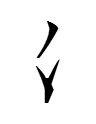11.6.25.23:50: ANDREW WEST'S ONLINE TANGRAPHIC SEA: FANQIE (PART 2)
Last night, I asked,
To answer this question, let's look at a database that I based on that section.You'll need Andrew's fonts to view it. I followed Andrew's format and added five extra columns:Why were some but not all tangraphs [Tangut characters] without homophones listed at the end of the section for rhyme 1 in the Tangraphic Sea?
1. Homophone group: Each group of tangraphs sharing a fanqie spelling has the same homophone group number. Groups 8, 12, 13, 16, 19-24 contain only a single tangraph. In other words, those tangraphs have no homophones.
2. Initial Class: The Tangut categorized consonants into nine classes:
I. Labial
II. Labiodental
III. Dental
IV. 'Retroflex' (rare and mysterious; almost certainly not retroflex; hence the scare quotes)
V. Velar
VI. Alveolar
VII. Alveopalatal
VIII. Glottal (including velar fricatives that might have been uvular or glottal)
IX. Liquid (including z- which may have been an l-like [ɮ])
Not all classes occur with all initials. Classes II, IV, and VII do not occur before rhyme 1. Patterns of co-occurrence can help us reconstruct probable sound values for initials and rhymes.
3. Initial: Initial consonant. Clusters with -w- are regarded as initial + medial -w- sequences. See the next column.
4. Medial: Some tangraphs have a medial -w-.
5. Rhyme: All tangraphs in this table have rhyme 1 -əu with a level tone.
These columns clarify how the homophone groups (HGs) were organized:
- HGs without a medial -w- precede all HGs with a medial -w-
- Within each larger class of HGs (the -w-less class, the -w-class), HGs are listed in initial class order: I to IX.
- Within each initial class, HGs are listed according to initial qualities:
1. unaspirated first: e.g., p-
2. aspirated second: e.g., ph-
3. voiced third: e.g., b-
4. nasal fourth: e.g., n- follows aspirated th- (there is no d-)
5. fricative last: e.g., s- follows aspirated tsh- (there is no dz- and no class VI nasal)
The cluster of single-member HGs at the end (19-24) turn out to represent Cwəu syllables.
The other single-member HGs (8, 12, 13, 16) represent -w-less Cəu syllables.
There are several HGs in the middle which Gong Hwang-cherng and I have reconstructed as homophonous:6 and 7: nəu
9 and 10: khəu
13 and 14: tshəu
Are we wrong? I'll look into these pairs in the near future.
Next: A question of construction.
11.6.24.22:57: ANDREW WEST'S ONLINE TANGRAPHIC SEA: FANQIE (PART 1)
Andrew has added the fanqie pronunciation formulae for the tangraphs (Tangut characters) listed under rhyme 1 in his digital edition of the Tangraphic Sea: e.g., the very first fanqie in the "Fanqie" column is
pəi1 ləu1 vəi1 1lɨəəʳ1
The first two tangraphs represent the initial (p-) and the final (-əu with tone 1 = 'level tone').
(I normally write Tangut tones before syllables like Arakawa, but here I have placed them after syllables since the they are indicated by fanqie tangraphs for finals, not initials.)
The third tangraph represents 1vəi, the Tangut translation of Chinese 切 'cut'. 反切 fanqie literally means 'counter-cut', as it represents the pronunciation of a syllable (here, the Tangut syllabe pəu1) by cutting it in two
pəi1 > p- + -əu1
and then expanding each of the cut halves into an existing syllable:
p- > pəi1-əu1 > ləu1
The fourth tangraph represents 1lɨəəʳ 'four', the number of tangraphs sharing the pronunciation indicated by the fanqie formula. These tangraphs comprise a homophone group that is followed by a circle.
The fanqie formula in a row containing a circle applies to the following homophone group: e.g., 5.131-5.142 constitute one homophone group, 5.143-5.161 a second homophone group, etc.
If such formulae were applied to English syllables, an Anglographic Sea might have a homophone group likesee: sight key cut three
sea
C
See, sea, and C are the three homophones sharing the fanqie sight + key.
Can you come up with a fanqie formula for the homophone group Thai, tie?The first fanqie formula without a number at the end is
for
kʊ1 + təu1
which has no homophones.
1kəu 'therefore'
Most rhyme 1 (-əu) tangraphs without homophones are clustered at the end (6.243-6.271), though there are four that are in the middle such as 'therefore'.
Next: Why were some but not all tangraphs without homophones listed at the end of the section for rhyme 1?
11.6.23.23:10: ANDREW WEST'S ONLINE TANGRAPHIC SEA
... is only in skeletal form right now, but is still worth checking out, as it gives you an overall idea of the structure of the dictionary at a glance.
At the top of the page are tables of contents for the two surviving volumes:
- the 'level tone' volume containing tangraphs (Tangut characters) pronounced with the level tone, organized by rhymes each named after an arbitrary tangraph whose reading contains that rhyme: e.g.,
represents level tone rhyme 1 -əu.
1bəu 'preface' (1 = 'level tone')
(- the 'rising tone' volume also organized by rhymes is missing)
- the 'mixed categories' volume containing tangraphs pronounced with initial dz- and dʒ- and miscellaneous other tangraphs, organized by tone and initial class (not rhyme!)
This volume is in poor shape, so tangraphs for the first three initial classes (labial, labiovelar, dental) are partly or wholly missing.
I still have no idea why dz- and dʒ-tangraphs received special treatment or why the other tangraphs in the third volume weren't listed in the first or second volumes. Moreover, why were the organizational principles of the dictionary changed in the last volume? Do mixed categories tangraphs represent syllables with stable initials and variable rhymes? But why would all dz- and dʒ-syllables have variable rhymes?
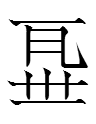
Entries in the Tangraphic Sea are divided into homophone groups by circles. For example, the first homophone group is
| Tangraph | Tone | Rhyme | Reading | Gloss | Components |
 |
level | 1 (-əu) | pəu | the surname Pu | abbreviation of homophone 'a kind of bird' (see below) on left/top right (phonetic) + 'horn' on bottom right (semantic? symbol of the Pu family?) |
 |
a kind of bird | abbreviation of homophone 'the surname Pu' (see above) on left/top right (phonetic) + 'bird' on bottom right (semantic) | |||
|
|
to choke oneself | abbreviation of 'narrow' on top (semantic) + 'mouth' on bottom (semantic) | |||
|
|
barnyard grass | 'grass' on left (semantic) + abbreviation of homophone 'a kind of bird' (see above) on right (phonetic) |
followed by a circle. Although some share common elements, there is no element that they all share. Moreover, there is no element that they share with all other level tone rhyme 1 tangraphs. This tells us that tangraphy was not a simple phonetic script.
The "Fanqie", "Construction", and "Definition" columns are currently empty.
"Fanqie" refers to the formula used to represent a pronunciation of a tangraph in terms of two other tangraphs: e.g.,
1pəu = 1pəi + 1ləu
"Construction" refers to the derivation of a tangraph in terms of two or more other tangraphs: e.g.,
Construction formulae are often circular: e.g., 'a kind of bird' is derived from 'the surname Pu'!
1pəu 'the surname Pu' = 1pəu 'a kind of bird' (phonetic) + 1piẽ 'horn' (semantic?)
1pəu 'a kind of bird' = 1pəu 'the surname Pu' (phonetic) + 1dʒɨõ 'bird' (semantic)
Which came first, the surname or the bird? Were they derived from a common component rather than from each other? At least some circular formulae must be wrong. A cannot be from B if B is derived from A.
I conclude that the construction formulae do not necessarily reflect the intent of the script's creator(s), even though the Tangraphic Sea was only written decades after the script's creation when that intent was still in living memory.
11.6.22.23:55: ANDREW WEST'S ONLINE TANGRAPHIC SEA INDEX: RADICALS AND RHYMES
If you've installed the three fonts for Andrew's index, try looking up the three Tangut characters
'writing', 'sea', 'level'
which comprise the title of the first volume of the Tangraphic Sea dictionary.
How to find Tangut characters in five (tedious) steps:
1. Determine the radical (top or left-hand component).
2. Determine how many strokes the radical has.
3. Find the radical among the radicals with that number of strokes.
4. Click on the name of the radical: "Radical (number)". The names are links that will take you to the list of characters with that radical.
5. Scroll down that list until you find the character you're looking for.
Having looked up thousands of tangraphs (Tangut characters) since 1996, I'm used to that process. The trouble is that every Tangut dictionary has its own idiosyncratic index, so one has to learn many variations on the art of tangraphic hunting.
Select the blank space below to see the radicals, stroke counts for radicals, and index numbers for the three tangraphs:
If you look at the "Entry" columns for tangraphs listed under each radical, you'll notice that'writing': radical 18 ('horned hat'; 3 strokes), 0606, XHZD 2008 4797
'sea': radical 39 (3 strokes), 1097, XHZD 2008 0661
'level': radical 39 (3 strokes), 1094, XHZD 2008 0218
- Ping ('level tone' / volume 1) alternates with Za ('mixed' / volume 3) and blanks (indicating that the tangraph was probably in volume 2 for rising tone syllables)
- Folio numbers are not adjacent: e.g., the first five known folio numbers for tangraphs under radical 1 are 19, 62, 33, 34, 11. Tangraphic Sea is organized by rhymes. Tangraphs with the same rhyme would be in the same folio or in adjacent folios: e.g., level tone rhyme 1 is in folios 5-6, level tone rhyme 2 is in folios 6-8, etc. Scattered folio numbers indicate that tangraphs with the same radical do not have the same rhyme: e.g., under radical 1,
tangraph 0001 (folio 19) has level tone rhyme 13
tangraph 0002 (folio 62) has level tone rhyme 56
(folio number for tangraph 0003 unknown; has rising tone rhyme 42)
tangraph 0004 (folio 33) has level tone rhyme 27
tangraph 0005 (folio 34) has level tone rhyme 27
tangraph 0006 (folio 11) has level tone rhyme 5
This tells us that radical 1 was not a phonetic symbol for a specific rhyme, though later investigation might reveal that these rhymes were phonetically similar. That doesn't happen to be the case for the rhymes of tangraphs 0001-0006:
level tone rhyme 13: -ɪ
level tone rhyme 56: -ɨõ
rising tone rhyme 42: -o
level tone rhyme 27: -ə
level tone rhyme 5: -əuu
Nonetheless, phonetic radicals are far from implausible since Chinese characters may share phonetic components: e.g., the radical 麻 is a phonetic for Mandarin m-syllables: 嘛 ma, 麽 me, 摩 mo, etc.
11.6.21.23:14: ANDREW WEST'S ONLINE TANGRAPHIC SEA INDEX
The Tangraphic Sea
2ʔwɨəʳ 2ŋiow
(the 2 indicates the following syllable is pronounced with the second [i.e., 'rising'] tone of Tangut)
is an 11th century monolingual dictionary of tangraphs - characters devised for the extinct Tangut language. Andrew West explained how it works in "Untangling the Web of Characters".
Shi Jinbo et al.'s Wenhai yanjiu (WHYJ, Research on the Tangraphic Sea, 1983) contains an index of tangraphs in the Tangraphic Sea. Andrew West has created an electronic version of this index. Install his fonts to view the tangraphs and their 'radicals' (shared left-hand or top components*). The index is organized by radicals. For example, tangraphs such as
share a common left-hand component
radical 1
and are therefore listed under radical 1. These radicals may or may not correspond to components that the inventor(s) of tangraphy had in mind. They are simply modern devices to help modern scholars find tangraphs without knowing how they are pronounced.
Each tangraph in the index has a unique index number: e.g., the first tangraph in the index is 0001. There is no universally accepted set of numbers representing tangraphs, though the numbers from Li Fanwen's 2008 Xia-Han zidian (Tangut-Chinese Character Dictionary) are much more commonly used than the WHYJ system. These numbers can be used as substitutes for tangraphs whenever it is not possible to display them (e.g., in email). One must ideally specific which numbering system one is using since 0001 by itself could refer to
WHYJ tangraph 0001
or
Li Fanwen 2008's completely different tangraph 0001
and so on.
The "Entry" columns contain four types of information:
1. The Chinese translation of the volume name. The Tangraphic Sea consists of three volumes:
- the 'Level (Tone)' (Chn 平 Ping) volume
- the 'Rising (Tone)' (Chn 上 Shang) volume (lost)
- the 'Mixed' (Chn 雜 Za, short for 類 Zalei 'Mixed Categories') volume
Each of the first two volumes contains tangraphs whose readings share a 'tone'. It is not clear whether the tone names (or even the term 'tone') are meant to be taken literally, as they may be inappropriately recycled Chinese terminology. The rationale for the final volume containing tangraphs for syllables with both 'level' and 'rising' tones is still not fully understood, though it is known that all dz- and dʒ-syllables were placed into the final volume regardless of their tones.
2. The folio number, followed by a period, and
3. The page, column, and character number of the Tangraphic Sea entry for the tangraph
4. The tangraph as written in the Tangraphic Sea entry (which may not match the way it was written in the index!)
Tangraphs that have no information in the "Entry" columns such as
WHYJ tangraph 0003
may have been in the lost 'rising tone' volume of Tangraphic Sea.
*This is not a universal definition of 'radical'. Other indexes of tangraphs (e.g., Grinstead 1972) are based on shared right-hand or bottom components.
11.6.20.3:40: THE EMERALD VOWELS OF THAI AND KHMER
My last few entries dealt with scripts (Old Lisu, Meroitic, Baybayin) with a single unwritten vowel after consonants: a.
Thai, my favorite modern Indic script, is much more complex. The word for 'emerald' has three different unwritten vowels after consonants:
มรกตThis is surprising because the word is ultimately from Sanskrit marakata with only a single kind of vowel. I presume that Thai mɔɔrakot 'emerald' was borrowed through Khmer
<mrkt>
mɔɔrakot
មរកត
<mrkt>
which now has two pronunciations -
mɔ(ɔ)rəkɑt ~ meaʔreaʔkɑt < *mɔ(ɔ/ʔ)rɔ(ɔ/ʔ)kɔt
- one with three different vowels and one with two:
- Khmer favors long vowels in open syllables
- ɔɔ shortens to ɔ in polysyllabic words between voiced labials (b, m) and r in colloquial speech (Huffman 1970: 65)
- unstressed *ɔ became ə in polysyllabic words (cf. Huffman 1970: 67)
- *ɔ broke to ea after glottal stops inserted after stressed short vowels. I suspect meaʔreaʔkɑt developed from a very careful pronunciation with three (!) stressed syllables: *mɔʔ-rɔʔ-kɔt.
- *ɔ lowered to *ɑ after a voiceless consonant
All this points to an Indian prototype *mɔrɔkɔt. Had *a already shifted to *ɔ in eastern Indic when Old Khmer borrowed from Indic speakers? If so, why is the inherent vowel in other Indic scripts outside India (e.g., Baybayin) a instead of o? Because those scripts were ultimately borrowed from speakers of Indic varieties without the *a > *ɔ shift, or because *ɔ was approximated as *a in languages lacking *ɔ?
I've long been puzzled by why Thai has -o- as the inherent vowel in closed syllables (e.g., <kt> -kot in <mrkt> mɔɔrakot) rather than -ɔ- which also exists in Thai. Perhaps it's because ɔ is less common than o in Thai. In fact, there are no native ancient Thai words with -ɔt (or -ɔ plus any final stop) (Brown 1985: 51). If Brown is correct, Thai once had *ɔɔ but no *ɔ. During such a period, the Thai would have borrowed Khmer <CC> *CɔC as *CoC.
Thai -a- corresponds to Khmer unstressed -ə-. How far back does unstressed schwa go in Khmer? If it existed in earlier Khmer, did the Thai borrow it as -a- because -ə- was rare in ancient Thai? According to Brown's (1985: 51) statistics, short a was the most common vowel in native ancient Thai words and short ə was the rarest. Brown (1985: 65) even went so far as to speculate that both short and long ə "most likely had no source in ancient Thai". I suspect that PT *ə became *əə in ancient Thai (with sporadic shortening) and that Khmer unstressed *ə was borrowed as *a.