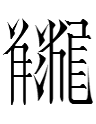
6066 1tʂɨụ (transcription character)
13.11.2.23:59: DRÔU-NING IN SOR-RƯỢU
At the David Thomas Library last night, I found Kenneth D. Smith's (1976) Sedang language lessons. The word drôu 'wine' on page 2 got me thinking about the origins of its Vietnamese translation rượu. For a long time I assumed it was somehow related to Chinese 酉 and 酒 (more about them in my next post), but now I think it is ultimately from Early Old Chinese 醪 *kʌ-ru 'spirits with sediment'. The low front vowel of the presyllable conditioned partial lowering of the main vowel:
*kʌ-ru > *kʌ-rou > *kʌ-rau
In mainstream Chinese, the presyllable was lost after lowering and *r- became *l-:
*kʌ-rau > *rau > *lau (> modern Mandarin láo, etc.)
Vietnamese borrowed *rawʔ from a southern Late Old Chinese dialect which had a final glottal stop (suffix?). *a later broke to ươ [ɨə] in this and other words of both Chinese and non-Chinese origin: e.g.,
Đường 'Tang Dynasty', borrowed from Late Middle Chinese *daŋ
đường 'road', borrowed from Proto-Tai *daŋ? (cf. Tho taːŋ34; 11.3.1:39: Sidwell's [2010] Proto-Palaungic *ɗeeŋ may be an unrelated lookalike)
lưõi 'tongue' (cf. Thavung lás)
người 'person' (cf. Ruc ŋàːj)
xương 'bone' (cf. Ruc sàːŋ)
Pulleyblank proposed that the breaking was due to Chinese influence. Vietnamese speakers heard *[ɨə] from Chinese speakers and might have pronounced this prestigious foreign diphthong *[ɨə] instead of *a in native and borrowed words.
Kra-Dai language(s?) on the other hand borrowed from a different southern Late Old Chinese dialect which also had a final glottal stop (suffix?) in 'spirits' but retained a trace of its presyllable:
*kʌ-rau-ʔ > *krauʔ > *klauʔ > *xlauʔ
This *xlauʔ underlies Proto-Kam-Sui *khlaːu3 (Thurgood 1988) and Proto-Tai *ʰlawC (Pittayaporn 2009: 338). I don't know whether Proto-Kam-Sui and Proto-Tai borrowed those words independently or if a common ancestor borrowed them. In either case, 醪 is not the source of all Kra-Dai words for 'liquor': Proto-Kra *pluA and *C-kaC 'liquor' (Ostapirat 2000: 232), pre-Proto-Hlai *C-biːŋɦ (Norquest 2007: 519) 'rice wine', and Lincheng Be jan3 (Liang and Zhang 1997: 236) are not related.
The *k-/*x- of the above forms does not match the d- of Sedang drôu 'wine' which happens to resemble Old Chinese 酎 *druʔ 'new spirits'. I am inclined to regard Sedang drôu 'wine' and Ngeq riːw 'rice wine' as coincidental lookalikes since those Mon-Khmer languages were not in contact with Chinese (though borrowing through intermediaries cannot be ruled out).
If 酎 *druʔ 'new spirits' is cognate to 醪 *kʌ-ru 'spirits with sediment', maybe the former goes back to *N-tʌ-ru-ʔ, and Vietnamese rượu might be from southern Chinese
*N-tʌ-ru-ʔ > *N-tʌ-rouʔ > *N-tʌ-rauʔ > *rauʔ
whereas mainstream Chinese forms like modern Mandarin zhòu are from
*N-tʌ-ru-ʔ > *Ntruʔ > *Ndruʔ > *druʔ
which lost the presyllabic vowel *ʌ before it could condition main vowel lowering.
11.3.1:15: On the other hand, the Muong dialect recorded by Sokolovskaya and cryptically labeled "ANNG" (short for a location named An Ng ...?) in Peiros' database has hraw5 'beer' whose initial may point to *hr- from *kʌ-r- rather than *N-tʌ-r-. However, tone 5 may point to a proto-voiced initial. Oh wait, it turns out that the database has no examples of r- in that Muong dialect. Perhaps all *(h)r- became hr- in that dialect, just as all *r- became Classical Greek rh-.
13.11.1.23:11: INK FISH
I had phở mực (squid pho) for dinner which made me look up the characters for mực at nomna.org:
| Semantic | Phonetic |
| (none) | 墨 mặc 'ink' |
| 虫 trùng 'bug' | |
| 衤 y 'clothes' | 默 mặc 'silent' |
By coincidence, I wrote about 默 'silent' earlier this week. But what is it doing next to 衤 'clothes'? I would expect the semantic component 魚 ngư 'fish' instead.
̣mực 'squid' is an extended use of mực 'ink'. Both mực [mɨk] and mặc [mak] are borrowings from Chinese 墨 'ink', but only the latter is considered a Sino-Vietnamese reading. A generic reconstruction of the Middle Chinese word for 'ink' is *mək with a schwa halfway in height between the vowels of mực [mɨk] and mặc [mak]. Were the Vietnamese forms borrowed from two Middle Chinese dialects with raised and lowered reflexes of *ə?
Since Middle Chinese *-ək almost always corresponds to Sino-Vietnamese -ặc [ak], one might conclude that the -[ak]-dialect was more prestigious than the -[ɨk]-dialect, but the Sino-Vietnamese reading for 德 'virtue' is đức [ɗɨk], not *đắc [ɗak]! It would make no sense to base the pronunciation of the character for such a key Chinese cultural term on a nonprestigious dialect.
My guess is that the -[ɨk]-dialect is older, and that đức is a remnant of an earlier reading tradition. Mực would have been borrowed at the same time as đức and would have been the standard reading of 墨 until it was replaced by the newer reading mặc.
Like Sino-Vietnamese, Sino-Korean also has archaisms among a body of readings which are mostly of Late Middle Chinese origin.
Contrast this situation with Sino-Japanese which has older and newer reading traditions (Go-on and Kan-on) side by side: e.g., Go-on moku and Kan-on boku for 墨. (The newer reading in Japanese has b- < *mb- since it is based on a northwestern Late Middle Chinese dialect which partly denasalized original *m-, whereas Sino-Korean muk and Sino-Vietnamese mặc are based on eastern dialects which retained *m-.)
The Vietnamese word cá mực 'squid', literally 'fish ink' (i.e., 'ink fish'), may be a calque of Chinese 墨魚 'ink fish'.
What are other Vietic words for 'squid'? I was surprised to find only one word for 'squid' in the Mon-Khmer Comparative Dictionary, and it wasn't Vietic: Kensiu suto̝gŋ, which I initially assumed was a typo. But it turns out that in Kensiu,
/b, d, ɟ, g/ are phonetically realised as voiced bilabial alveolar, palatal and velar stops, [b, d, ɟ, g] respectively syllable initially, but as prestopped nasals morpheme final. The voiced stops have a word final allophone with a final nasal assimilating to the same point of articulation as the stop: /b/, [-bm], /d/, [-dn], [ɟ], [-ɟɲ], /g/, [-gŋ].
I'd like to see how those stop-nasal sequences are written in the Thai-based orthography for Kensiu, but the file describing it has apparently been taken down from the David Thomas Library, and I don't understand the description at Wikipedia:
The pre-stopped nasals /bm/, /dn/, /ɟɲ/ and /gŋ/ [treated as phoneme sequences in this passage unlike the previous one] contrast with /m/, /n/, /ɲ/ and /ŋ/ in the final syllable position, resulting in the need to distinguish between these consonants in the orthography. The unaspirated stops were initially used to represent the pre-stopped nasals but the reader was unable to decode the word. Eventually, a garand were written above the oral stops representing /bm/, /dn/, /ɟɲ/ and /gŋ/. Writing in this manner allows the reader to recognize the consonant cluster as the representation of the pre-stopped nasal.
Are the letters for "unaspirated stops" ก จ ต ป <k c t p>? What is a "garand"?
23:39: Speaking of Thai, ปลาหมึก plaa mɨk <plaa hmɨk> 'squid' is also literally 'fish ink', and mɨk <hmɨk> 'ink' may have been borrowed from a Chinese dialect similar to the source of Vietnamese mực. The Thai word may not be from the same dialect since its tone indicates an earlier voiceless *hm- whereas the Vietnamese tone indicates an earlier voiced *m-.
Lao mɨk 'ink' has two possible tones, one indicating *hm- and the other *m-, but only the latter is in ປາມຶກ paa mɨk <paa mɨk> 'squid' according to Kerr and Patterson's dictionaries. However, ປາຫມຶກ paa mɨk <paa hmɨk> with the *hm-tone is ten times more common in Google.
Headley regarded Khmer មឹក mɨk 'squid' as a loan from Vietnamese. A synonym យៀវហ៊ឺ yiev hɨɨ looks like a loan from some Southern Min pronunciation of 魷魚. What native Tai, Khmer, and Vietnamese words for 'squid' were displaced?
13.10.31.23:54: TOILING UNDER COMPULSION
I looked at phonetic table 62 of the D edition of Five Sounds to see Li Fanwen's (2008) characterin context:
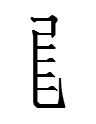
6066 1tʂɨụ (transcription character)
Above and below it are its (near-)homophones:
Was 0500 pronounced as 1tʂɨụ instead of 1tsiụ in the dialect of the scribe?
3805 1tʂɨụ 'that', 0500 1tsiụ (not 1tʂɨụ!) 'to beat', 1354, the first half of 1tʂɨụ 2ʔweʳ 'to defend'
Next to 6066 is
=
+
6058 1tʂɨụ (transcription character) =
'toil', the left side of 5566 1tʂɨị 'bitter' +
all of the first half of 1884, the first half of 1piụ 1lhọ 'to compel'
which is another fanqie phonetic transcription character also only known from Five Sounds. Why did the syllable 1tʂɨu have a second phonetic character? When would one use 6058 instead of 6066? Were they interchangeable?
Few Tangut characters consist of single components. Why was the first syllable of
1piụ 1lhọ 'to compel'
written with a single component?
13.10.30.23:57: TOILING LITTLE DEMON
Li Fanwen's 2008 Tangut dictionary lists 43 characters with the right-hand demon radical:
One of them was not in the 1997 edition of the dictionary. 6066 is a fanqie phonetic transcription character: i.e., it is pronounced as a combination of the consonant of the source of its left-hand component 'toil' and the rhyme of the source of its remaining components ('little' and 'demon'):
1tʂɨụ = left side of 1tʂɨị 'bitter' + center and right of 1ʂɨụ 'nit' (written as 'person' + 'little' + 'demon')
I don't understand why this character exists. I can understand the need to create a phonetic transcription character to represent a syllable that is not associated with any existing word, but was not such a syllable. Two Tangut characters were also pronounced 1tʂɨụ:
1354, the first half of 1354 4976 1tʂɨụ 2ʔweʳ 'to defend'
(10.31.0:18: 4976 is obviously derived from 1354. How many other disyllable words were written as sequences of the type X horned hat + X?)
3805 1tʂɨụ 'that'
Was 6066 intended to represent 1tʂɨụ in words that had nothing to do with defense or 'that? Tense vowels indicated with subscript dots like the ụ of 6066 were not in nearby languages (Uyghur, Tibetan, Chinese, Khitan), so I presume 6066 was intended to represent a native Tangut syllable. Unfortunately, Li (2008: 951) only listed one occurrence of 6066: phonetic table 62 of the D edition of Five Sounds.
13.10.29.23:59: SILENT EYEBROWS AND GHOSTS
Last night I forgot to mention one other complication which makes me somewhat reluctant to derive Tangut
2bəəi 'eyebrow' and 2bəəi 'ghost'
from northwestern Chinese 眉 *mbi 'eyebrow' and 魅 *mbi 'supernatural creature'. The Tangut characters for 'eyebrow' and 'ghost' were used to transcribe the Tangut period northwestern Chinese pronunciation of 默 'silent' in the Tangut translation of The Forest of Categories. The late Tang dynasty northwestern Chinese reading of 默 'silent' was transcribed in Tibetan as Hbug [mbuk] and reconstructed by Coblin (1994: 414) as *mbuk. By the Tangut period *mbuk would have become *mbu in Gong's (1995) reconstruction which is unlike his *mbji (= my *mbi) for 眉 and 魅. If 2bəəi 'eyebrow' and 'ghost' were borrowed from 眉 and 魅, why did they sound like 默? On the other hand, what are the odds that 'eyebrow' and 'ghost' would be homophones with the same initial in both Tangut and Chinese?
10.30.10:45: In most modern northwestern Chinese dialects (with one exception in bold), the morphemes 默 and 眉 have different rhymes even if tones are disregarded (Coblin 1994: 227, 414):
|
Dialect \ morpheme |
默 'silent' | 眉 'eyebrow' |
| Xining | mei | mj (sic!) |
| Dunhuang | mei | mei ~ mi |
| Lanzhou | mɤ | mi |
| Pingliang | mɛi | mi |
| Xi'an | mei | mi |
One could hypothesize that the northwestern dialect from which the Tangut borrowed 'eyebrow' and 'ghost' was like modern Dunhuang in which 'silent' and one pronunciation of 'eyebrow' are segmentally identical. However, the relationship between the Tangut period northwestern dialects and modern dialects is unclear; the former could be ancestral or substratal to the latter. Even if modern Dunhuang is a direct descendant of Tangut period northwestern Chinese, the merger that made 'silent' and 'eyebrow' homophonous could have postdated the fall of the Tangut Empire. Hence I am hesitant about projecting the homophony of 'silent' and 'eyebrow' in Dunhuang back into the Tangut period. Besides, Dunhuang does have another pronunciation of 'eyebrow' which is not homophonous with 'silent'.
10.30.23:43: One should not forget that the Tibetan script is not IPA. It is possible that the transcriptions Hbug for 默. and Hbi for 眉 conceal similar if not identical vowels. u and i might be attempts to write a Chinese *ɨ which is close to the schwa of 默 Early Middle Chinese *mək and the velar glide of Early Middle Chinese 眉 *mɰi. Maybe 默 and 眉 had both become *mbɨ in Tangut period northwestern Chinese. *mbɨ is not far from my reconstruction of 2bəəi for 'eyebrow' and 'ghost'. -əəi might have been the closest possible match for Chinese *-ɨ which has no exact equivalent in my reconstruction.
I map out another scenario below in which 默 and 眉 were not homophonous:
| Sinograph | Gloss | Late Tang | Tibetan transcription | Tangut period | Tangut transcription | Modern Xi'an |
| 默 | silent | *mbək | Hbug | *mbəi | 2bəəi | mei |
| 眉 | eyebrow | *mbɨ | Hbi | *mbɨ | mi |
Maybe 默 was *mbəəi with a long vowel like 2bəəi. Otherwise I would have expected it to have been transcribed as bəi with a short vowel in Tangut.
13.10.28.22:45: GHOST FACE
Could the Tangut character for 'eyebrow' be any more opaque than the Vietnamese character from two posts ago? Tangut 2bəəi 'eyebrow' was written as
=
+
2bəəi 'eyebrow' = left of 2bəəi 'ghost' + right of 2nieʳ 'face'
a straightforward semantophonetic compound: 2bəəi 'eyebrow' sounded like 2bəəi 'ghost' and referred to a facial feature.
The structure of the Tangut character is clearer than the origin of the word it represents. At first glance it appears to be a borrowing of the northwestern Chinese morpheme 眉 'eyebrow' that was transcribed in Tibetan as Hbi [mbi] during the late Tang Dynasty. The initial certainly fits and might even be an exact match if Tangut b- was [mb]. However, the Tangut word ends in rhyme 12 which most agree was not a simple -i:
Kychanov & Sofronov 1963: -E
Nishida 1964: -ʷɪɦ
Hashimoto 1965: -i (the one exception)
Sofronov 1968: -eC
Huang Zhenhua 1983: -ïr
Li Fanwen 1986: -ui
Gong 1997: -ee
Arakawa 1999: -i'
Sofronov 2012: -eˁ
Similarly, 2bəəi 'ghost' initially appears to be a borrowing from northwestern Chinese 魅 *mbi 'supernatural creature', but it too has Tangut rhyme 12. Northwestern Chinese *-i was normally borrowed and transcribed with Tangut rhymes 10 and 11 depending on the initial. I reconstruct those rhymes as -ɨi and -ii. Why were 'eyebrow' and 'ghost' borrowed with rhyme 12 instead of rhyme 11 which followed labials like b-?
Many Tangut rhymes including 10-12 were generally transcribed as -i in Tibetan. The distinctions between them were either impossible to indicate in the Tibetan script or were absent in the Tangut dialect(s) underlying the transcriptions. Did northwestern Chinese /i/ have a lot of variant pronunciations which sounded like different vowels to Tangut speakers?
In any case, if the Tangut word for 'eyebrow' is native, it is probably not cognate to rGyalrongic forms like Daofu rmi which may go back to *r-mey. Pre-Tangut *r-me would have become Tangut *meʳ with *m- and a retroflex vowel, not 2bəəi.
13.10.27.23:59: MÀY-GRATION
Vietnamese mày [maj] 'eyebrow' from my last post was borrowed from a southern dialect of Late Old Chinese (cf. southern Min forms: Xiamen mai and Chaozhou bai), whereas Vietnamese mi 'id.' was borrowed centuries later from southern Late Middle Chinese 眉 *mi.
I do not understand why Baxter and Sagart (2011: 86) reconstructed the Early Old Chinese ancestor of those forms as *mrər. I would not expect a final *-r since
- 眉 rhymes with *-j but not *-r words in Shijing (Starostin 1989: 569, 581)
- 眉 has no Middle Chinese *-n words in its xiesheng series (Middle Chinese *-i/*-j ~ *-n alternation points to Old Chinese *-r)
Starostin and I reconstruct 眉 as *mrəj with *-j.
I also do not understand how *-rər became [aj] in southern Chinese. In mainstream Chinese, 微 *məj and 眉 *mrəj developed quite differently:
微 Early Old Chinese *məj > Late Old Chinese *mɨj > *muj
眉 Early Old Chinese *mrəj > Late Old Chinese *mɰəj > *mɰi > *mi
Did Late Old Chinese *ə lower to *a before *-j in the south?
10.28.1:01: I have been assuming that Proto-Min, the ancestor of Xiamen and Chaozhou, was descended from Old Chinese, but that need not be the case:
We cannot be sure that Old Chinese is the direct ancestor of Proto-Min. Old Chinese might be the literary lect of a colloquial language that is ancestral to Proto-Min, or Old Chinese might be the sibling of the parent language of Min. (Handel 2010: 19)
10.28.1:18: Could Vietnamese mày and Min forms simply reflect *məj? Mainstream *mrəj may be from an earlier *T-məj with a coronal prefix that metathesized:
*T-məj > *rməj > *mrəj
(*T- may have been *r- if rGyalrongic morphemes such as Daofu rmi 'hair' are cognate.)
That prefix might have been absent from the ancestor of Xiamen mai and Chaozhou bai and the source of Vietnamese mày. (I do not assume that early Chinese loans in Vietnamese were from a Min language. Min is not spoken near Vietnam. Nonetheless, it may preserve traits of earlier southern Chinese lost elsewhere: e.g., in the Yue varieties by the Vietnamese border.)