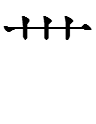
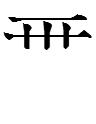
1lɨə 1lwɨụ 'to creep, crawl'
13.1.5.23:45: CREEPING AND CRAWLING IN CIRCLES
The Tangraphic Sea derives the second half of
1lɨə 1lwɨụ 'to creep, crawl'
from its first half ... and from its derivative 'snake'!
+
+
1lwɨụ (first half of 1lɨə 1lwɨụ 'to creep, crawl') =
top of 1vəi 'dragon' (but do dragons creep or crawl?)
bottom right of 1lɨə ̣ (first half of 1lɨə 1lwɨụ 'to creep, crawl') +
bottom left of 1tshõ 'desolate and boundless' (why?)
bottom left of 2phɔ 'snake'
Its first source character is also derived from the first half of its near-mirror image 1lɨə 1lwɨụ 'to creep, crawl':
1vəi 'dragon' =
top of 1lɨə ̣ (first half of 1lɨə 1lwɨụ 'to creep, crawl') +
bottom of 1vəi 'dragon tree' (i.e., 龍眼 longan 'dragon eye')
Given the importance of the dragon, it is more likely that 'dragon tree' is a derivative of 'dragon' with
'wood'
instead of
'above'
as the top element. I suspect that the 'crawl' graphs may be derivatives of 'dragon' and/or 'snake' rather than the other way around. The Tangraphic Sea's analysis of 'dragon tree' confirms my guess:
=
+
1vəi 'dragon tree' =
top of 1si 'wood' +
bottom of 1vəi 'dragon'
The role of the third source character
1tshõ 'desolate and boundless'
is a mystery. Nishida (1966: 245) has no definition for the component that it contributed to the second half of 'crawl':
i.e., his radical 250.
The analysis of the first half of 'crawl' may imply that verb referred to coiling motions:
+
1lɨə ̣ (first half of 1lɨə 1lwɨụ 'to creep, crawl') =
top of 1tswa 'hair worn in a bun or coil' (semantic?)
all of 1lɨə 'to lock up' (phonetic)
'Hair worn in a bun or coil' is a semantic compound:
+
1tswa 'hair worn in a bun or coil' =
top and bottom left of 2tʃɨew 'top' +
top right of 2pɛ̣̃ 'hair'
'To lock up' is composed of parts of each half of 'fetters':
=
+
1lɨə 'to lock up' =
right of 2siə (first half of 2siə 2gie 'fetters')
left and center of 2gie (second half of 2siə 2gie 'fetters')
All three of the above tangraphs share the component 干 (Nishida's radical 098) with 'dragon', 'snake', and both halves of what has been translated as 'crawl' (Kychanov and Arakawa 2006: 118, Li Fanwen 2008: 9, 19). Nishida's (1966: 243) definition 'surround' may be appropriate for all of them since
- fetters surround body parts
- to lock up someone or something is to surround it with the walls of a prison, bars of a cage, etc.
- surrounding involves circularity, and
dragons and snakes
form circles as they coil (which is what
'crawl'
might mean)
And that brings us full circle back to where we started!
1.6.00:19: Kychanov and Arakawa (2006: 118, 138) translated the first half of
as 'creep' and the second half as 'reptile' (is either attested
without the other?), so they combine to form a compound 'creep'
literally meaning 'creep-reptile' (creep like a reptile)?
13.1.2.23:56: A CLOSER LOOK AT 'CREEPING' AND 'CRAWLING'
The Precious Rhymes of the Tangraphic Sea derives the 干 of
2phɔ 'snake'
from the second tangraph of
1lɨə 1lwɨụ 'to creep, crawl'
which looks like a reduplicative word. Or is it? Its Pre-Tangut source should be *lə SPlu which underwent the following changes (not necessarily in the correct order):
- high series vowels (i, ə, u) not preceded by a low-voweled presyllable became ɨi, ɨə, ɨu after l-*
- *S- disappeared after conditioning vowel tension (symbolized by a subscript dot)
- *-P- lenited and metathesized, becoming -w- after the root initial
*lə SPlu may not look much like a reduplicative word. Its two syllables have nothing in common besides an l.
Then again, perhaps Tangut reduplication was like Sanskrit reduplication which is not only partial but also sometimes hard to recognize: e.g.,
ja-ghān-a 'slew' (not *ghān-ghān-a!; < √han)
ti-ṣṭha-ti 'stands' (not *ṣṭha-ṣṭha-ti!; < √sthā)
The formula for the pattern of Pre-Tangut reduplication in 'to creep' might have been:
root-initial consonant + *ə + (prefixes) + root + (suffix)
It's even possible that reduplication was still semiproductive at a later stage after the sound changes listed above:
root-initial consonant + ə-type vowel of same grade as root + root (with traces of affixes, if any)
Do other reduplicative words in Tangut fit this pattern?
Tangut words, particularly disyllabic noncompounds (e.g., reduplicative words and irreducible polysyllabic roots), are relatively unexplored compared to syllables. I wish I had an electronic index to all the words in Kychanov and Arakawa's 2006 dictionary.
*1.3.2:27: Tangut l- may have been velar [ɫ]. Palatal -i- usually cannot follow Tangut l-, but there are exceptions that I cannot explain: e.g., the minimal pair lɨa (Grade III; rhyme 19) : lia (Grade IV; rhyme 20) and lie (Grade IV, rhyme 37) instead of the expected *lɨe (Grade III; rhyme 36).
13.1.1.23:56: POISON CRAWLING FORTY DAYS EARLY
Happy New Year! But watch out for snakes in the water!

(Calligraphy by 盧桐 Lu Tong.)
At least you have forty days to dodge them. Lunar New Year is on February 10. Start running ... or swimming for the shore?Tangut
=
2phɔ 'snake' =
bottom right of 1lwɨụ (second half of 1lɨə lwɨụ 'to creep, crawl') +
all of 1do 'poison'
is from Pre-Tangut *phroH which might be cognate to forms such as Written Tibetan sbrul and/or Caodeng rGyalrong qa-preʔ. The initial *ph- could be from an earlier *K(ʌ)-b- or *K(ʌ)-p- (but not *sb-)* and *-H could be *-ʔ. A Pre-Tangut *q(ʌ)-proʔ is very close to the Caodeng form, though I cannot reconcile the vowels**.
Next: A Closer Look at 'Creepy-Crawly'
*13.1.2.0:12: Pre-Tangut *sb- would have developed into Tangut b- followed by a tense vowel, not ph-.
**13.1.2.1:02: Could the proto-root have been *rulʔ?
- Tibetan could have added *m- and *m- prefixes but lost the original *-ʔ (which in turn could have come from a final stop: -lʔ < *-lt?; cf. Old Tibetan da-drag, though I don't know if 'snake' is first attested as OT sbruld). The *m- became -b- between s- and r- (Jacques 2004: 137).
(But if *smr- became sbr-, where did Written Tibetan smr- come from? If I understand Jacques correctly, he would derive the latter from Proto-Tibetan *sə-mr-. He also reconstructed Proto-Tibetan *sə-my- as the source of Written Tibetan smy-. Would he reconstruct any other Written Tibetan clusters from Proto-Tibetan Proto-Tibetan *sə-C-sequences?)
- A prefix *qa- fused with a prefix p- to become Tangut aspirated ph-, but remains intact in Caodeng. Korean aspirates are partly derived from similar fusions: e.g., khŭ- 'big' is from *hɯkɯ-.
The Pre-Tangut *q-prefix either had no vowel or a low vowel *ʌ. A high vowel *ɯ would have conditioned raising: *qɯ-proH > *2phio, not 2phɔ. (My Grade IV -io corresponds to Gong's Grade III -jo, not his Grade II -io.)
- rGyalrong front vowels like Caodeng e in 'snake' could be from
*ø < *øj < *oj < *uj < *ul.
Jacques (2004: 266) did not reconstruct final *-l in Proto-rGyalrong. Are there other cases where rGyalrong front vowels correspond to vowel-l sequences elsewhere?
- Perhaps *-l velarized and was lost after *-o in Pre-Tangut:
*-ul > *-ol > *-oɫ > *-ow > *-o.
(The timing of *-u-raising relative to *-l-loss is unknown.)
There is no Tangut-internal evidence for *-l in Pre-Tangut.
- Old Chinese 虺 *hməjʔ 'snake' could be from an earlier *q-m-rulʔ combining the *q-prefix found in Tangut and rGyalrong with the *m-prefix found in Tibetan.
12.12.31.23:59: THE GOLDEN GUIDE: LINE 96: TANGRAPHS 476-480
96. One tangraph is a transcriptive character not associated with any specific morpheme, two are for Tangut names, one is for a Chinese loanword as well as a Tangut name, and one is for a native Tangut word homophonous with a rare Chinese surname:
| Tangraph number | 476 | 477 | 478 | 479 | 480 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5595 | 3118 | 0052 | 5222 | 4494 |
| My reconstructed pronunciation | 2xwo (2ɣwo?) | 1xəu | 1ʐɨi | 2xi | 1təi |
| Tangraph gloss | (transcription of Chinese) | Tangut surname Hu | Tangut (sur)name Zhi | happy < Chn 喜 *xi; Tangut (sur)name Hi | to run |
| Word | the surname 何 He (*xo) | the surname 傅 Fu (*fɨu) | the rare surname* 兒/ 耏/尔/耳/貳 Er (*ʐɨi) |
the surname Xi 奚 (*xi) | the surname 德 De (*təi) |
| Translation | He, Fu, Er, Xi, De | ||||
476: Although Gong reconstructed the reading of 5595 (fanqie and analysis unknown) as 2xwo, I suspect its initial might have been ɣ- because 5595 might be a fanqie tangraph:
+
1936 2xwo (transcription of Chinese) =
left of 5793 1ɣwiə̣ 'to ripple' +
right of 2912 1lhwio 'to return'
There is no tangraph with the left side of 5595 and a reading with initial x-.
is the only tangraph with the right side of 5595 and a reading with a final like (but not exactly like!) -wo.
Li Fanwen (2008: 881) lists 2ɣǐuo, an alternate reconstruction** of the reading of 5595 with initial ɣ-, in addition to Gong's reconstruction 2xwo.
However, 5595 was used to transcribe Tangut period northwestern Chinese syllables with initial *x-, not *ɣ-. Some of those *x- were from earlier *ɣ-, but the Tangut would not know that:
| ̣̀̀̀Tangut | Sinographs | Tangut period northwestern Chinese | Middle Chinese (disregarding tones) |
| 2xwo | 火 | *x(w)o | *xwa |
| 何河荷賀 | *xo | *ɣa | |
| 和禍 | *x(w)o | *ɣwa | |
| 活 | *ɣwat | ||
| 黃皇凰煌 | *ɣwaŋ |
It is not clear whether Tangut period northwestern Chinese had a distinction between *-o and *-wo.
In short, the structure of 5595 points toward initial ɣ-, but the usage of 5595 points toward x-.
477: Did the Hu family somehow 'have' (own? rule?) the east? (13.1.1.1:45: They couldn't have tails - or were 'tails' a metaphor for something other than a body part?)
+

3118 1xəu 'the Tangut surname Hu' =
left two-thirds of 2611 1niooʳ 'tail, east' +
bottom right of 0930 1diu 'to have'
1niooʳ 'tail, east' and 1diu 'to have' are in Tangut verb-final order.
478: Were the Zhi a clan of entertainers at annual parties? (A New Year's concert is playing as I type this.)
+
+

0052 1ʐɨi 'the Tangut (sur)name Zhi' =
top of 0032 2ʐɨi 'the Tangut (sur)name Zhi' (phonetic) +
left and center of 3305 1kiew 'year' +
bottom right of 1097 2ʔəu 'entertainment, recreation'
479: Li Fanwen (2008: 825) regarded 5222 as having two phonetics: one exact (5281) and one not (5248). However, I wonder if 5248 indicates that the Hi were vigorous or related to the Khwi (whose own name meaning 'vigorous' is reminscent of the surnames Strong and Stark).
+

5222 1xi 'happy; the Tangut (sur)name Hi' =
left of 5248 1khwɪ 'the surname Khwi; vigorous' +
center of 5281 1xi 'surprised' (phonetic)
480: 4494 is a straightforward semantic compound:
+

4494 1təi 'to run' =
all of 4478 1ta 'to flee' +
right of 1640 1dziẹ 'to cross'
*13.1.1.2:54: These surnames are from Giles (1892: 1357).
**13.1.1.1:03: I have assumed that alternate reconstructions in Li Fanwen (2008) are from Li Fanwen (1986), but that is not true in this case. The reconstruction of the reading of 5595 in Li Fanwen (1986: 428) is 2xǐuo with x-, not 2ɣǐuo withɣ-.
13.1.1.2:56: ADDENDUM: I am doubly embarrassed, not only because this is my one and only Golden Guide entry for the entire year of 2012, but because I've been oblivious to how the Guide's list of Chinese surnames (lines 83-106) could have a double meaning in Chinese. That would explain why the surnames are a mix of the common and the rare; the latter are needed to make puns work. I don't have any better interpretation than Nie Hongyin and Shi Jinbo (1995), so I'll just give their readings of line 48 here as a sample and advise the reader to see their paper for the rest.
| Line 48 | |
|
|
|
|
| Chinese surname | 何 | 傅 | 兒/耏/尔/耳/貳 | 奚 | 德 |
| Double meaning | 禍 | 福 | 二 | ? | 得 |
| Gloss of double meaning | disaster | good fortune | two | get | |
| Reading of surname/homophone | *x(w)o | *fɨu | *ʐɨi | *xi | *təi |
Can anyone suggest a double meaning for *xi?
Now I wonder if the Tangut surname section (lines 51-76) has a double meaning in Tangut.
12.12.30.23:59: SYLLABIC NASALS IN AVESTAN?
David Boxenhorn suggested that Avestan a might have become a schwa on the way to becoming syllabic n̩, m̩, and u. This process is like what had already happened in reverse in Indo-Iranian: Proto-Indo-European syllabic nasals became Proto-Indo-Iranian *a: e.g.,
'hundred': PIE *(d)km̩tom > PII *ćatam > Av satəm, Skt śatam
PIE *gʷʰn̩to- 'struck' > PII *ǰhata- 'slain' (i.e., struck dead) > Av jata-, Skt hata-
12.31.00:26: I write the two palatal series of Proto-Indo-Iranian using an acute for the older series of palatals (ć, j́, j́h) and a háček for the later series of alveopalatals (č, ǰ, ǰh).
If Avestan had survived, would schwa-nasal sequences have become new syllabic nasals?
Av satəm > hypothetical post-Av *satm̩
Or did such nasals already exist in Avestan?* The Pahlavi-based Avestan alphabet is not IPA**. Could ən əm ə̄m*** əv have been attempts to write [n̩ m̩ v̩]?
A syllabic [v̩] is in the Bai name for the Bai language: pɛ̰ ŋv̰̩ ʦɿ. I think ŋv̰̩ is cognate to語 Chinese *Cɯ-ŋaʔ > Middle Chinese *ŋɨəʔ > Old Mandarin *ŋy > 语 Mandarin yu [jy] 'language'
which also happens to have an *a-to-schwa shift in its past.
The assimiliation of *a to a following v has a parallel in the shift of prenasal *ə to i before palatals: e.g.,'whom': *yam > OAv yə̄m > OAv yim (Old Avestan has both long schwa and -i- forms; cf. Skt yam)
The lengthening of schwa before m is reminiscent of the lengthening of *i and *u in the same environment:
'lord': *patim > Av patīm (cf. Skt patim)
'food' *pitum > Av pitūm (cf. Skt pitum)
I forgot to mention that *a and *ā may be nasalized as ą [ã] before nasals. Nasals may even be eliminated after ą: e.g.,
haomą < *saumān 'haoma*** plants' (acc. pl.; cf. Skt somān).
Conversely, nasals may be inserted between ą and m: e.g.,
dą(n)mahi < *dāmasi 'we shall give' (aorist subjunctive); cf. hypothetical Vedic Skt *dāmasi; see Jackson 1892: 13, 178).
I think this nasalized ą is an intermediate stage in a continuum (N = nasal):
| Stage 1: Original low vowels before nasals | aN [aN], āN [aːN] | |
| Stage 2: Nasalization; length neutralization | ąN [ã(ː)N] | |
| Stage 3: Raising | əN ~ ə̄m [ə̃(ː)N] | |
| Stage 4: Assimilation or syllabification | iN [iN] after palatals | əN ~ ə̄m [N̩] (and [m̩ː]?) elsewhere |
The Avesta preserves all these stages, just as an IPA transcription of English spoken during different periods will contain unstressed vowels at various levels of reduction.
*12.31.00:27: Has any ancient written language been reconstructed with syllabic nasals?
**12.31.00:36: Beekes (1988: 50) proposed that Old Avestan had an unwritten glottal stop descended from the laryngeals of Proto-Indo-European.
***12.31.00:17: Jackson (1892: 10) does not list any examples of long schwa before a nasal other than m and hm (voiceless [m̥]?).
****Avestan haoma- is cognate to Sanskrit soma-, a word I first encountered in Huxley's Brave New World.