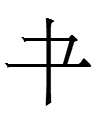
1ʔiaʳ 'eight'
13.9.7.14:17: EIGHT HORSES: PRIMARY AND SECONDARY YOD IN TANGUT
The late EG Pulleyblank rejected the yod reconstructed by Karlgren and others after him in half the vocabulary of Old and Middle Chinese. Nonetheless, I recall that he reconstructed Old Chinese 'eight' with yod as something like *prjat: cf. Written Tibetan brgyad. This Old Chinese word does not have a yod in many reconstructions (though Li Fang-Kuei and Gong Hwang-cherng reconstructed it as *priat and Schuessler [1987: 7] reconstructed it as *pəriat). I would reconstruct it as *pret, though I suspect its *e is from an earlier *ja.
Tangut
1ʔiaʳ 'eight'
is more conservative in one respect than Old Chinese *pret from two thousand years earlier since its ia had not fused into e. Its -i- and retroflexion are remnants of an earlier *rj-:
*pʌ-rjat > *rja > *rjaʳ > *jaʳ > 1ʔiaʳ
Tangut -i- here is a reflex of Bodman's Proto-Sino-Tibetan 'primary yod'.
Tangut is full of syllables with -i- (= Gong's -j-). Most of these -i- are, in Bodman's terminology, 'secondary yods' reflecting earlier high vowels in lost presyllables: e.g.,
1rieʳ and 2riaʳ 'horse' (this collocation is in Homophones 53B27)
which may go back to *mɯ-re(N) (or *mɯ-ra-i?) and *mɯ-ra(N)-H (cf. other Sino-Tibetan words for 'horse': e.g., Old Chinese 馬 *mraʔ). It is not possible to determine on the basis of Tangut alone whether 'horse' once had a final nasal like Old Tibetan rmang or Written Burmese mraŋḥ since Tangut did not have the nasal retroflex rhymes *-iẽʳ and *-iãʳ (though it did have three syllables ending in 2-iõʳ - presumably remnants of a much larger *-iṼʳ category).
Why did 'horse' retain an *r lost in 'eight'? 'Horse' must not have had a *rj-cluster at the time *rj- was reduced to *j- in 'eight'.
Scenario 1: 'rj-eduction' before raising
| Stage / Gloss | 'eight' | 'horse' |
| 1 | *rj- | *mɯ-r- |
| 2: retroflexion of vowel after *r- | *rj-ʳ | *mɯ-r-ʳ |
| 3: 'rj-eduction' | *j-ʳ | |
| 4: raising of main syllable vowel: secondary yod | *mɯ-ri-ʳ | |
| 5: loss of presyllable | *ri-ʳ | |
| 6: merger of *j- and *ʔi- | ʔi-ʳ | ri-ʳ |
Scenario 2: 'rj-eduction' after raising
| Stage / Gloss | 'eight' | 'horse' |
| 1 | *rj- | *mɯ-r- |
| 2: retroflexion of vowel after *r- | *rj-ʳ | *mɯ-r-ʳ |
| 3: raising of main syllable vowel: secondary yod | *mɯ-ri-ʳ | |
| 4: 'rj-eduction' (affected *rj- but not *ri-) | *j-ʳ | |
| 5: loss of presyllable | *ri-ʳ | |
| 6: merger of *j- and *ʔi- | ʔi-ʳ | ri-ʳ |
If Tangut had a presyllable in 'eight' at the 'rj-eduction' stage, *-rj- might have lenited to *-j- between vowels.
Scenario 3: medial 'rj-eduction'
| Stage / Gloss | 'eight' | 'horse' |
| 1 | *pʌ-rj- | *mɯ-r- |
| 2: retroflexion of vowel after *r- | *pʌ-rj-ʳ | *mɯ-r-ʳ |
| 3: 'rj-eduction' | *pʌ-j-ʳ | |
| 4: raising of main syllable vowel: secondary yod | *mɯ-ri-ʳ | |
| 5: loss of presyllable | *j-ʳ | *ri-ʳ |
| 6: merger of *j- and *ʔi- | ʔi-ʳ | ri-ʳ |
I wonder how the late Gong Hwang-cherng would have accounted for 'rj-eduction' in 'eight' but not in 'horse'. He reconstructed both words with -j- in Tangut and did not distinguish between a primary and a secondary yod in Tangut as far as I know. (Gong's Tangut medial -i- does not correspond to my medial -i-.) Following Gong, I could rewrite my medial -i- as -j- and propose that initial *rj- was 'rj-educed' whereas medial *-rj- was 'rj-etained'. (But intervocalic position is a more likely position for lenition.)
Scenario 4: initial 'rj-eduction'
| Stage / Gloss | 'eight' | 'horse' |
| 1 | *rj- | *mɯ-r- |
| 2: retroflexion of vowel after *r- | *rj-ʳ | *mɯ-r-ʳ |
| 3: secondary yod | *mɯ-rj-ʳ | |
| 4: 'rj-eduction' (affected *rj- but not *-rj-) | *j-ʳ | |
| 5: loss of presyllable | *rj-ʳ | |
| 6: merger of *j- and *ʔj- | ʔj-ʳ | rj-ʳ |
I need to look at more instances of primary and secondary yod to determine whether any of these four scenarios is correct.
13.9.6.2:21: CUI PRODEST?
is the title of a book I recently received as a gift.
The dative pronoun cui 'to whom' brings to mind a question that's been bothering me for a couple of days. English whom was originally dative; the lost accusative was hwone in Old English. The -n- goes back to Proto-Germanic (PG) *hwanǭ (in the reconstruction at Wikipedia). Although whom superficially resembles the Proto-Indo-European (PIE) accusative *kʷom, it is actually from the PIE dative *kʷosmōi. How did PIE *kʷom become PG *hwanǭ? My guess is that PIE final *-m became *-n, and another ending *-ōn (later *-ǭ) was added to that in third person pronominal and strong adjectival declensions. Where did *-ōn come from?
The verb prodest has an unexpected -d- absent in the first person singular prosum. Since est never had an initial d-, I assume the -d- was a suffix added to pro-. I presume this is the same -d as in prodigium. What is this -d? Is it unique to Latin?
13.9.4.18:32: 'GOOD' EXAMPLES OF METATHESIS, PALATALIZATION, AND MONOPHTHONGIZATION IN KHITAN?
Since Rosh Hashanah begins this evening, I was trying to come up with a Khitan translation of shana tova 'good year'. Kane (2009: 100) listed three Khitan small script forms for 'good' corresponding to Mongolian and Jurchen/Manchu sain 'id'.:
~
~
<ś.ia> ~ <ś.iá.aɣ> ~ <ś.ên>
Although sain is newer than the Khitan forms, I suspect the former is more conservative than the latter, and close to a pre-Khitan *sai:
*sai(-ɣ) > *sia(ɣ) > *śia(ɣ) (metathesis and palatalization)
*sai-n > *sian > *śian > *śên (metathesis, palatalization, and monophthongization)
The monophthongization of *ia might have been blocked before *ɣ if *eɣ violated harmonic rules.
Another example of metathesis might be -ia in taulia 'hare' (corresponding to Mongolian taulai 'id.').
Questions:
1. Khitan also has words ending in -ai: e.g.,
/
<ai> 'year', 'father'
/
<nai> 'head'
(These two words incidentally happen to form the Khitan equivalent of rosh ha-shana 'head [of] the year'.)
Why didn't their vowels metathesize? Were the vowels of these words somehow different from those of 'good' and 'hare'?
2. Khitan has si in Chinese borrowings presumably postdating palatalization. Does that sequence ever occur in native words? What about ti, di, and ni? I could not find any examples of <t.i>, <d.i>, and <n.i> in small script texts I have on hand. <t.i.i> is attested as a borrowing of Chinese and Chinese 帝 was borrowed as
<di>
(Kane 2009: 244). Kane's (2009: 108, 110, 176, 183)
~
/
<uni> 'ox' and
<suni> 'night' (is a large script spelling known?)
might have been uńi and suńi.
13.9.3.19:15: WAS KHITAN A PARA-MONGOLIC LANGUAGE?
I have assumed that Khitan was a para-Mongolic language - a relative but not an ancestor of Mongolian - ever since I started looking into Khitan seventeen years ago. I was convinced by apparent cognates such as
/

<tau>/<tau> 'five' (cf. Mongolian tabun 'id.')
~
~
~
/
<tau.lia> ~ <tau.lia> ~ <tau.lia> ~ <taulia>/<tau.lí.a> 'hare' (cf. Mongolian taulai 'id.'; the different orders of the final vowels have yet to be explained)
But shared vocabulary is not sufficient proof of a genetic relationship. Vietnamese and Korean share 'five' and 'hare' with Chinese, yet none of those three languages are related to each other. The Vietnamese and Korean forms for 'five' and 'hare' are borrowings from Chinese:
'five'
Very Late Middle Chinese *ŋú > V ngũ
Late Middle Chinese *ŋó > K 오 o
'hare'
Early Middle Chinese *tʰɔʰ > V thỏ
Late Middle Chinese *tʰò > K 토끼 thokki (if -kki is a suffix)
Vietnamese and Korean retain their native words for 'five' (năm and 다섯 tasŏt) but it is possible for a language to replace its native lower numerals: e.g., the original Kra-Dai word for 'five' was probably something like Proto-Kra *r-ma (Ostapirat 2000: 260) and Proto-Hlai *hma (Norquest 2007: 104; both ultimately related to Proto-Austronesian *lima) but was replaced with *haːC (Pittayaporn 2009: 119; < *ŋ̊aːC < Old Chinese 五 *ŋaʔ with a devoicing prefix?) in Proto-Tai. Did Mongolic borrow numerals and other vocabulary from Khitan?
There is no doubt that Khitan is an Altaic-type language, but that doesn't mean it has to be genetically related to any of the other Altaic-type languages. Although Kane's (2009: ix) statement
Nevertheless, even when Kitan [= Khitan] words, and whole sentences, are transliterated, they do not yield anything resembling Mongol, Jurchen, Turkic or any other attested language.
is too strong, it is true that much of Khitan is alien. If Khitan was related to Mongolic, the two must have been quite distant.
The best case I can make for a genetic relationship between them is morphological. Some case suffixes look similar (e.g., Khitan -er could be a contraction of a longer form like Proto-Mongolic *-ixAr), though their resemblance may be at least partly coincidental (e.g., Khitan -de happens to look like the unrelated Japanese locative postposition de which is a contraction of ni and te):
| Case | Khitan (Kane 2009) | Proto-Mongolic (Janhunen 2003) |
| Accusative | -er | *-(y)i |
| Instrumental | *-(i)xAr | |
| Genitive | -(V)n, -iń, -i | *-yin, *-U(n) |
| Dative-locative | -de/-do/-dú, -iú | *-dU-r/*-tU-r |
| Ablative | -dei | *-A-cA |
Khitan and Mongolic also share the plural suffixes -d and -s. But short morphemes are weak evidence. English plural -s is not proof of a genetic relationship with Khitan or Mongolic! And plural suffixes can be borrowed: e.g., English -a and -i from Latin.
Khitan and Mongolic do not seem to share much verbal morphology. The phonetic similarity between Khitan -leɣa/-lege and WM -lɣa-, -lge- is striking (and may be total since the Khitan suffixes were written as <l.ɣa> and <l.ge>; Kane assumed dental-initial Khitan small script characters had an inherent vowel <e>):
| Suffix | Khitan (Kane 2009) | Proto-Mongolic (Janhunen 2003) |
| Past | -ar/-er/-or, -lun, -boń/-bun/-bún | *-bA-(y)i, -lUxA-(y)i, *-JU-xU-(y)i |
| Causative | -(le)ɣa/-(le)ge | Written Mongolian -ɣa-/-qa-/-ge-/-ke-, -ɣul-/-kül-, -lɣa-/-lge- |
| Passive | Written Mongolian -qda-/-gde-, -da-/-ta-/-de-/-te- | |
| Converb | -(V)i, -s.ii, -al, -ci/-ji | -(U)n, *-JU (but nonclassical Written Mongolian -ci/-ji!), *-(U)xAd, *-(U)xA-sU(-xA(y)i), *-tAl-A, *-tAr-A, *-(U)-r-A, *-(U)-r-U-n |
| Nominalizer | -(V)n, -ń, -boń, -ɣo/-ɣu/-gi (< *-gü?) | *-kU(-(y)i), *-(U)-xA(-(y)i), *-(U)-g-sA-n, *-(U)-dAg, *-(U)g-ci, *-xA-ci |
Unfortunately, Khitan pronouns are completely unknown to me, but even if they were known and were similar to Mongolic pronouns, borrowing cannot be ruled out. (And if Mongolian bi 'I' is borrowed from Turkic as Georg proposed, then perhaps the unknown Khitan pronoun for 'I' might be a cognate of the original lost native Mongolic nominative/genitive pronoun which might have resembled the oblique root *na-.)
Until Khitan is better understood, it will not be possible to reconstruct a common ancestor for it and Mongolic, and such a reconstruction will be only fragmentary due to the small number of cognates in Khitan.
13.9.1.23:59: TO FLY = WING + BIRD
The Tangraphic Sea analyzed the character for Tangut phii 'to fly' as a combination of the left sides of 2dzwiə 'wing' and 1dʐwõ 'bird':
=
+
The Combined Homophones and Tangraphic Sea analyzed the character for its synonym 2ve 'to fly' as all of 2bie 'high' plus the right of 1dʐwõ 'bird':
These four words could go back to the following pre-Tangut forms:=
+
1phii < *phiC? (< *K-piC??)
Could phii be a loanword from Tangut period northwestern Chinese 飛 *fɨi 'to fly' with ph- as a substitute for f- which Tangut lacked? Tangut did not permit -ɨi after ph-, so -ii was the closest available substitute.
If the word is not of Chinese origin, then *phii may be from *phiC which in turn may be from *K-piC. And if *-C was *l, the root *pil might be cognate to Old Chinese 飛 *pəj 'to fly' which may be from *pəl.
Matisoff (2003: ) reconstructed Proto-Tibeto-Burman *pir 'to fly'. I don't think pre-Tangut *-C in 'to fly' can be *-r since *phir and *k-pir would have become *1phiʳ with a short retroflex vowel rather than a long vowel.
2dzwiə < *P-dzəH 'wing'
Could this be cognate to Mawo Qiang gzi guaʴ, gzɪj pɑ 'wing'? If so, is Tangut dz- partly from *gz-?
I still don't know why dz- and dʐ-characters were placed in the Mixed Categories volume of Tangraphic Sea instead of the level and rising tone volumes.
1dʐwõ '< P-džoN 'bird'
Could this be cognate to Jiulong Pumi dʑa¹¹ dʑẽ⁵⁵, dʑɛ̃³⁵ 'bird' (and other similar Qiangic words without nasal vowels: e.g., Muya dʑe³⁵ wu³³ 'id.')?
2ve < *weH or *Cʌ-PeH 'to fly'
2bie < *Cɯ-PeH 'high'
Could these words share a common root *PeH? I can't find any external cognates. Longxi Qiang bè means 'low'!
9.2.00:08: The true Tangut cognate of Longxi Qiang bè 'low' may be
1biə 1bi 'below'.