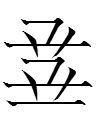


14.4.5.23:55: FROM FATHER TO UNCLE
I think Proto-Indo-European *pʕtḗr 'father' could have become something like *poti in Proto-Slavic*, but in fact Proto-Slavic had a different word *otьcь for 'father', and according to Schenker (1993: 113), the Indo-European word for 'father' became Proto-Slavic *strъjь 'paternal uncle' (presumably from *s- + zero grade *ptr- + -ъjь). I have three questions about *strъjь:
1. Is the initial *s- s-mobile?
2. What is the suffix *-ъjь?
3. What other languages shifted 'father' to 'uncle'? Or 'mother' to 'aunt'?
*Cf. Proto-Slavic *mati 'mother' from *méʕtēr.
14.4.4.23:52: ĐER(I)VЬ-ATION
I am puzzled by the Glagolitic letter Ⰼ for several reasons (not even including the derivation of its form!):
1. Why does it exist? Wikipedia lists its sound value as /dʑ/, though that phoneme did not exist in Old Church Slavonic.
2. Does it really correspond to modern Serbo-Croatian ћ ć, its voiced counterpart Serbo-Croatian ђ đ, and Macedonian ѓ ǵ, as Wikipedia implies? None of those three sounds existed in Old Church Slavonic.
3. Why does its name (đervь ~ ǵervь 'tree') have initial đ- (see the Croatian Wikipedia) or ǵ- (both sounds that did not exist in Old Church Slavonic!) if no Slavic word for 'tree' has similar initial consonants: e.g., Serbo-Croatian and Macedonian drvo (not SC *đrvo or M *ѓрво *ǵrvo)?
(4.5.0:05: Moreover, why does its name end in -ь if Slavic words for 'tree' end in -o?)
3'. And why does Old Church Slavonic have дрѣво drěvo with ě if Proto-Slavic had *dervo with e?
4. Cubberley (1993: 24) listed ћ (transliterated as ǵ/j, not ć) as the early Cyrillic equivalent of Ⰼ, and questions 1 and 2 apply to ћ as well as Ⰼ.
On the other hand, Wikipedia does not mention ћ in its article on the early Cyrillic alphabet, though its article "Tshe" (ћ) does mention that the later Cyrillic letter ћ ć was based on the earlier Cyrillic letter ћ ǵ/j. Oddly the article on "Dje" (ђ), an obvious derivative of ћ, does not mention either ћ.
14.4.3.21:52: THE VÖWELS OF PREKMÜRŠČINA
Two days ago, I asked about Slovene surnames with ü which I thought was un-Slovene. It's actually un-standard Slovene. I forgot that I read in December about how some Slovene dialects have front rounded vowels: e.g., that of Prekmurje, where Albina Nećak Lük is from (and where Danilo Türk's ancestors might be from; his native Maribor is "where significant immigrant communities from Prekmurje have settled"). I was reminded of that fact by the last line of the Lord's Prayer in Prekmurje Slovene on p. 273 of Francis Tapon's The Hidden Europe:
Prekmurje: nego odslobodi nas od hüdoga
Standard: temveč reši nas hudega
'but deliver us from evil'
I assume those front rounded vowels are due to Hungarian and/or German influence since Prekmurje borders Hungary and Austria. What I don't understand is how they developed in native words. In some cases, they seem to reflect nearby palatal segments: e.g.,
P odpüščamo 'we forgive' with ü before š (cf. standard odpuščamo)
P hüdoga < *hudega 'evil'? (assuming the standard form is more conservative)
Presumably ö is always conditioned (by some palatal segment?) since it is nonphonemic according to Wikipedia.
On the other hand, ü is presumably phonemic because it is unpredictable: e.g., it appears in the river name Müra (standard Mura) which contains no palatal segments other than ü.
The unusual vocalism of Prekmurje is not limited to front rounded vowels: e.g., it has au or ou from earlier *o and *ǫ: e.g.,
'God': Baug ~ Boug < *bogъ
'road': paut ~ pout < *pǫtь
I presume this shift postdated the merger of *o and *ǫ. But why did some *o break while others didn't? Is accent a factor?
14.4.2.23:52: THE SERBO-CROATIAN CASE -GA-ME
Vowel correspondences between Slavic languages are generally very straightforward, so I'm frustrated by how Serbo-Croatian and Slovene third person pronoun and adjective case endings don't quite line up with their equivalents elsewhere. Unexpected vowels are in red.
| masculine/neuter singular | Proto-Slavic | Serbo-Croatian | Slovene | Polish | Russian | |
| pronoun 'he', 'it' |
accusative/genitive | *jego | njega | njega | jego | jego |
| clitic* accusative/genitive | (*go) | ga | ga | go | n/a | |
| locative | *jemь | njemu | njem | nim | nem | |
| dative | *jemu | njemu | jemu | jemu | ||
| clitic dative | (*mu) | mu | mu | mu | n/a | |
| adjective 'new' | accusative (masculine animate), genitive | *nova-jego | novog(a) | novega | nowego | novogo |
| short genitive | *nova | nova | n/a | |||
| locative | *nově-jemь | novom(e/u) | novem | nowym | novom | |
| dative | *novu-jemu | novemu | nowemu | novomu | ||
| short locative | *nově | novu | n/a | |||
| short dative | *novu | |||||
(I have left out masculine inanimate and neuter accusative forms for 'new' since they are regular.)
Today I realized that the unexpected Serbo-Croatian and Slovene accusative/genitive a might be by analogy with the genitive ending -a in masculine and neuter o-stems (e.g., mesto 'place', 'town') and short adjectives (e.g., *nova).
*nova-jego města > SC novog(a) m(j)esta 'of the new place', Sl novega mesta 'of the new town'
Did this analogy occur
- indepedently in Serbo-Croatian and Slovene?
- in a common ancestor of Serbo-Croatian and Slovene (Proto-Southwestern Slavic as opposed to Macedonian and Bulgarian)?
- in Proto-South Slavic (and if so, are a-forms attested in earlier Bulgarian and Macedonian)?
Could the unexpected Serbo-Croatian dative-locative e also be due to analogy? If so, what would be the model? Proto-Slavic masculine and neuter o-stems had a locative ending *-e. Were forms like novome first created at a time when Serbo-Croatian masculine and neuter o-stems (e.g., mesto 'place') and short adjectives (e.g., *nově) still had an *-ě-like locative? (Those stems now have -u for both dative and locative.)
*u nově-jemь městě > *u novome m(j)est(j)e? > SC u novom(e) m(j)estu 'in the new place'
*4.3.19:00: Wiktionary does not reconstruct clitic forms for the third person pronoun, but I have done so because nearly identical clitics are attested in all three branches of Slavic. (No standard East Slavic language has them, but ho < *go and mu are in nonstandard Ukrainian [Shevelov 1993: 960].) It's possible that all three branches (or even languages within them) independently dropped the first syllables of the third person pronouns to form the clitics, but is it probable?
4.3.22:18: When I first saw Serbo-Croatian -ga, I thought of how unstressed Russian -го is pronounced [və] and assumed that Serbo-Croatian a was also the product of vowel reduction. But I later rejected that idea because as far as I knew, the reduction of *o was unique to Russian and Belarusian. (Belarusian has -га [ɣa] corresponding to Russian -го [və] and SC -ga.) However, *o-reduction is actually more widespread that I thought: it's also in Upper Carniolan Slovene and Smolyan Bulgarian. Wikipedia reports akan'e (vowel reduction to a) in Polissian Ukrainian whose eastern variety is transitional with Russian, so I assume it has Russian-style *o-reduction (rather than Belarusian-style *o and *e-reduction). Nonetheless that wider distribution doesn't necessarily mean my original guess was correct. As far as I know, akan'e is completely unknown in Serbo-Croatian.
14.4.1.23:06: LÜK-ING TÜRK-ISH
Tonight I rediscovered my copy of Language in the Former Yugoslav Lands. The name of the author of the chapter on Slovene caught my eye: Albina Nećak Lük. Neither ć nor ü are in Slovene. Ć is in Serbo-Croatian (and nećak is Serbo-Croatian for 'nephew' - a coincidence?), but ü is in neither Slovene nor Serbo-Croatian. Lük is from Prekmurje, where "[p]eople of different languages, Slovene, Hungarian, German, Romani, Yiddish, live in close contact for centuries". Is Lük a Hungarian or German name?
The umlaut in Lük reminded me of another name from Slovenia that puzzled me: Danilo Türk. I thought I might have already written about Türk, but Google tells me I haven't. In any case, these folks wrote about it years before I ever heard of him. The first post in that thread quotes this article.
I wonder how the average Slovene pronounces ć and ü. Are they consistently distinguished from native č and u? If not, who distinguishes them and who doesn't?
14.3.31.23:59: "A TIME FOR TRUTH-TELLING"
Joanne Jacobs wrote thatMarch 31 is my birthday, a time for truth-telling.
I tried to translate the latter phrase and came up with
1ʐɨəʳ 1tshiee 2ziọ 'truth speak time'
That got me thinking about two of the various Tangut words for 'time':
0705 1ziẹ and 4861 2ziọ
Although their characters are completely different, they are phonetically similar and exhibit an e ~ o alternation almost always otherwise found in verbs. (See below for the only other example with nouns that I know of.)
Jacques (2009) regarded that e ~ o alternation as the result of suffixation. (I have converted his reconstruction into mine; the basic principle is the same.)
0749 *CI-pha > 1phi 'to send, cause' (stem 1*; no suffix)

4568 *CI-pha-w-H > 2phio 'to send, cause' (stem 2; suffixed)
Jacques regarded *-w as a third person patient suffix with a cognate -w still in northern Qiang today.
(The function of *-H which conditioned the second tone is unknown. Not all second stems have the second tone.)
By analogy I could reconstruct the two words for 'time' as *SE-Sa and *SE-Sa-w-H.
*S- conditioned vowel tension (indicated by a subscript dot)
*-E- conditioned the raising of *-a to *-ia and later -ie; it and *-a conditioned the intervocalic lenition of an earlier sibilant *-S- to -z- (phonetically [ɮ]?)
But there are limits to analogy. The *-w in 'time' obviously cannot be a third person patient suffix. What is it? Could it be from an earlier *-k? Or is 'time' a true case of ablaut: i.e., primary vowel alternation as opposed to secondary vowel alternation?
(4.1.0:55: Yet another solution is to assume that the original root vowel was *o and the -e-form is from *-o plus a suffix *-j:
*Sɯ-So-H > 2ziọ
*Sɯ-So-j > 1ziẹ
However, that begs the question of what *-j is. I have reconstructed the presyllabic vowel conditioning later -i- as *ɯ, since the frontness of -e is due to *-j. Unlike *E, *ɯ did not cause stressed vowels to front.)
A pair of nouns with a similar alternation* is
1591 2nie 'language' and 1824 2nwio 'word'
Is the semantic difference between those nouns comparable to that between the two words for 'time' (e.g., time as a whole vs. a point in time)? Tangut has many apparent synonyms whose distinctions are not yet fully understood.
*Jacques (2009: 3) explained the difference between stems 1 and 2:
Stem 2 is used when the verb’s subject (that is, A for a transitive verb or S for an intransitive one) is 1Sg or 2Sg and the patient is third person (Gong 2001:26). Stem 1 occurs in all other cases, including those when a 1sg or 2sg agreement suffix appears but is coreferent with the patient of the verb (Gong 2001:32-34).
**4.1.1:00: Unlike the words for 'time', 'language' and 'word' share the same tone, and 'word' has a medial -w- conditioned by a *P-prefix.
14.3.30.18:07: YERNAZ RAMAUTARSING
I first heard about Yernaz Ramautarsing today through Bosch Fawstin. I've been trying to find the derivation of his name.
Ramautarsing is a Hindi compound of three elements of Sanskrit origin:
राम Rām 'Rama'
औतार autār 'avatar'
सिंह Siṃh 'lion'
When I Googled Yernaz, the results not involving Ramautarsing were mostly ... Kazakh! According to name.kazakh.ru, ер yer is 'hero'* and наз naz is a loan from Persian (presumably ناز nāz 'glory'). Did this Turco-Persian hybrid spread into India before arriving in Suriname where Ramautarsing was born?
*I'm surprised I can't find the Kazakh word in this entry for Proto-Turkic *ēr 'man'. (Also see Clauson 1972: 192.)
14.3.30.6:06: A KHIOOR-IOUS KHAN-UNDRUM
There are only three tangraphs with the element vai:
=
+
1018 1lwo 'moist' (vemvai) =
left of 0642 2lõ 'origin' (vemjolcon; phonetic) +
center of 3052 1niooʳ 'water (trigram ☵)' (cirvaigii; semantic)
=
+
3052 1niooʳ 'water (trigram ☵)' (cirvaigii) =
left of 3058 2ziəəʳ 'water' (cirzaa; semantic) +
right of 1018 1lwo 'moist' (vemvai; semantic) +
right of 5941 1diə̣ 'strip' (pargii; why?)
=
+
4754 1khiooʳ (Sanskrit transcription) (biobuxvai) =
top and left of 4807 1khi 'to lose' (biobuxpik; initial) +
center of 3052 1niooʳ 'water (trigram ☵)' (cirvaigii; rhyme)
As I wrote in my last entry, 1018 "is clearly a phonosemantic compound," though I don't understand why its semantic component is vai instead of the much more common radical cir 'water'.
3052 is probably a semantic compound. 5941 'strip' might be a reference to how trigrams look like strips, though its components par and gii are absent from the tangraphs for the seven other trigram names:
3950 1tshwiu 'heaven (☰)' (girdexgie)
3389 2ŋiõ 'mountain (☶)' (dexfei)
2777 1ŋeʳw 'thunder (☳)' (dexdukcin)
1995 2məi 'wind (☴)' (biidexdak)
4555 1pə 'fire (☲)' (qeucok)
3910 1phəu 'earth (☷)' (girges)
1976 2bie 'swamp (☱)' (baebeldexbel)
4754 is a fanqie character for Sanskrit transcription according to both the Tangraphic Sea and Homophones. I would expect it to transcribe a Sanskrit phoneme sequence khyor [kʰjoːr] corresponding to its reading 1khiooʳ. However, the only Sanskrit khyor I know of is the genitive and locative dual of sakhi- 'friend', its compounds, and a few rare -khi nouns before a voiced segment. Would the Tangut really create a special tangraph for such forms? Or am I overlooking a common verb form, dharani, or mantra with khyor?
Perhaps my slight rewriting of Gong's Tangut reconstruction is wrong. Arakawa (1997: 149) reconstructed 4754 as khya:n. Monier-Williams' Sanskrit dictionary has 156 nouns with -khyān-; 124 end in khyāna-. However, according to Arakawa (1997: 117), 4754 transcribed Sanskrit khan and khyan, not khyān! That is hard to reconcile with the Chinese transcription 娘 *ndʐɨo for 3052 which rhymes with 4754. The only way out I can see is to reconstruct a -(y)an-like reading which shifted to an -o-like reading by 1190 when 3052 was transcribed in the Pearl.











