes of the Tangraphic Sea. It might have been in the lost second volume as well.
| Volume/Page/position | Tangraph | Li Fanwen number | Initial class | Rhyme | Reading (Nishida-style, Arakawa 1997) | Reading (this site) | Fanqie | Gloss | |
| initial | final | ||||||||
| 1.26.211 | 5679 | V | 1.18 | 1khamba | 1khwɤa | 2554 1khwɤe | 4314 1bɤa | remnants (only in dictionaries?) | |
| 1.29.132 | 1363 | VI | 1.20 | 1špwaɦ | 1swia | 5323 1swi | 0537 1pia | time, transcription character for Chinese 宣 *swiã, 修 *siu | |
| 1.55.222 | 2417 | VII | 1.48 | 1štšhor | 1ʂwɨo | 0245 2ʂwɨi | 1449 2tʂhwɨoʳ | to need, want | |
| 1.84.253 | 1029 | V | 1.80 | 1kwɑr | 1kwaʳ | 2503 1kʊ̣ | 5528 1baʳ | to cry, weep, sob | |
| 3.11.111 | 0732 | IX | 1.64 | 1hlwạ | 1ɬwiạ | 1770 1ɬwi | 5370 1piạ | ash, dust | |
| 3.11.122 | 3190 | 1.20 | 1ɬwaɦ | 1ldwia | 4226 1ldwị | 0537 1pia | tongue | ||
| 3.12.111 | 2238 | 1.67 | 1hlwị | 1ɬwị | 0239 1ɬiə | 5212 1pị | the surname Lhwi | ||
| 3.12.122 | 0841 | 1.61 | 1lwɛ̣ | 1ɬwiẹ | 2814 2ɬị | 3439 1piẹ | oblique, slanting, inclined | ||
What is the function of 1233? It can be translated into Chinese as 合 'together', the word used in Middle Chinese transcriptions of Sanskrit to indicate that two syllables were to be read as one: e.g.,
One might expect 1233 to appear in fanqie for Sanskrit transcription characters, but it doesn't; in fact, one of the fanqie is for the basic word 3190 1ldwia 'tongue'. Why wasn't its fanqie simply娑婆二合 *sa ba TWO TOGETHER for Sanskrit sva
4226 1ldwị + 0537 1pia
without 1233? Fanqie are by definition combinations of initials and finals; wouldn't 1233 be redundant?
In any case, 1233 is not a carryover from the Chinese lexicographical tradition, since 合 does not appear in Chinese fanqie.
1233 is interpreted in at least three ways in Arakawa's Nishida-style reconstruction:1. Read as a sequence of two syllables:
(1kĭɛ2 + 1mba) TOGETHER = 1khamba
This is the only disyllabic reading in Arakawa's Nishida-style reconstruction.
Why isn't the combination 1kĭɛ2mba or 1kamba (if the second rhyme is copied in the first syllable)?
2. Read as a combination of the initials of the two syllables and the rhyme of the second syllable:
(1swiɦ + 1paɦ) TOGETHER = 1špwaɦ
(2ši + 2tšhɔr) TOGETHER = 1štšhor (not 2štšhɔr!)
3. Redundant in the other five instances which might as well be normal fanqie
The first two interpretations are highly unlikely. I don't know of any transcriptions of 5679. And I doubt Chinese 宣 *swiã and 修 *siu would have been transcribed with a very un-Chinese cluster špw-.
So that leaves the third interpretation which is also unsatisfying. What, if anything, does 1223 indicate that differs these eight syllables from all others in the Tangraphic Sea? I can't help but fear that the instances of 1233 in the lost second volume might not shed light on this mystery.
14.10.14.21:04: A PHONETIC KEY TO TANGRAPHIC SEA RHYME 1.20
Nearly fifty years have passed since the Russian translation of the Tangraphic Sea, and the Chinese translation of that dictionary turned thirty last year. An English translation would be nice but perhaps also redundant since Tangutologists should be able to read Russian and/or Chinese. Of course, English would be nice for many non-Tangutologists. What I would like to see (and make) is a Tangraphic Sea with reconstructed character readings. Since I have been writing abou rhyme 20 syllables lately, here are the readings for the

rhyme 20 1sia 'to do (only in dictionaries?); transcription character for Chinese *sa, *sã and Sanskrit sa, sā'
entries in the first (level) tone* volume of the Tangraphic Sea. You can see the characters in Andrew West's online Tangraphic Sea. I have added the initial classes from Homophones. Groups are divided by circles in the original text.
| Page/position | Initial class | Group | Reading | Fanqie | Number of tangraphs | |
| initial | final | |||||
| 27.241-27.261 | I | 1 | 1pia | 2228 p- | 1216 | 6 |
| 27.262-28.111 | 2 | 1phia | 0797 ph- | 0618 | 4 | |
| 28.112-28.211 | 3 | 1mia | 5026 m- | 3583 | 17 | |
| 28.212-28.221 | III | 4 | 1tia | 5300 t- | 4620 | 2 |
| 28.222 | 5 | 1thia | 5671 th- | 1 | ||
| 28.231 | 1nia | 0635 n- | 3179 | 1 | ||
| 28.232 | V | 1kia | 1484 k- | 1 | ||
| 28.233-28.241 | 1gia | 2900 g- | 1693 | 2 | ||
| 28.251-28.262 | VI | 6 | 1tsia | 3031 ts-/dz- | 5 | |
| 28.271 | 7 | 1tshia | 3278 tsh- | 1 | ||
| 28.272-29.111 | 1sia | 4250 s- | 2 | |||
| 29.112-29.121 | VIII | 8 | 1ʔia | 5346 ʔ- | 4620 | 2 |
| 29.122 | IX | 9 | 1ldia1 | 0475 ld- | 3583 | 1 |
| 29.131 | 1ldia2 | 4464 ld- | 2019 | 1 | ||
| 29.132 | VI | 1swia | (5323 sw- + 0537) 1223 | 1 | ||
| 29.141-29.142 | 1tshwia | 0311 tshw- | 1289 | 2 | ||
| 29.143 | IX | 10 | 1lwia | 2302 lw- | 1825 | 2 |
The absence of classes II (v-) and VII (retroflex shibilants) is a trait of Grade IV rhymes.
Class IV (ɲ-?) is rare.Some groups divided by circles correlate with homophone groups (e.g., 1-4), but others don't: e.g., the fifth group is a mixture of class III and V syllables.
Fanqie initial speller 3031 is ambiguous (see "When Rhyme 21 Is Really Rhyme 20" and "When 1825 Is Really 1829"). I would not expect 3031 to represent dz- here, since dz-tangraphs were placed in the Mixed Categories volume of the Tangraphic Sea.
I see now that I mixed up the fanqie of 1829 and 1825 (as well as those characters themselves) last week. Great. For the record, the correct fanqie are
=
+
1829 'to heat up, burn' 1tshia = 3278 1tshi + 1693 1sia (Tangraphic Sea 28.271)
=
+
1825 is from 1829 with a prefix *P- in addition to the *Kɯ- that conditioned aspiration and vowel breaking:1825 1tshwia 'to roast, warm up' and 5041 1tshwia 'stove, furnace' =
0311 1tshwiə + 1289 1lwia (Tangraphic Sea 29.141-29.142)
*Kɯ-tsa > 1829 tshia
*P-Kɯ-tsa > 1825 tshwia
(The bare root is in Tibetan tsha 'hot' whose initial aspiration is secondary. More cognates here.)
5041 is presumably an extended use of 1825 (i.e., 'where food is warmed up', 'device for heating').
In theory one might expect only one fanqie final speller for all rhyme 1.20 syllables or two (one for -ia and another for -wia), but in fact there are ten! That does not mean there were ten subtypes of rhyme 1.20 syllables. Nearly all of those ten can be linked in a complex fanqie tree:
| 1693 | ||
| 3179 | 0618 | |
| 4620 | ||
| 3583 | 2019 | |
| 1216 | ||
| 0537 | ||
Members of that tree are in pink in the first table. (I have colored 0537 somewhat differently since it is followed by 1223. I will write about 1223 in my next entry.)
I placed 1693 at the root since its fanqie final speller is ... itself! 1693 is the final speller of 3179 and 0618, 3179 is the final speller of 4620 which is the final speller of 3583 and 2019, etc.
The final spellers 1289 and 1825 for -wia form a closed circle. 1289 is the final speller of its final speller 1825 (see above for the fanqie of 1825).
=
+
1289 1lwia 'lower limbs, legs' = 2302 1lɨə + 1693 1tshwia (Tangraphic Sea 29.143)
I don't know why 1363 swia wasn't spelled with either 1289 or 1829:
1363 1swia 'time' = 5323 1swi + 0537 1pia + 1223 2phɤo' (Tangraphic Sea 29.132)Next: What is 1223 doing in that fanqie?
10.14.21:21: The numbers at the ends of
1ldia1 'to come' and 1ldia2 'to return, transport'
indicate that they were treated as nonhomophonous (heterophonous - why isn't that word used more in linguistics?) in the Tangraphic Sea (and in Homophones!) even though their fanqie seem to indicate they are homophones. Their final spellers belong to the same tree (see above), and the initial speller of 1ldia2 is derived from the initial speller of 1ldia1. See "Come Again?" for details.
"1.20" in the title of this post refers to tone one, rhyme 20.
The Tangraphic Sea volume for the second [rising] tone has been lost. Rhyme 2.17 is the rising tone counterpart of rhyme 1.20. The rhyme numbers do not match since not all level tone rhymes have rising tone counterparts and vice versa: e.g., 1.6, 1.13, and 1.16 lacked rising tone versions. Arakawa (1997) lists rhyme 1.20 and 2.17 tangraphs side by side.
14.10.13.23:43: THE COMING CLAN
Yesterday I reconstructed a Tangut word for 'come' with ld-. Other words for 'come' have the same fanqie initial speller (0475), so they can also be reconstructed with ld-:
3456 1ldia < *Cɯ-La 'to come'
*C- might be the *S- conditioning vowel tension (indicated with a subscript dot) in the words below. *Sɯ- could have been lost after the vowel conditioned breaking (see below) but before *S- could condition tension.
Normally *ɯ conditions the breaking of *a to ɨa after *l-. Did *a break to ia after *L-?
4106 1ldɨə̣ < *S-Lə 'to come'
2373 1/2ldɨẹ < *Sɯ-La/ə-j(-H) 'to come'
The root vowel is ambiguous.
The Precious Rhymes of the Tangraphic Sea has two entries for this character, one in the level tone volume and the other in the rising tone volume. Although there are other characters with two readings, I don't know of any other case in which the two readings only differ in tone.
5727 1ldɨə̣ < *S-Lə 'to transport, come' (homophone of 4106; cf. how 3456 is nearly homophonous with 3502 'to transport', written as a mirror image of 5727 and derived from it:
=
+
)
I wrote the pre-Tangut source of ld- as *L-. External evidence may help us identify what *L- was. There are many Sino-Tibetan words for 'come' with l-; at least one (Mandarin 來 lai < *mʌ-rək) is not related to the others. Do the Tangut words belong to this clan of l-words? If so,
- do the other languages preserve a root-initial l- that gained a prefix in Tangut?
cf. how *d-l- became ld- in Tibetan (Jacques, "The Laterals in Tibetan")
- or does Tangut preserve a cluster reduced to l- in other languages?
- or are both Tangut ld- and non-Tangut l- from a third source in Proto-Sino-Tibetan?
14.10.12.18:15: COME AGAIN?
(23:09: The title refers to this idiom and to the fact that 3456 'come' is followed by 3502, another Tangut character containing it in Homophones.)
After two steps backward ... one step forward ... I hope.
In my last post, I mentioned
which has no homophones: it is in the isolated liquid-initial section of Homophones (A edition, 55A54).
+
3456 1lia (Grade IV) 'to come' = 0475 1liu (Grade IV) + 3583 1tia (Grade IV)
Right below it in Homophones (A edition, 55A55) is
which looks like 3456 'come' plus 'hand' and is derived from all of 'come' and the left side of 5727 1lɨə̣ 'transport, come' (also containing 'hand' and 'come' in reverse order) in Tangraphic Sea:
+
3502 1lia (Grade IV) 'to return, transport' = 4464 1lɨə̣ (Grade III) + 2019 1thia (Grade IV)
I have followed Gong who reconstructed 3456 and 3502 as homophones in spite of the fact that they are isolates. It would also be hard to distinguish them in context since both are motion verbs. But if they weren't homophones, what was the difference between them?
Could they have had different initials? Their initial spellers are of different grades (III and IV). So perhaps 3456 had Grade IV [l] whereas 4464 had Grade III velarized [ɫ]. If they had identical finals, I would have to posit a phonemic distinction between /l/ and velarized /ɫ/. Sofronov (1968 II: 308) reconstructed 3456 as 1la and 4464 as 1lda. But how could there be such a distinction if the two initial spellers were part of the same fanqie chain?
4464 1lɨə̣ (Grade III) = 0475 1liu (Grade IV) + 1493 siə̣ (Grade IV)
(There was no /ɨə̣/ : /iə̣/ distinction; the quality of the first vowel was dependent on the initial.)
Tai (2008: 201) reconstructed the initial of that chain as ld- since it was transcribed in Tibetan as ld- (11 times) and zl- (3 times), but never as a simple l- (Tai 2008: 198). That initial was transcribed in late 12th century northwestern Chinese as *l- which is not necessarily evidence for reconstructing Tangut l-. Chinese *l- would have been the best available substitute for an un-Chinese ld-. (There was no *d- in that Chinese dialect.) Hence there seem to have been two kinds of 1ldia.
I cannot reconstruct either 3456 or 3502 with -w- since the fanqie do not contain such a medial. The final spellers were transcribed in Tibetan without -w- (Tai 2008: 210):
3853: ta (37 times)
2019: tha (9 times)
3853 was also used to transcribe Sanskrit ṭa, ta, and tā without -v- (Sanskrit had no -w-).
The Chinese transcriptions 怛 *ta and 達 *tha for 3853 and 2019 lack *-w-.
None of the transcription evidence supports the -i- required by my Grade IV hypothesis or Gong's -j-. Sofronov's (2012) -a is much more likely for rhyme 20 which he regarded as Grade I, not IV. The l- from earlier in this post would be unusual before a Grade IV rhyme but normal before a Grade I rhyme. Sofronov (2012) sometimes reconstructed more than one value for a single Tangut rhyme, but rhyme 20 was not one of them. At this point I can only combine Tai's ld- with Sofronov's 1-a and be agnostic about the difference between the two 1lda-like syllables (3456 and 3502).