0219 2tseʳw 'whip'
14.10.4.23:57: ARE WHIPS LIKE HAIR?
It was fun to use tentative Unicode code points for Tangut characters and components in my last post, but now I'm going to use Li Fanwen 2008 numbers again.
I've been trying to figure out the graphic etymology of
0219 2tseʳw 'whip'
The left side is shared with 69 other characters which don't seem to have any phonetic or semantic similarity to 2tseʳw 'whip'. I'll look at them again and post a list tomorrow.
The center and right components appear in five other characters. I already mentioned the first yesterday:
| LFW2008 | Tangraph | Reading | LFW 2008 gloss | Character structure |
|
2061 |
|
2pɤẹ̃ | hair | left of 'hair' + left of another graph for 'hair' |
|
0227 |
|
2mioʳ | second syllable of 2177 0227 1pə 2mioʳ 'rude, coarse, careless' | 'language' + 'hair': i.e., coarse words are rude |
|
0350 |
|
2phʊ | boots worn in rain or snow | 'boots' next to 'hair': i.e., furry boots |
|
1889 |
|
2giu | silk, silkworm | 'bug' atop 'hair' (i.e., silk thread) |
|
1963 |
|
2ɬɤi | smooth, glossy | 'not' next to 'hair' |
If the right two-thirds of 0219 were taken as a unit, then 'hair' is the most likely source. Although a whip is not much like a hair, it is even less like 'rude', 'rain and snow boots', 'silk(worm)', or 'smooth'. Moreover, none of the five sound like 2tseʳw.
I'll break up that two-thirds and see if I can find more plausible graphic sources.
10.5.0:30: Are whips associated with hair on Google?
"whip like a hair": 0 results
"whips like hair": 2 results
"whips made of hair": 7 results
"hairs like whips": 229 results
"hairs whip": 374 results
"hair whips" 32,100 results
"hair like whips": 39,400 results
"whip hair": 62,200 results
"hair whip": 93,500 results
"hair like a whip": 273,000 results
Of course modern English usage is not the key to the ancient Tangut mind. Nonetheless, the whip-hair connection is stronger in the 21st century than I had thought.
14.10.3.23:51: UNICODE TANGUT COMING IN JUNE 2016
This has been an exciting week. First, Baxter and Sagart's new Old Chinese reconstruction, then the catalog of Khitan large script characters, and in less than two years, 6,126 Tangut characters plus the Tangut iteration mark and 753 Tangut radicals. Andrew West has documented the long road his team has taken. Bravo!
Finding Tangut characters is easy in Unicode. For example, if I want the first character I mentioned on Wednesday, I can just search for its Li Fanwen 2008 number (0219) on this code chart, and voila!
U+17366 2tseʳw 'whip'
And I can find the second character I mentioned on Wednesday (Li Fanwen 2008 number 1877) by looking through the range of characters sharing its left-hand radical U+1896E (= Nishida 219, gloss unknown). Oddly the source graph for its left side according to the Combined Homophones and Tangraphic Sea has a different radical (U+18954 = Nishida 218 'dog/fox'):
=
+
U+1785F 2ʔiəʳ 'whip' =
left (!) of U+175EF 2khɤi 'yak'
all of U+18571 2phʊ 'tree'
Why does 'yak' plus 'tree' equal 'whip'?
The analysis of U+17366 2tseʳw 'whip' is unknown. There are 69 other characters containing the component
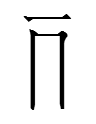
U+1892C (= Nishida 103, gloss unknown),
16 other chararacters with the middle component
U+18942 (= Nishida 275, gloss unknown),
14 other characters with the right-hand component
U+18975 (= Nishida 134, gloss unknown),
and five other characters containing the middle and right hand components: e.g.,
U+173F3 2pɤẹ̃ 'hair'.
Is a whip like a giant hair? Maybe. Or maybe there's a more likely source of the right two-thirds of U+1785F 2ʔiəʳ 'whip'. I'll look at the possibilities tomorrow.
14.10.2.23:59: THE KHITAN LARGE SCRIPT IN SRI LANKA
I never expected Khitan to be discussed in
Sri Lanka <ś.ri l.ang.k.a>
at WG2 meeting 63. To be more precise, it was the Khitan large script that came up, not the Khitan small script above. I'm much less confident about this attempt to write the name in the large script:

<ś(i) ri la ang ka>
Even if one or more of those characters turns out to be inappropriate for transcribing Sri Lanka, I'm certain that a large script spelling would take up more space than its small script equivalent since the former is not clustered into word blocks like the latter.
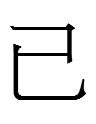
The first of the large script characters is identical to the Chinese character 已 pronounced i in Liao Chinese, the northeastern dialect known to the Khitan a millennium ago. Should Khitan large script characters be unified with Chinese characters in Unicode?
The unification was proposed to minimize the security issues caused by co‐existence of similar shaped characters in the CJK Unified Ideograph [i.e., Chinese character] block and Khitan Large Script block.
Not knowing what the security issues are, I oppose unification. Unifying Chinese characters and the Khitan large script would be like unifying Latin A, Greek Α, and Cyrillic А. Would Greek and Cyrillic lookalike letters (e.g., Γ and Г) be assigned to one or the other alphabet while letters unique to Greek or Cyrillic (e.g., Δ and Д) were assigned to separate alphabets? My mind reels.
I also don't think unifying Jurchen (large) script characters resembling Khitan large script characters is a good idea. To me, Chinese characters, Khitan large script characters, and Jurchen (large) script characters are like the Latin, Greek, and Cyrillic alphabets: related scripts that should be kept apart in spite of partial visual overlap.
Encoding issues aside, I've been excited to browse the longest list of Khitan large script characters I have ever seen:
(10.3.1.1:30: This last file does not include 已 <ś(i)> attested in the epitaph for 多羅里本 Duoluoliben [a.k.a. 突呂不 Tulübu, 1081], though it does include 己 [#1938] and 巳 [#1941] which also look like Chinese characters.)
I especially appreciate the inclusion of images of original characters. (10.3.0:06: But I wish I understood the codes for their sources.) I wanted to continue my series on Baxter and Sagart's new Old Chinese reconstruction, but I had to interrupt it to mention this breakthrough in Khitanology.
Alas, that list does not include any characters that Viacheslav Zaytsev may have discovered in Nova N 176, the longest known Khitan text in either script. As much as I'd love to be able to type the Khitan large script in Unicode as soon as possible, I wonder if it might be a good idea to wait until the characters in that book have been catalogued. It might be odd to have a first Khitan large script encoding covering all texts but Nova N 176. Typing words from what may be the most important Khitan text in the far future might involve going back and forth between a primary Khitan large script block and a Khitan Extended-A block. Awkward.
10.3.1:18: ADDENDUM: The Khitan large script proposal lists several inscriptions that I have never heard of before:
1. 耶律大王墓誌 Epitaph for Prince Yelü (personal name not given; 1051)
2. 耶律準墓誌銘 Epitaph for Yelü Zhun (1068)
3. 耶律李家奴墓誌銘 Epitaph for Yelü Li Jianu (1081)
4. 留隱太師墓誌銘 Epitaph for Master Liuyin (1109)
I wish I could see them.
14.10.1.23:59: GSR 0000 IN BAXTER AND SAGART (2014): PART 1
I didn't know Baxter and Sagart's new book Old Chinese: A New Reconstruction came out until it was released in the US yesterday, almost two weeks after it was released in the UK on 18 September. I'm not surprised it's sold out in the UK. I've waited years for it. I'll have to wait even longer because I can't afford it. But for now at least I can look at the reconstructions which the authors have kindly shared with the public (alternate URL). All reconstructions in this post are Baxter and Sagart's unless I state otherwise.
Will these reconstructions ultimately displace those of Karlgren's Grammata serica recensa (GSR, 1957)? We shall see.
For years I would recommend Schuessler's Minimal Old Chinese (2009) reconstructions to nonspecialists, as they incorporate many post-GSR elements widely accepted among scholars today (e.g., a six-vowel system) while excluding more controversial proposals. (I also recommend his Later Han Chinese in the same book. By definition it's too early to be Middle Chinese, but it's close, and I prefer it to nearly all Middle Chinese reconstructions I've seen.)
I dream of publishing my own reconstruction, but I really should finish my Golden Guide translation first, among many other things. I'd also like to publish a complete list of my readings of Tangut characters and the pre-Tangut sources of those readings. Both my Chinese and Tangut reconstructions have only been available in scattered form on this site and a couple of publications.
Enough about me. Let's start looking at Baxter and Sagart's Old Chinese reconstructions organized by GSR numbers. (Alas, the characters in the PDF are not directly searchable, though one can indirectly find them by searching for their Unicode code points.) At the top of the list are characters without GSR codes. Baxter and Sagart assigned them the number 0000.
The first character is 𠓥 *pe[n] 'whip', an alternate spelling of 鞭.
鞭 is a semantic-phonetic compound ('leather' + *be[n]) whereas 𠓥 is a compound of 攴 'strike' (itself a semantic-phonetic compound of 卜 *pˁok atop 又, a drawing of a hand) beneath something looking like 入 'enter' with a short horizontal line inside it. Those top components don't look like a pictograph of a whip to me, but I presume they're semantic. Another variant 𠓠 simply has 入 'enter' on top. See more variants here.
The brackets around the coda indicate that Baxter and Sagart "are uncertain about its identity". In this case, the coda might have been *-r. We know for sure that 'whip' ended in *-n in Middle Chinese, but Middle Chinese *-n could be from Old Chinese *-r as well as *-n*.
*pe[n] turns out to be an uncontroversial reconstruction. Pan, Zhangzheng, and Schuessler all reconstruct it as *pen. I am the odd man out, as my system requires a high vowel presyllable to account for the vowel breaking (partial vowel height matching) in Middle Chinese (MC):
*Cɯ-pen > *Cɯ-pien > *pien (= pjien in Baxter's MC transcription "not intended as a reconstruction")
My Old Chinese *pen without a high vowel presyllable (e.g., 邊 'side') remained *pen in Middle Chinese. Baxter and Sagart reconstruct 'side' as *pˁe[n] with a pharygealized *pˁ- that in my view blocked breaking. Such pharygealized initials distinguish their reconstruction from most others. I only reconstruct pharyngealization in Middle Old Chinese; it developed in (pre)initial** consonants preceding 'lower' vowels (*ʌ *e *a *o) and spread through the syllable:
*pen > *pˁen > *pˁeˁnˁ
On the other hand, my Old Chinese *Cɯ-pen was not subject to pharyngealization because its preinitial preceded the 'higher' vowel *ɯ. Pharyngealization and its absence conditioned vowel allophones that became phonemic after the loss of pharyngealization in Late Old Chinese (OC):
| Graph | Baxter and Sagart's OC | This site | Baxter's MC | ||
| Early OC | Middle OC | Late OC, MC | |||
| 𠓥/鞭 | *pe[n] | *Cɯ-pen | *Cɯ-pien > *pien | *pien | pjien |
| 邊 | *pˁe[n] | *pen | *pˁen > *pˁeˁnˁ | *pen | pen |
*10.2.0:51: I reconstruct *-n unless (1) a phonetic series or word family also contains Middle Chinese *-j readings pointing to *-r and/or (2) external evidence points to *-r. Baxter and Sagart's policy of reconstructing is safer since there is no guarantee that all Old Chinese *-r belonged to such phonetic series or word families and/or can be reconstructed on the basis of external evidence.
I have not found any true cognates of the Chinese word for 'whip'; all lookalikes in the region are borrowings.
The Tangut words for 'whip' are completely different:
0219 2tseʳw < *T-tse(k/w)H (common) and 1877 2ʔiəʳ < *T-ʔəH or *ʔərH (only in dictionaries?)
**10.2.1:02: Preinitials are onsets of unstressed presyllables whereas initials are onsets of stressed syllables. Hence the preinitial of *Cɯ-pen was *C- (an unknown consonant) and its initial was *p-. The height of the vowel after the first consonant in a (sesqui)syllable conditioned the presence or absence of pharyngealization in Middle Old Chinese.
I suspect that uvular initials always conditioned pharyngealization regardless of the following vowel unless preceded by a high vowel presyllable, but I have not yet investigated that hypothesis:
*qi > *qˁi (but *ki > *ki)
*Cʌ-qi > *Cˁʌˁ-qˁeˁiˁ > *kei (same outcome as *Cʌ-ki)
*Cɯ-qi > *Cɯ-ki > *ki (same outcome as *Cɯ-ki)
14.9.30.23:40: STILI IN OFFORD AND GOGLITSYNA (2005)
Offord & Gogolitsyna (2005; hereafter OG) is the first book of Russian for foreign learners that I have ever seen with extensive coverage of variation in Russian. Although Japanese is well known for its complex speech levels, I was surprised tonight to find that McClure's (2000) book on Japanese in the same series covers the same topic in a 33-page chapter that is less than half as long as OG's two chapters combined (72 pages). I think it would be possible to write a full-length book on variation for learners of Japanese. OG identify three registers of Russian. I have grouped their lowest varieties into a fourth register ranked below their first register (R1):
R0: Subcolloquial
Demotic, youth slang, prison slang, thieves' cant, vulgar language
R1: Colloquial
Everyday spoken conversation. I would have extreme difficulty making out compressed forms such as monosyllabic [grʲu] for trisyllabic говорю 'I say' (p. 10). I have wondered how learners cope with compression in English.
R2: Neutral
"This is the norm of the educated speaker, the standard form of the language that is used for polite but not especially formal communication [...] It is the register that the foreign student as a rule first learns and which is most suitable for his or her first official or social contacts with native speakers. [...] This register is perhaps best defined in negative terms, as lacking the distinctive colloquial features of R1 and the bookish features of R3" (p. 14)
R3: Higher
a. Academic/scientific
Apart from textbook Russian, this is the style I am most acquainted with. OG noted the feature that stands out in my mind:
Various means are used to express a copula for which English would use some form of the verb to be, e.g. состои́т из [consists of], зaключáeтся в [concludes in], прeдстaвля́eт собо́й [presents itself as], all meaning is (4.2). (p. 15)
All three expressions for 'is' can be found in Zaytsev (2011)'s paper on Khitan. (Can be found is itself a bookish synonym for is in English.)
b. Official/business
c. Journalism/political debate
Literary and online language can mix elements from across the above spectrum.
OG also discuss regional variation.
All that makes me ponder how little is known about Tangut, Jurchen, and Khitan. I suspect that Tangut words only appearing in odes and dictionaries are from a traditional, colloquial register whereas the bulk of surviving Tangut texts are in an elevated, Chinese-influenced register. Even less is known about Jurchen and Khitan. Surviving texts in those languages are largely in inscriptions representing a 'monumental' register. One huge possible exception is the Khitan book that Zaytsev (2011) identifed; it may have been written in a different style.
14.9.29.23:59: NOT BEING THERE ANYMORE: RUSSIAN GERUND VARIANTS
Russian has several types of gerund suffixes. Six books for English-speaking learners include notes on when to use them:
| Aspect | Suffix | Example | Reiff (1883: 181) | Forbes (1916: 171) | Arant (1981: 119) | Pul'kina & Zakhava-Nekrasova (1992: 371) | Offord & Gogolitsyna (2005: 328) | Wade (2011: 386, 389) |
| Imperfective | (-shibilant) -я / (+shibilant) -а | встречая 'meeting' | "written tongue" | |||||
| (consonant +) -учи / (vowel +) -ючи | встречаючи 'meeting' | "familiar language" | "peasants", "popular poetry" | not mentioned; even будучи 'being' is absent | "popular parlance"; "generally avoided in the
modern literary language" with the sole exception of будучи 'being' |
only будучи 'being' | only будучи 'being', three others* | |
| Reflexive imperfective | (-shibilant) -ясь / (+shibilant) -ась | встречаясь 'meeting' | ||||||
| Perfective | (-shibilant) -я / (+shibilant) -а | войдя 'having entered' | "common with reflexive verbs" | |||||
| (vowel +) -в | встретив 'having met' | "written tongue" | interchangeable | "preferred in written styles" to -я/-а | ||||
| (vowel + ) -вши | встретивши 'having met' | "familiar language" | "peasants", "popular poetry" | "less frequently" used than -в | "archaic flavour"; "may also occur" in "the colloquial register"or "demotic" | not mentioned | ||
| (consonant +) -ши | вошедши 'having entered' | "rarely used" | ||||||
| Reflexive perfective | (-shibilant) -ясь / (+shibilant) -ась | разбредясь 'having wandered in different directions' | ||||||
| (vowel + ) -вшись | встретившись 'having met' | |||||||
| (consonant +) -шись | ведшись 'having been in progress' | |||||||
Comments:
1. Is -учи /-ючи still in "popular parlance" today?
Google Ngrams has no data for встречаючи, so here are two more pairs of gerunds:
читая vs. читаючи 'reading' (the former is always more common)
делая vs. делаючи 'doing' (ditto)
The title refers to the most common surviving -учи /-ючи gerund in Будучи там, the Russian title of Being There (1979). Будучи 'being' has 4.99 million Google results. See below for the Google statistics of other -учи /-ючи gerunds mentioned in Wade (2011).
2. I am surprised that the perfective gerund suffix -а/я is still around. It could be confused with the homophonous imperfective gerund suffix (though the latter attaches to many more stems). And yet войдя 'having entered' is much more common than its synonym вошедши in Google Ngram Viewer. (There is no risk of confusing inflected imperfective and perfective gerunds [i.e., stem-suffix sequences] as opposed to suffixes in isolation as long as each aspect has a different stem: e.g., the imperfect gerund corresponding to войдя/вошедши 'having entered' is входя 'entering' with a different stem вход-.)
3. I am also surprised that -вши is in decline (Wade does not even mention it!) though its reflexive counterpart -вшись is common.
In short, I would expect the imperfective and perfective gerund suffixes to be maximally differentiated over time and internally consistent:-я(сь)/-а(сь) vs. -(в)ши(сь)
But that's not the case!
9.30.1:36: Added a column for Offord & Gogolitsyna (2005: 328) and Google Ngrams links.
едучи 'traveling' "is sometimes found in poetic or folk speech" (p. 386; 97,300 Google results)
жить припеваючи 'to live in clover' (p. 386; 124,000 Google results)
крадучись 'stealthily' (p. 394; 391,000 Google results)
14.9.28.23:14: TRANSCARPATHIAN RUSYN MASCULINE 'JA-NIMATES'
The Transcarpathian Rusyn (TR) and Prešov Rusyn (PR) masculine animate declension in Magocsi (1979: 83) and Magocsi (1979: 83) is straightforward in the singular: all endings are added to an invariable stem brat-:
| Case | Proto-Slavic | TR | PR | Ukrainian | Belarusian | Russian | Serbo-Croatian | Polish | Slovak | Czech |
| nominative | *bratrŭ | brat | bratr | |||||||
| genitive | *bratra | brata | bratra | |||||||
| dative | *bratru | bratu, bratovy | bratovi | bratu, bratovi | bratu | bratovi | bratru, bratrovi | |||
| accusative | *bratrŭ | brata | bratra | |||||||
| instrumental | *bratromŭ | bratom | bratam | bratom | bratem | bratom | bratrem | |||
| locative | *bratrě | bratu | bratovi | brati, bratovi | bracie | brate | bratu | bracie | bratovi | bratru, bratrovi |
| vocative | *bratre | brate | bracie | - | brate | bracie | - | bratře | ||
| Case | Proto-Slavic | TR | PR | Ukrainian | Belarusian | Russian | Serbo-Croatian | Polish | Slovak | Czech |
| nominative | *bratri | bratȳ | braty | braty | brat'ja | braća | bracia | bratia | bratři | |
| genitive | *bratrŭ | bratüv | brativ | brativ | bratoŭ | brat'jev | braće | braci | bratov | bratrů |
| dative | *bratromŭ | bratüm, bratjam | bratom | bratam | brat'jam | braći | braciom | bratom | bratrům | |
| accusative | *bratry | bratüv | brativ | brativ | bratoŭ | brat'jev | braću | braci | bratov | bratry |
| instrumental | bratamy | bratami | brat'jami | braćom | braćmi | bratmi | ||||
| locative | *bratrěchŭ | bratjach | bratoch | bratach | brat'jach | braći | braciach | bratoch | bratrech | |
| vocative | *bratri | braty | - | braty | - | braćo | bracia | - | bratři | |
The TR dative and locative plurals resemble the Russian plurals, but that must be a coincidence, as TR is not contiguous with Russian; it is spoken in the Transcarpathian Oblast' "which borders upon four countries: Poland, Slovakia, Hungary, and Romania." I wonder if those TR ja-plurals were influenced by Polish whose ci is from *tj. The TR nominative plural is unlike those of Polish or Slovak.
TR bratüm < *bratomŭ may be an older TR dative plural or a very old borrowing from Slovak predating *o-fronting and *-ŭ-loss.
Moreover, the Russian plural forms are based on an old feminine collective which must have replaced an earlier regular masculine plural *braty still preserved in the other East Slavic languages. On the other hand, all non-j TR forms are from brat- rather than the feminine collective *bratĭja.
The Serbo-Croatian 'plural' braća 'brothers' is still a feminine collective singular unlike Russian brat'ja which takes plural endings except in the old nominative singular (now reinterpreted as a plural). Hence none of its endings are cognate to those of the original masculine plurals.
Polish has a mixture of old singular and plural forms of that collective. I assume the old feminine accusative singular *bracię has been replaced by the old feminine genitive singular braci to conform to the genitive-as-accusative pattern of masculine animates. (23:30: The old feminine vocative singular would have been *bracio; it has been replaced by the old nominative singular since masculine plurals have identical vocatives and nominatives.)
Slovak combines that collective (reinterpreted as a masculine plural) in the nominative with forms of brat- in all other cases.
Notes on other forms
Stem: Only Czech preserves the second *-r-.
Nominative/accusative singular: Originally identical but differentiated later when the genitive was used as the singular. See Schenker (1993: 108).
Dative/locative singular: Apparently partly merged in TR and Ukrainian. Fully merged in PR, Slovak, and Czech. Dative for locative reminds me of the dative after German prepositions.
What is the origin of -ovy/-ovi?
PR y normally does not correspond to Ukrainian i. Why does PR have -y instead of -i?
Instrumental singular: Did Polish and Czech generalize -em from other paradigms? Czech -em in this paradigm must postdate *r shifting to ř before *e (a change visible in the vocative).
Belarusian unstressed *o became a.
Nominative plural: In spite of my transliteration, TR/PR bratȳ [bratɨ] is homophonous with Belarusian braty [bratɨ] but not Ukrainian braty [bratɪ].
Genitive plural: Originally homophonous with nominative and accusative singular. How did *-ovŭ (the source of most forms above) and *oː (the source of Czech ů [uː]) develop?
The *o before *ŭ fronted to ü in TR and lost its rounding in PR and Ukrainian.
*-v became Belarusian -ŭ.
Russian -ev is an allomorph of -ov after -j-.
Dative plural: Is -a- instead of -o- in most of East Slavic other than TR and PR by analogy with the instrumental -ami?
Is PR bratom due to Slovak influence postdating the *o > i shift before *ŭ?
Is TR bratüm due to Slovak influence predating *o-fronting?
Accusative plural: Czech preserves the original homophony of accusative and instrumental plural. All other modern languages have accusative plurals from genitive plurals.
Instrumental plural: Schenker (1993: 89) could not explain the original ending *-y. It was replaced by -mi endings by analogy with other declensions.
-a- in East Slavic could be from the -ami of the -a-declension.
Locative plural: Is Czech the only language in the table with a reflex of *ě? Most of East Slavic seems to have generalized -a- from the instrumental and/or dative plural. Polish braciami has the -ami of an a-declension instrumental plural. Slovak may have generalized -o- from the genitive/accusative and/or dative plural. PR o must be from the dative plural since *o borrowed from the old genitive/accusative plural *-ovŭ would have fronted to *i.
9.28.23:57: I forgot to ask if the -j- in TR bratjam and bratjach is in all masculine consonant-final dative and locative plural forms or is only in a subset of those forms. I could answer my own question by looking for all masculine consonant-final dative and locative plural forms in Magocsi (1979), but my copy is not machine-searchable, and that would be time-consuming. My guess is that (1) TR brat belongs to a small class of masculine animate nouns which once had alternate plurals based on feminine singular collectives and (2) all other TR masculine animate nouns share the endings -am and -ach with masculine inanimates and neuters.