

1542 1kəu 'therefore'
1543 1mioʳ 'true; appear'
11.7.16.21:10: CURSIVE TANGRAPHY
The variation in part 9 of my Khitan small script series reminded me of the variation within tangraphy (the Tangut script).
A single line is all that distinguishes two different tangraphs:
1542 1kəu 'therefore'
1543 1mioʳ 'true; appear'
Grinstead (1972: 59) pointed out that this line is even present in the cursive version of 1543:
Four cursive versions of 1542 without a long horizontal top right stroke present in 1543 below
Cursive version of 1543 with long horizontal top right stroke absent from 1542 above
I am amazed that Grinstead can identify these cursive forms. Here are several other cursive forms that differ considerably from their standard forms:
=

1084 5865 2ɣạ 1sọ 'thirteen' (lit. 'ten-three'; the paper appears damaged)
5865 1sọ 'three'
The left-hand component
is not abbreviated in cursive.
The right-hand component of the cursive version of 5865 looks like the right of
'Buddha' and Chinese 三 'three' plus an additional vertical stroke. There is no tangraph with the structure
, so this abbreviation does not cause any ambiguity.
=

2549 1dza 'miscellaneous, mixed' < Chn 雜
The left-hand component
is more or less the same in both versions, apart from the first two strokes ㅏ of the standard version fusing into a single stroke Г in the cursive version.
Right-hand
is commonly abbreviated as 乚 in cursive tangraphy. Note that 乚 is also a tangraphic element: e.g., in
.
=
3017 1diẹ 'kind, type'
The top left component
became a dot in the cursive version.
The top right component
was reduced to an X.
The bottom left component
was written with a single stroke.
The top two dots of the bottom right component (alphacode: pak) became one stroke and the third dot at the bottom right has been omitted. The 乚 stroke has become a 乀 whose bottom loops upward and then leftward. There is no standard component resembling pak without the third dot, which begs the question of why the third dot exists at all.
Tangraphs (Tangut characters) appear to be more complex than Chinese, but this is somewhat of an illusion. In "How Complex Is Tangut?", Andrew explained,
But although Tangut does not have any characters with very few strokes (less than 4 strokes) or very many strokes (more than 24 strokes), which distinguishes it from Chinese, if you ignore the lower and upper ends of the graph the distribution of stroke counts for Tangut is very close to that of traditional Chinese. Why then does Tangut text look so much more complex and more crowded than Chinese? That could be answered with another graph which took into account each character's frequency of occurence. A large proportion of high frequency Chinese characters have very few strokes (e.g. 一二三人女山火水大小中), and conversely Chinese characters with very many strokes tend to occur less frequently, with the result that normal Chinese text always has a large proportion of characters with few strokes. In contrast to the situation with Chinese, there does not appear to be any relationship between frequency and stroke count for Tangut characters, so that normal Tangut text is uniformly composed of characters with 12±6 strokes, with the result that it appears denser and more crowded than Chinese.
Cursive tangraphy reduces this complexity considerably: e.g.,
3017: 17 strokes vs. 5 strokes (out of four components, only the X requires two strokes)
The Khitan small script also looks complex because its polygrams consist of up to seven phonograms: e.g.,1542: 9 strokes vs. 3 strokes (and in even more rapid writing, the last two strokes 二 could be joined into a single Z shape)
<ja.ha.ai.il.ha.rí.én*> (30 strokes; Kane 2009: 202)
All known Khitan texts are inscriptions. If handwritten Khitan texts are ever found, will they contain cursive Khitan? What would <ja.ha.ai.il.ha.rí.én> look like in cursive?
*Kane transcribed this word as <ja.ha.ai.il.ha.rí.er>,
but the final phonogram is 361 ![]() <én>, not
341
<én>, not
341 ![]() <er>.
<er>.
11.7.15.23:55: KHITAN SMALL SCRIPT 9: DISTRI-BÚ-TION
Thanks to Andrew West
for giving me statistics for the dotted Khitan small script phonogram
272 ![]() <bú> separate from those for dotless 176
<bú> separate from those for dotless 176 ![]() <bú>. I have added a new row for 272
<bú>. I have added a new row for 272 ![]() in the
phonogram frequency table in part 8 of this series.
176 almost never appears medially, whereas 272
in the
phonogram frequency table in part 8 of this series.
176 almost never appears medially, whereas 272 ![]() never
appears initially. Both appear finally. Is this pattern significant?
never
appears initially. Both appear finally. Is this pattern significant?
| Position in polygram | ||
| Initial | Medial | Final |
| rare | ||
| never | ||
Could it imply that 272 ![]() had an
initial consonant that did not appear in initial position: e.g., a
fricative *β < *b? Cf. Middle Korean ㅸ β
< *b which could never appear word-initially. Could the dot
of 272
had an
initial consonant that did not appear in initial position: e.g., a
fricative *β < *b? Cf. Middle Korean ㅸ β
< *b which could never appear word-initially. Could the dot
of 272 ![]() indicate lenition? If so, do dots in other phonograms also
indicate lenition? (Dots indicate grammatical gender in logograms*:
e.g.,
indicate lenition? If so, do dots in other phonograms also
indicate lenition? (Dots indicate grammatical gender in logograms*:
e.g., ![]() <ONE> is the masculine counterpart of nonmasculine
<ONE> is the masculine counterpart of nonmasculine ![]() .)
.)
Kane (2009: 56, 68) regards 176 ![]() and 272
and 272 ![]() as probable allographs both representing <bú>. They correspond to
five different phonograms in Starikov (1982):
as probable allographs both representing <bú>. They correspond to
five different phonograms in Starikov (1982):
| Kane | |||||
| Kane # | 272 | 176 | |||
| Starikov |  |
 |
 |
 |
 |
| Starikov # | 058-116 | 058-117 | 058-118 | 059-119 | 059-120 |
| Notes | Dot touches ノ | Dot doesn't touch ノ | Short ノ | Left top closed | Left top open |
Are the differences between these five meaningful or random? The Khitan did not leave behind an explicit list of small script characters, so we are left to decide that for ourselves.
One might think variation would have ceased with the rise of computers and standardized encodings, but Chinese characters today vary by region and even within regions:
| Gloss | PRC, Singapore | HK, Taiwan, South Korea | Japan |
| black | 黑 | 黒 | |
| sage | 圣 | 聖 | |
| door | 户 | 戶 | 戸 |
| yield | 让 | 讓 | 譲 |
| sutra | 经 | 經 | 経 |
| explain | 说 | 說 | 説 |
| sword | 剑 | 劍 | 剣 |
| dragon | 龙 | 龍 | 竜 |
(7.16.2:44: Glosses are not comprehensive. Only the most common forms of 'sword' are listed. Yet others exist: e.g.,
𠝏劎劒剱劔釼𠠆
Here are even more variants of 'sword'. 'Dragon' has at least 51 variants!)
Not all variants within a region are equally frequent: e.g., in Japan, 剣 'sword' greatly outnumbers 劍 which in turn outnumbers all other variants combined.
Large visual differences may be of no semantic or phonetic significance: e.g., 让 = 讓 'yield' in Chinese.
Conversely, small visual differences may distinguish characters with completely different meanings and readings: e.g., Md 刀 dao 'knife' and 刃 ren 'blade' even though the two are interchangeable as right halves of 'sword'.
Fortunately, living people can tell us which characters are the 'same' and which aren't. But no Khitan remain to give us such information about the Khitan small or large scripts.
7.16.13:39: What if no users of Latin, Greek, or Cyrillic scripts remained? Future linguists would have to figure out that
The difference between Turkish i and ı is like that between Khitan small script- i (with a dot) and ı (without a dot) are different letters in Turkish
- a and ɑ aren't different letters
- σ and ς aren't different letters
- т and т аren't different letters
105One dot makes a big difference.<ud> and 106
<uŋ>
But the differences between
may or may not be like the differences between a and ɑ, σ and ς, or т and т.
11.7.14.23:54: KHITAN SMALL SCRIPT 8: B-Y THE NUMBERS
Thanks to Andrew West for giving me some statistics on a few <b>-phonograms in five Khitan small script texts with a total of 3,363 phonograms and logograms:
| Phonogram | Kane # | Kane transcription | Position in polygram | ||
| Initial | Medial | Final | |||
| 176 | <bú> | 7 | 1 | 7 | |
| 272 | <bú> (same as 176 but with bottom left dot) | 0 | 8 | 5 | |
| 196 | <bu> (coincidentally, 生 has a Japanese reading bu) | 0 | 45 | 4 | |
| 225 | <bi> | 0 | 0 | 3 | |
| 288 | <bun> | 9 | 2 | 30 | |
| 311 | <b> ~ <bo> | 50 | 73 | 22 | |
The absence of <bu> and <bi> in initial position is curious. Were words with initial *bu- and *bi- rare, or were they spelled with phonogram sequences <b.u> and <b.i> instead of single phonograms <bu> and <bi>? (The reasoning, if any, behind choosing sequences or single phonograms is still elusive.) The complete absence of medial <bi> is also surprising. However, one should keep in mind that extant Khitan texts are limited in genre as well as number. Perhaps many words with initial *bu- and initial/medial *(-)bi- didn't happen to be used in inscriptions. It's possible that many Khitan words were never written, not even if there was a wealth of lost Khitan script literature. After all, there are many 'characterless' words in modern Chinese languages that could be written phonetically but aren't.
The highest frequencies in each position in this small sample are in bold.
<bun> is a common past tense ending. I plan to write more about this ending later.![]() <b> ~ <bo> has two readings. Kane (2009: 32) has chosen
<o> as an "inherent vowel" for labial consonant phonograms.
<o> is a reasonable choice for <bo> since
<b> ~ <bo> has two readings. Kane (2009: 32) has chosen
<o> as an "inherent vowel" for labial consonant phonograms.
<o> is a reasonable choice for <bo> since
- there is no other phonogram <bo>
- <b> appears at the end of
<tai.bo> ~
<tai bo> < Chn 太保 *thaipɔu
I doubt that <tai.bo> ~ <tai bo> represented *taib. (See Kane 2009: 118 for the context of <tai bo>.)
However, it is not clear whether words like 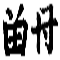 <WINE.bo>
ended in *-b or *-bo.(The reading of
<WINE.bo>
ended in *-b or *-bo.(The reading of ![]() <WINE> is
unknown.
<WINE> is
unknown. ![]() <bo> may be an accusative suffix since 'wine' is the object of
the verb
<bo> may be an accusative suffix since 'wine' is the object of
the verb  <êm.ci> 'after ... drank'. See Kane 2009: 154 for
context.) Thus the 22 instances of final
<êm.ci> 'after ... drank'. See Kane 2009: 154 for
context.) Thus the 22 instances of final ![]() <b> ~
<bo> may represent *-b and/or *-bo.
<b> ~
<bo> may represent *-b and/or *-bo.
7.15.3:59: Another example of an ambiguous word is  <hor.bo>,
transcribed in Chinese as 何魯不 *xɔlupu. This word could have
been *ɣorbo or *ɣorb. (<h> represents *ɣ.
See Kane 2009: 29.) It may be related to a name
<hor.bo>,
transcribed in Chinese as 何魯不 *xɔlupu. This word could have
been *ɣorbo or *ɣorb. (<h> represents *ɣ.
See Kane 2009: 29.) It may be related to a name  <hor.bo.ń>, transcribed in Chinese as 曷魯本 *xɔlupun
(Kane 2009: 40, 196).
<hor.bo.ń>, transcribed in Chinese as 曷魯本 *xɔlupun
(Kane 2009: 40, 196).
11.7.13.23:59: KHITAN SMALL SCRIPT 7: A-B-SENCE
Andrew West and I have been recently discussing *-b-loss in Khitan. Andrew noted instances of Khitan zero corresponding to Written Mongolian -b-:
Note that M b precedes a high labial vowel in all these cases. On Tuesday, I proposed thatK <heu.úr> : WM qabur 'spring'
K <u.ul> = WM ebül (winter)
K <tau> = WM tabun (five)
Proto-Mongolic *VbU > *VβU > K <VU>
with V representing any vowel and U representing any high labial vowel. (It is not clear how Khitan <u> differed from <ú>. The acute accent only indicates the potential presence of a distinction whose details are unknown.) This shift did not occur in the ancestor of Written Mongolian which preserved PM *-b- even after Khitan became extinct.
I cannot propose a general rule
PM *VbV > *VβV > K <VV>
because there are native Khitan words which have an unlenited intervocalic <b>: e.g.,
<ho.le.bo.ń> 'first; first day of the lunar month; preface; a name' (Kane 2009: 98; also see below)Even my more specific rule cannot account for words with an unlenited intervocalic <b> before <u>: e.g.,<ci.is.de.bo.ń> 'filial piety' (Kane 2009: 98; also see below)
<p.o.ju.bo.ń> 'appointed' (Kane 2009: 201; also see below)
and perhaps <ủ.bo> '?' (Kane 2009: 88; <ủ> is a placeholder reading; the actual reading is most likely some <(C)V> syllable rather than <C> since Khitan did not have initial consonant clusters)
<a.bu(i)ń> 'hexagram' (Kane 2009: 25, 67, 118)
<ci.bu.qó> (a tribal name; Kane 2009: 55)<te.bu.ei.er> ~ <te.bu.ei.i> (a personal name; Kane 2009: 59)
<se.bu.o.ho> 'inherited the throne' (Kane 2009: 63)
<le.bu.uh> (a personal name; Kane 2009: 68)
<doro.le.b.ún> ~ <doro.le.bun> '?' (Kane 2009: 69)
<p.o.ju.bun> ~ <p.o.ju.bún> 'appointed' (Kane 2009: 147; also see above)
<hó.le.bun> ~ <hó.le.bún> 'first; first day of the lunar month; preface; a name' (Kane 2009: 69, 173; also see above)
<se.bu.iń> '?' (Kane 2009: 196)
<ha.bu.cẻn> '?' (Kane 2009: 206)
<te.bú.a.án> '?' (Kane 2009: 208)
Is lenition of morpheme initials forbidden? Even if it was, are all of these words polymorphemic: i.e., combinations of a monosyllabic root plus a bu-root or suffix (e.g., the past tense suffix <bun> ~ <bún>)? Are these <bU> secondary? Could there have been a chain shift like
*VNbu > *Vbu > *Vu
in which
primary *b was lost between a vowel and *u
secondary *b developed from earlier *Nb
Are there Khitan words with nasals before <b>? If not, then perhaps *-Nb- simplified to *-b-.
Lenition did not occur in Chinese loans (which must have been borrowed after lenition occurred): e.g.,
<l.i b.û> < 禮部 *lipu 'ministry of rites' (Kane 2009: 18)
<xu.ú bu> < 戶部 *xupu 'ministry of revenue' (Kane 2009: 201)
(The fact that these words were not written as polygrams like <l.i.b.û> and <xu.ú.bu> suggest that Khitan speakers treated Chinese syllables as phonological words even though they were polysyllabic lexical items: i.e., <l.i> , <xu.ú>, <b.û>~<bu> may not have been independent words in Khitan.)
Clusters block lenition: e.g., <rb> and <db>:
<tu.úr.bún> ~ <tu.úr.boń> 'died' (Kane 2009: 91)
<ci.i.is.d.bun> 'filial' (Kane 2009: 98; also see above)
<hur.ú.ur.bun> 'humaneness' (Kane 2009: 102)
<nad.bu> 'travelling palace' (Kane 2009: 108)
Are there any Khitan words ending in <b>? Did final <b> lenite to <u>? Perhaps <tau> 'five' is from *tab < *tabu. Cf. Mandarin 入 ru < *riu < *ʒip.
All of the above words contain medial <b> before a labial vowel. Are there any Khitan words with medial <b> before nonlabial vowels?
11.7.12.23:54: MY RÊCÔNSTRUCTÎON OF OLD JAPANESE VÖWËLS
(I couldn't insert Ï in there. Ï happens to be the rarest of the OJ vowels.)
I was asked to briefly explain the reasoning behind my reconstruction of the vowels of Old Japanese (OJ).
The descendants of Old Japanese syllables are pronounced as consonant-vowel (CV) syllables.
Modern Japanese has only five vowels (a i u e o) which correspond to eight postconsonantal distinctions (a î ï u ê ë ô ö). (I am oversimplifying.) For convenience, I will call these distinctions 'vowels'. The vowels with circumflexes (^) are often called 'A-type' or 甲類 kourui whereas the vowels with umlauts or diaereses (¨) are often called 'B-type' or 乙類 otsurui:
A/甲類: î ê ô
B/乙類: ï ë ö
Ambiguous i e o in Old Japanese are written without diacritics. These vowels can be called 'C-type' or 丙類 heirui.
OJ a and u belong to none of those categories, unless one equates 'type C' with 'transcribed sans diacritics'. They correspond to modern Japanese a and u.
a is roughly if not exactly the same in both modern Japanese and Old Japanese.
Modern Japanese u is unrounded [ɯ] whereas OJ u was rounded *[u]. The latter was transcribed with Chinese characters with rounded vowels: e.g., OJ ku was transcribed as 久 which was borrowed into Korean as ku, not kɯ (also a possible syllable in Korean). Moreover, later transcriptions in Korean and Roman letters point to rounded *[u] for the intermediate stages of this vowel between OJ and modern times.
Assumption: The vowels of Korean and Vietnamese readings of Chinese characters (Sino-Korean [SK] and Sino-Vietnamese [SV]) borrowed from Middle Chinese circa the 8th and 10th centuries respectively are relatively conservative because they more or less match each other even after over a millennium of separate development and retain traits still present in colloquial Taiwanese which is more archaic than other Chinese languages in some respects. (The colloquial Taiwanese reading of 久 is ku, which is identical to the SV reading aside from tone and much more conservative than Mandarin jiu < *kiu < *ku). If Korean and Vietnamese speakers had considerately altered the vowels of their Chinese character readings, SK and SV should have very different vowels, since parallel developments are unlikely.
The other six OJ vowels are more controversial than a *[a] and u *[u].
Internal reconstruction indicates that four of the six originated from diphthongs:
OJ ê:
OJ kêr-u 'wear-FIN'< kî- 'wear' + ar-u 'be-ATT'
OJ pêkî (personal and place name) < pî 'sun' + ok-î 'put-GER'
OJ ï:
OJ opïsi 'large rock'< opö- 'large' + isi 'rock'
OJ wakïratukô (personal name) < waku 'young' + iratukô 'honored male'
OJ ë:
OJ takëti (place name) < taka 'high' + iti 'market'
OJ töneri < ?tönëri 'palace servant' < tönö 'palace' + ir-i 'enter-GER'
OJ ô:
OJ kazôp-u 'count-FIN' < kazu 'number' + ap-u 'join-FIN'
OJ sitôri 'kind of native weaving' < situ 'native weaving' + or-i 'weave-GER'
OJ î and ö, on the other hand, do not have diphthongal origins. Pre-Old Japanese must have had at least four vowels: *a, *î, *u, *ö.
External evidence such as Sino-Korean and Sino-Vietnamese indicate that the six vowels can be classified into three types:
1. Palatals
1a. OJ î-syllables were transcribed with Chinese characters whose SK and SV readings end in [i]: e.g.,
比 OJ pî : SK pi, SV tỉ < ́*pji
岐 OJ kî: SK ki, SV kỳ [ki]̀
Conclusion: OJ î was *[i].
1b. OJ ê-syllables were transcribed with Chinese characters whose SK readings end in [e] < [əj] (the closest earlier Korean approximation of foreign *e) and whose SV readings end in [e].
幣 OJ pê: SK phe < phjəj, SV tệ [te] < *bje
計 OJ kê: SK ke < kjəj, SV kế [ke]
OJ ê originates at least in part from pre-OJ diphthongs with the palatal vowel *i. (See above.)
Conclusion: OJ ê was a palatal vowel like *[e].
2. Neutrals (neither palatal nor labial)
2a. OJ ö-syllables were transcribed with Chinese characters whose SK and SV readings contain unrounded vowels such as [ɨ], [ə], [a]: e.g.,
登 OJ tö: SK tɨŋ, SV đăng [ɗaŋ]
舉 OJ kö: SK kə, SV cử [kɨ]
Conclusion: OJ ö was a neutral vowel like *[ə].
2b. OJ ï-syllables were transcribed with Chinese characters whose
- SK readings end in [i] < [ɨj]: e.g.,
紀 OJ kï: SK ki < kɨj (There is no SK kɨ.)
- SV readings end in [i] preceded by non-palatalized consonants: e.g.,
彼 OJ pï: SV bỉ [ɓi] < *pi (There is no SV bư [ɓɨ] < *pɨ.)
On the other hand, the SV readings of graphs for OJ labial î-syllables were preceded by dentals from palatalized labials: e.g.,
比 OJ pî : SV tỉ < ́*pji
OJ ï originates from pre-OJ diphthongs with neutral vowels plus i. (See above.)
Conclusion: OJ ï was an i-like neutral vowel like *[ɨ].
2c. OJ ë-syllables were transcribed with Chinese characters whose SK and SV readings end in nonpalatal vowel + [j] diphthongs: e.g.,
每 OJ më: SK mɛ < mʌj, SV mổi [moj]
開 OJ kë: SK kɛ < kʌj, SV khai [xaaj] < *khaaj
OJ ë originates from pre-OJ nonpalatal vowel + *i diphthongs. (See above.)
Conclusion: OJ ë was a nonpalatal vowel + [j] sequence like *[əj].
3. Labial
OJ ô-syllables were transcribed with Chinese characters whose SK and SV readings end in [o]: e.g.,
圖 OJ dô: SK to, SV đồ [ɗo]
古 OJ kô: SK ko, SV cổ [ko]
OJ ô originates at least in part from pre-OJ diphthongs with the rounded vowel *u. (See above.)
Conclusion: OJ ô was something like *[o].
Alternate reconstructions
There is no way to be sure about the exact vocalism of OJ.
It's possible that some of the vowels may have had glides corresponding to high vowels in their diphthongal sources: e.g., *[je], *[ɨj] ~ *[ɨɰ], *[wo].
Although I am certain that the neutral vowels ï, ë,and ö were less palatal and labial than î, ê, and ô, that view still allows reconstructions with noncentral vowels: e.g., *[ɪ], *[ɛ], *[ɔ].
Any or all of the above variants could have coexisted within one or more dialects. The Chinese character-based man'yougana writing system was not IPA. Although Middle Chinese had many more syllables than OJ, not every OJ syllable necessarily had a soundalike in Middle Chinese. A lot of man'yougana spellings may have been approximations at best.
7.13.3:43: Addendum: a statistical argument
Assumption: Monophthongs are more common than diphthongs.
Facts: Excluding the ambiguous 'type C' vowels, the four most common OJ vowels are
1. a
2. u
3. ö
4. î
followed by
5. ô
6. ë
7. ê
8. ï
Detailed statistics are on p. 237 of my book.
Notice that the first four cannot be traced back to diphthongs and are glideless simple vowels in my reconstruction:
*[a], *[u], *[ə], *[i]
The second four can be traced back to diphthongs and may even have had glides in OJ:
*[wo], *[əj], *[je], *[ɨj] (or *[ɨɰ]?)
The glides - if any - of *[wo], *[je], *[ɨj] ~ *[ɨɰ] were nondistinctive and can be omitted in phonemic analyses:
*/o/ */e/ */ɨ/
The glide of *[əj] was distinctive and cannot be omitted in a phonemic analysis: /əj/.
Warning
This is only a brief summary of pp. 198-264 of my book plus various other parts of it. This post excludes many compliations:
- how to reconstruct the 'type C' vowels
- differences between strata of man'yougana and Sino-Vietnamese
- Ryukyuan evidence for Proto-Japonic reconstruction
- new theories about pre-Old Japanese *e and *o and perhaps even *ɨ which merged with POJ *i, *u, *ə
- several other types of evidence for Middle Chinese pronunciation: e.g.,
- Tibetan transcriptions of MC
- MC transcriptions of Indic languages
- the comparison of modern Chinese languages
NB: I have not used Middle Chinese reconstructions at all in this post. I have used SK and SV readings in lieu of reconstructions. Readings are real; reconstructions are not. The latter come and go as theories change. I wanted my OJ reconstruction to be based on solid facts.
11.7.11.23:59: KHITAN SMALL SCRIPT 6: 8 + 7 = 10
The terms 'large script' and 'small script' for the two Khitan scripts - and the larger percentage of logograms in the 'large script' - may imply that the Khitan large script (KLS) is somehow more complicated than the Khitan small script (KSS). Although it is true that the KSS is better understood than the KLS (even though the latter is superficially more similar to the far more familiar Chinese script!), in some cases, KSS characters are more complicated than their large script equivalents: e.g.,
'one': KLS(1 stroke) vs. KSS
(3 stroke) ~
(4 strokes)
'ten': KLS
(2 strokes) vs. KSS
(4 strokes) ~
(5 strokes)
The dotted forms are used before masculine nouns. It's not clear whether KLS numeral graphs had two readings corresponding to dotless and dotted KSS numeral graphs. (It's possible that KLS represented a Khitan dialect without grammatical gender whereas KSS represented a Khitan dialect with grammatical gender. It's also possible that gender was only indicated in the KSS and not in Khitan speech: cf. the distinction between blond and blonde that some writers make in English. But the English blond/blonde distinction is influenced by French, whereas there is no Chinese precedent for written gender in Khitan.)
KLS ![]() 'ten' is identical to Chinese 十 'ten' (and KSS
'ten' is identical to Chinese 十 'ten' (and KSS ![]() 'west'!),
whereas the KSS character for 'ten' looks like Chinese 八 'eight' (and
KSS
'west'!),
whereas the KSS character for 'ten' looks like Chinese 八 'eight' (and
KSS ![]() 'Chinese mile') atop Chinese 七 'seven' (which doesn't look like any KLS
or KSS character that I know of). The Khitan were literate in Chinese.
Why create 'ten' out of 'eight' and 'seven'? Could 七 be derived from KLS
'Chinese mile') atop Chinese 七 'seven' (which doesn't look like any KLS
or KSS character that I know of). The Khitan were literate in Chinese.
Why create 'ten' out of 'eight' and 'seven'? Could 七 be derived from KLS
![]() 'ten'?
If so, why add KSS
'ten'?
If so, why add KSS ![]() 'Chinese mile' on top?
'Chinese mile' on top?
The Khitan word for 'ten' is unknown, though it could be like *hon judging from what might be Khitan loans in Jurchen (Kane 2009: 63). Could the KSS character be a partial rebus?
(If KSS ![]() 'Chinese mile' were *hon, then
'Chinese mile' were *hon, then ![]() could be a
phonetic-semantic compound with KLS
could be a
phonetic-semantic compound with KLS ![]() 'ten' altered on
the bottom to keep
'ten' altered on
the bottom to keep ![]() 'ten' from being confused with KSS
'ten' from being confused with KSS ![]() <s> which has 人 instead of 八 on top. But are there any other KSS
characters that are (a) phonetic-semantic compounds and (b) based on
KLS characters?)
<s> which has 人 instead of 八 on top. But are there any other KSS
characters that are (a) phonetic-semantic compounds and (b) based on
KLS characters?)
Knowing the readings and meanings of Khitan characters isn't enough for me. I want to understand why those readings and meanings are assigned to certain shapes.
Incidentally, ten also happens to be the maximum number of strokes in KLS characters according to Andrew West's statistics and it's also the number of strokes in the most complex KSS character that I know of,
qudug 'happiness'
which Kane (2009: 81) regards as a single graph based on Chn 福 'good
fortune' but others regard as a sequence of two graphs: KSS 335-277 ![]()
![]() .
.
11.7.10.23:59: KHITAN SMALL SCRIPT 5: ANDREW WEST'S "A MIRROR ON THE KHITAN LANGUAGE"
Andrew has written a long and informative post on "a bronze mirror [...] that had been unearthed in Inner Mongolia" with an inscription in the Khitan small script (KSS). A few notes on its characters follow:
1. KSS 243 ![]() 'heaven': Looks like Chinese 天 'heaven' with
the top
horizontal line broken to resemble Chinese 八 'eight' and KSS 239 八
'Chinese mile' (Kane 2009: 63) which doesn't look like Chinese 里
'Chinese mile'.
'heaven': Looks like Chinese 天 'heaven' with
the top
horizontal line broken to resemble Chinese 八 'eight' and KSS 239 八
'Chinese mile' (Kane 2009: 63) which doesn't look like Chinese 里
'Chinese mile'.
~
KSS 247-093 <te.gẻ> ~ 254-093 <de.gẻ> 'below', 'south'?
also has ![]() <t> ~
<t> ~ ![]() <d> variation. Other examples are the KSS version of the Liao
Dynasty era name 大康 and the Jin Dynasty era names 天會 and 天眷
(written in KSS even though the Jin were Jurchen, not Khitan). See
appendices 1.1 and 1.2 of Andrew's post.
<d> variation. Other examples are the KSS version of the Liao
Dynasty era name 大康 and the Jin Dynasty era names 天會 and 天眷
(written in KSS even though the Jin were Jurchen, not Khitan). See
appendices 1.1 and 1.2 of Andrew's post.
KSS 247 <t> may correspond to Chinese *t and *th (Kane 2009: 64).
Could <t> ~ <d> variation be dialectal? Or are the two characters mixed even within the same inscription: e.g., <d.iu.rẻn> 'virtue' with <te.gẻ> 'below' or <t.iu.rẻn> 'virtue' with <de.gẻ>?
Only the vowels of the first half of 'virtue' are certain: *Tiu ...
4. KSS 122 ![]() 'year' (derived from the reversed bottom of Chn 年 'year'
minus its first two
strokes?) is probably <ai> as in the following
polygram (KSS character combination).
'year' (derived from the reversed bottom of Chn 年 'year'
minus its first two
strokes?) is probably <ai> as in the following
polygram (KSS character combination).
5. ![]()
![]() <ai.en> is 'year' plus the genitive suffix
<en>, "the most frequent of the genitive endings" that "mainly
follows consonants (including the semivowel i)" (Kane 2009:
132).
<ai.en> is 'year' plus the genitive suffix
<en>, "the most frequent of the genitive endings" that "mainly
follows consonants (including the semivowel i)" (Kane 2009:
132).
6. Could <se.l.bo> mean something like 'cycle'? 5-6 would then mean 'cycle of years'.
7. The dotted variant of KSS 004 ![]() 'white' (KSS
005
'white' (KSS
005 ![]() ) may modify a masculine noun. Hence 8 <mo.ri> cannot
be
translated as 'mare'.
) may modify a masculine noun. Hence 8 <mo.ri> cannot
be
translated as 'mare'.
8 (added 7.11.1:01). KSS 235 ![]() <ri> may also have been read *ir
(Kane 2009: 32, 62). Its right half 乚 resembles 乙 which was read *ʔɨr
in 8th century northern Late Middle Chinese (judging from how its
reading was
borrowed into Old Korean as *ʔɯr). However, by the 10th century
when the Khitan scripts were invented, 乙
was read as *ʔi without an *r, so it would be an
unlikely inspiration for a KSS *ir ~ *ri graph.
<ri> may also have been read *ir
(Kane 2009: 32, 62). Its right half 乚 resembles 乙 which was read *ʔɨr
in 8th century northern Late Middle Chinese (judging from how its
reading was
borrowed into Old Korean as *ʔɯr). However, by the 10th century
when the Khitan scripts were invented, 乙
was read as *ʔi without an *r, so it would be an
unlikely inspiration for a KSS *ir ~ *ri graph.
9. KSS 033 ![]() 'nine' looks like Chinese 天 'heaven' above 人 'person'.
Could
the shape 天 in 'nine' be a reference to the 九天 'nine heavens' in
Chinese?
'nine' looks like Chinese 天 'heaven' above 人 'person'.
Could
the shape 天 in 'nine' be a reference to the 九天 'nine heavens' in
Chinese?
(7.11.00:21: 'Nine' also has a dotted variant KSS 034 ![]() . There is no
dot on 'nine' before 'month' and 'day', implying that those two nouns
were not grammatically masculine.)
. There is no
dot on 'nine' before 'month' and 'day', implying that those two nouns
were not grammatically masculine.)
10. KSS 081 ![]() 'month' may have represented the same word as
the Chinese
transcriptions of a Khitan word for 'month:
'month' may have represented the same word as
the Chinese
transcriptions of a Khitan word for 'month:
賽離 *saili
賽咿唲 *saiiri
Cf. Written Mongolian sara-n 'moon, month'.
11. (7.11.1:51: It is not known why
<s.iau.qu> and <s.iau.qú> 'blue'
have a variant
<se.mú.qu>
with <mú> instead of <iau>.
Kane's transliteration inserts an <e> after KSS 244 ![]() <s> to
break up what would otherwise be a consonant cluster.
<s> to
break up what would otherwise be a consonant cluster.
Although Kane 2009: 58 lists no reading for KSS 191 ![]() , he
transliterates it as <mú> on pp. 147 and 198 and in his index on
p. 303.
, he
transliterates it as <mú> on pp. 147 and 198 and in his index on
p. 303.
Moreover, it is not clear how the syllables represented by
KSS 224 220 191

<mu> <mú> <mú> (again!)
differed from each other. Acute accents in Kane's (2009: 26) transliteration indicate vowels that may have been the "same" or "very similar" to their unaccented counterparts.)
14. I'll write about 'ten' tomorrow.
16. I think of KSS 159 'day' as resembling Korean 곳 kot 'place', though there is no relationship between KSS and Korean hangul (apart from KSS being an inspiration for the 'polygrams' of hangul).
17. KSS 081 ![]() 'month' may be an error for KSS 082
'month' may be an error for KSS 082 ![]() <y> which has
an extra dot on the right. This
error may imply that 081 'month' sounded like 082 <y>. Since 082
<y> corresponds to Chinese *ü (IPA [y]), I wonder if it
was read as *ü (IPA [y]) rather than *y (IPA [j]) in
Khitan.
<y> which has
an extra dot on the right. This
error may imply that 081 'month' sounded like 082 <y>. Since 082
<y> corresponds to Chinese *ü (IPA [y]), I wonder if it
was read as *ü (IPA [y]) rather than *y (IPA [j]) in
Khitan.
(7.11.00:29: If the Khitan word for 'month' was something like *ü, could it have been a loan from Chinese 月? Cf. Hphags-pa Chinese <xwÿa>, which Coblin [2007: 173] interpreted as IPA *[ɦyɛ].)
18. <g.ui>-like pronunciations of Chn 國 'country' survive today in the nonadjacent dialects Xi'an (kue) and Chengdu (kue): cf. Hphags-pa Chinese <gue>. I wonder if a front vowel pronunciation was once more widespread. Perhaps standard guo [kuo] < *kuə (still intact in Jinan) has replaced the kui ~ kue of some Mandarin dialects.
A long-extinct Sino-Korean reading 귁 kwik < kuyk for 國 may reflect the ancestor of <g.ui> or be an artificial compromise between then-current Mandarin *kue and the normal Sino-Korean reading 국 kuk.
Kuyk is attested in the title of a Korean rhyme dictionary of Chinese characters:
東國正韻
:동·귁:정·운
lit. 'east country correct rhyme'
Tongkuyk tsyəngngun (1448) (modern reading: Tongguk chŏng'un)
(Correct Rhymes of the Eastern Nation)
This title has other oddities: double dots indicating rising tones for 東 (normally with a low tone corresponding to Chinese level tone) and 正 (normally with a high tone corresponding to Chinese departing tone) and initial ᅌ ng- for 韻.
The high tones (corresponding to Chinese entering tone and the departing tone) of 國 and 韻 were indicated by a single dot ·.
The low tone (corresponding to Chinese level tone; not in this title) was unmarked.











!["a bronze mirror [...] that had been unearthed in Inner Mongolia"](http://www.babelstone.co.uk/Khitan/UlanqabKhitanMirror.jpg){kind=link}