and
and 
Last night, I listed all nine members of the 2si homophone group in Homophones (30A16-30A26). The code 30AXY refers to
- the page (30)
- the side of the page (A = right, B = left; Tangut is written in vertical columns from right to left)
- column X, numbered from right to left- tangraph entry Y, numbered from top to bottom
Here are the readings of all the tangraphs on page 30A:
| 7- | 6- | 5- | 4- | 3- | 2- | 1- | 30A |
| 2tsew | 2siə | 1tsiəʳ | 1tshie | 2sio | 2si | 2tsi | -1 |
| 2tsew | 1siə! | 1tsiəʳ | 1tshie | 2sio | 2si | 2tsi | -2 |
| 1swi | 2siə | 1dzəi | 1tshie | 2sio | 2si | 1tsi! | -3 |
| 1swi | 2siə | 1dzəi | 1tshie | 1sio | 2si | 2tsi | -4 |
| 2swi | 2siə | 1dzəi | 1tshiẽ | 1sio | 2si | 2tsi | -5 |
| 2swi | 2siə | 1dzəi | 1tshiẽ | 2tshie | 2si | 2si | -6 |
| 2swi | 2siə | 1siə | 1tsiəʳ | 2tshie | 1si | 2si | -7 |
| 1swi! | 1tsew | 2siə | 1tsiəʳ | 2tshie | 1si | 2si | -8 |
30A is in the sixth chapter for alveolar initials, so all the syllables begin with alveolar fricatives (s-) or affricates (ts- tsh- dz-). z- is missing from this chapter and is in the final chapter with liquid initials, so I suspect it was actually a lateral fricative [ɮ].
Level (1-) and rising (2-) tone tangraphs are generally grouped together with exceptions in bold. I don't know what to make of these exceptions. The tones listed here are according to the Tangraphic Sea and Precious Rhymes of the Tangraphic Sea. Is it possible that the tone of, say, 30A13 was 2 like its neighbors 30A12 2tsi and 30A14 2tsi in the dialect of the author of Homophones?
| 7- | 6- | 5- | 4- | 3- | 2- | 1- | 30A |
| 2tsew | 2siə | 1tsiəʳ | 1tshie | 2sio | 2si | 2tsi | -1 |
| 2tsew | 2siə? | 1tsiəʳ | 1tshie | 2sio | 2si | 2tsi | -2 |
| 1swi | 2siə | 1dzəi | 1tshie | 2sio | 2si | 2tsi? | -3 |
| 1swi | 2siə | 1dzəi | 1tshie | 1sio | 2si | 2tsi | -4 |
| 2swi | 2siə | 1dzəi | 1tshiẽ | 1sio | 2si | 2tsi | -5 |
| 2swi | 2siə | 1dzəi | 1tshiẽ | 2tshie | 2si | 2si | -6 |
| 2swi | 2siə | 1siə | 1tsiəʳ | 2tshie | 1si | 2si | -7 |
| 2swi? | 1tsew | 2siə | 1tsiəʳ | 2tshie | 1si | 2si | -8 |
The rhymes of the entries on 30A are not in the Tangraphic Sea order that is the basis of R-(rhyme) numbers:
| 7- | 6- | 5- | 4- | 3- | 2- | 1- | 30A |
| R44 | R31 | R92 | R37 |
R53 | R11 | -1 | |
| -2 | |||||||
| R11 | R8 | -3 | |||||
| -4 | |||||||
| R43 | -5 | ||||||
| R37 | -6 | ||||||
| R31 | R92 | -7 | |||||
| R44 | -8 | ||||||
R11 -i and R11 -wi are in columns at opposite ends of the page. Both the initials and rhymes are in apparently random order.
Chao Yuen Ren invented 通字 General Chinese (lit. 'general characters'). GC had only one sinograph for each of its 2085 syllables. (2085 is one-third less than the roughly 3000 sinographs in common use.) What if there were a 西夏通字 'General Tangut' with only one tangraph per syllable? In actual Tangut, there is usually a many-to-one ratio between tangraphs and syllables: e.g.,
both correspond to 1lew. The first 1lew means 'one' and the second 1lew is a borrowing from Tangut period northwestern Chinese *ləw 'building'. In General Tangut, both 1lew would be written as
'one'
and the distinction between them would be clear from context, just as it would be in speech.
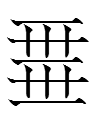
There are cases in which many tangraphs share the same reading: e.g., Homophones lists nine different tangraphs for 2si:
All these 2si would be written as
'mother' (cf. the shape of Chn 母 'mother')
in General Tangut. I don't know how many tangraphs would be necessary in General Tangut. My guess is about 2000 or less - two-thirds less than the 6000+ tangraphs of actual Tangut. Of course, learning to read and write romanized Tangut would be far more efficient.
In my posts on Tangut, we have seen tangraphs whose sole function is to write one half of a disyllabic Tangut word: e.g., the second halves of two words for 'death'. Chinese has similar one-function sinographs and even has one-function readings: e.g., Mandarin 冒 mao 'cover' is read mo only in the name 冒頓 Modun < Old Chinese *mək-tunh, the name of the founder of the 匈奴 Xiongnu Empire.
Japanese also has one-function readings. As far as I know, 幡 'banner', normally read
hata ( < *pata; native)
han (< *pan, borrowed from Late Middle Chinese *fan and Early Middle Chinese *phuan)hon (rare; < *pon < Early Middle Chinese *phuan)
is only read as man in the name 八幡 Hachiman. I have no idea why. The m does not match either the native or Chinese(-based) readings. I would expect Happan with -pp- < *-t-p-. The earliest reading of 八幡 is the wholly native *ya-pata 'eight-banner', now pronounced Yahata or Yawata in modern Japanese.
These 八幡 eight banners have nothing to do with the Eight Banners (jakūn gūsa) of the Manchu.
10.8.0:04: An even rarer Japanese reading of 幡 is ma in the place name 八幡 Hatsuma in Izu in Shizuoka Prefecture. But other places with the same spelling are Yahata or Yawata.
10.8.0:16: If ma(n) has no Japanese or Chinese origin, could it be from a language on the Korean peninsula? John Bentley pointed out that the man reading dates from after the unification of Korea, so it would have to be from Old Korean (Shilla) rather than from Koguryo, Paekche, or Kaya which were all extinct by then. Unfortunately, there is no evidence for a peninsular word *man 'banner'.
10.10.6.23:59: THE GOLDEN GUIDE: LINE 85: TANGRAPHS 421-425
85. So far, Tangutizations of Chinese names are close to the Chinese originals. But why was 褚 Tangutized as 1796 1tʃhɨụ 'to lure' with a tense vowel absent from Chinese? Tangut did have the syllable 1tʃhɨu with a lax (i.e., plain) vowel and even if it had happened to lack that syllable, a fanqie character could have been created for it.
| Tangraph number | 421 | 422 | 423 | 424 | 425 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 1234 | 2574 | 1796 | 2559 | 3193 |
| My reconstructed pronunciation | 1thiẽ | 2thi | 1tʃhɨụ | 1thõ | 1tshĩ |
| Tangraph gloss | (transcription of Chinese) | land < Chn 地 *thi | to lure | (transcription of Chinese) | (transcription of Chinese) |
| Word | the surname 田 Tian (*thiẽ) | the surname 狄 Di (*thi) | the surname 褚 Chu (*tʃhɨu) | the surname 唐 Tang (*thõ) | the surname 秦 Qin (*tshĩ) |
| Translation | Then, Thi, Chhu, Thon, Tshin | ||||
421: 1234 is probably a mirror-image version of
1079 1lɨẹ̃ 'sweet' (and also 'sour' according to Li Fanwen 2008: 180!)
since 1234 1thiẽ sounded like Chinese 甜 *thiẽ 'sweet'. However, 1079 isn't in the analysis of 1234, though 3190 corresponds to the 舌 'tongue' of 甜 'sweet':
+
1234 1thiẽ (transcription of Chinese) (hercuo) =
1564 1thie 'fields, open country' (fasher; phonetic)
loanword from Chn 田 1thiẽ 'field, farmland' despite imperfect semantic match?
3190 1lhwia 'tongue' (dexcuo; semantic; cognate to Old Chinese 舌 *mlat 'tongue')
422: 2574 2thi 'land' (analysis unknown) is probably derived from 2627 2lɨə̣ 'land; soil' plus the radical 'bottom':
423: 1796 may be a semantic compound:
+
1796 1tʃhɨụ 'to lure' (feepax) =
0397 2giu 'to fall' (feepaicok; semantic; to lure is to make someone fall into one's hands)
1640 1dziẹ 'to cross' (duupax; semantic?)
424: The analysis of 2559 may contain 'build' and 'house' because 1thõ sounds like Chinese 堂 *thõ 'hall':
+
2559 1thõ (transcription of Chinese) (baedexgir) =
1986 2diọ 'to build' (gaeqir; only the vertical line bae is extracted from gae) +
2560 2ʔiẽ 'tent, house, temple' (gaedexgir)
2559 transcribes many sinographs besides *thõ 'hall'. Some transcribed tangraphs like 大 *tho never had nasal vowels, so I wonder if such transcriptions reflect a (later?) Tangut dialect without nasal vowels.
425: 3193 is derived from a phonetic and a mirror image:
Were the Qin and In families in the Tangut Empire related?
+

3193 1tshĩ (transcription of Chinese; the Chiense surname 秦 Tshin) (dexhax) =
3278 1tshi 'food and drink' (dexgii; phonetic)
0494 1ʔĩ (transcription of Chinese; the Tangut surname In) (haxdex)
10.7.0:16: 3193 is not in the analysis of 0494:
+
0494 1ʔĩ (transcription of Chinese; the Tangut surname In) (haxdex) =
3213 1tsĩ 'the Tangut surname Tsin' (dexcirhax; semantic?; a clan related to the In?)
But 3213 has a circular analysis:2888 2mə 'surname' (dexpux; semantic; why dex rather than pux 'clan'?)
+
3213 1tsĩ 'the Tangut surname Tsin' (dexcirhax) =
3120 2tsi 'the Tangut surname Tsi' (dexcircor; phonetic) +
0494 1ʔĩ (transcription of Chinese; the Tangut surname In) (haxdex; semantic?)
10.10.5.23:54: THE GOLDEN GUIDE: LINE 84: TANGRAPHS 416-420
84. Once again, this line contains a mix of common and uncommon surnames. Their 2006 ranks are #1, #8, #4, #66, and (not in top 100; #83 in 1990).
| Tangraph number | 416 | 417 | 418 | 419 | 420 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 1142 | 5093 | 5259 | 0938 | 0683 |
| My reconstructed pronunciation | 2lɨi | 1tʃhɨew | 1lɨew | 1lɨi | 1xæ |
| Tangraph gloss | (transcription of Chinese) | (transcription of Chinese) | (transcription of Chinese) | prosperous; (transcription of Chinese) | (transcription of Chinese) |
| Word | the surname 李 Li (*lɨi) | the surname 趙 Zhao (*tʃhɨew) | the surname 劉 Liu (*lɨw) | the surname 黎 Li (*li) | the surname 夏 Xia (*xæ) |
| Translation | Li, Chhew, Lew, Li, Ha | ||||
416: 1142 (analysis unknown) and 李 both consist of vertically stacked components but otherwise have no obvious relationship.
1142 is phonetic in
1222 2lɨi (second half of 2dew-2lɨi 'proverb, saying')
1241 2lɨi 'child' (cf. the 子 'child' at the bottom of 李 'plum'); cf. 1085 below which shares the radical hax
1740 2lia (transcription)
1740 is probably a fanqie character:
=
2lia = 2lɨi + 2ʔia
417: What does a Chinese family have to do with the Tangut Gu clan or with foundations?
+
5093 1tʃhɨew 'the surname 趙 Zhao (*tʃhɨew)' (tasdan) =
5469 2giu 'the surname Gu' (taspux)
2315 2ʃɨu 'base, foundation' (diodan)
418: 5259 has a unique left side wau analyzed as the top of yuo plus the bottom of peo:
+
+
5259 1lɨew 'the surname 劉 Liu (*lɨw)' (waucox) =
5425 2ʒɨẹ (Chinese transcription) (yuocin) +
3628 1ɣwiã 'the surname 袁/元 Yuan' (dexpeo) +
but the Chinese surnames probably didn't have *ɣ-!
2107 1tsəiʳ 'land, soil' (giigircok - not cox!)
Why was the cox of 5259 derived from 2107 with cok instead of cox?
Is the analysis of 5259 wholly arbitrary and unreliable?
419: 0938 has a circular analysis. Are men associated with prosperity? I doubt 0937 predates 0938.
What is bos 'sound' doing in 0937?
+
0938 1lɨi 'prosperous' (haxwir) =
1085 1zi 'man, male' (haxtun) +
0937 1mieʳ 'flourishing, prosperous' (boshaxwir; semantic)
=
+
0937 1mieʳ 'flourishing, prosperous' (boshaxwir) =
1586 1ɣɪ̣ 'sound, voice' (bostal) +
0938 1lɨi 'prosperous' (haxwir; semantic)
420: 0683 has a circular analysis:
+
0683 1xæ 'the surname 夏 Xia (*xæ)' (pougir) =
3339 1xæ 'a kind of grass' (gempou; gem = 'grass'; phonetic) +
2627 2lɨə̣ 'land; soil' (gesgir; ges = 'earth'; 10.6.0:02: signifying that 0683 was originally meant for a place name?)
+
3339 1xæ 'a kind of grass' (gempou) =
3255 1kii 'grass' (gembee; semantic) +
0683 1xæ 'the surname 夏 Xia (*xæ)' (pougir; phonetic)
pou is a phonetic for 1xæ and its shape may be based on Chinese 夏 *xæ. It only appears in three tangraphs: 0683 and 3339 (both above) and 1081:
=
1081 1xæ 'blocked (throat)' (bospou) =
1586 1ɣɪ̣ 'sound, voice' (bostal) +
0683 1xæ 'the surname 夏 Xia (*xæ)' (pougir; phonetic)
bos 'sound' in 1081 may represent the sounds that can't come out of a blocked throat.
10.10.4.21:18: TANGRAPHIC RADICALS 21: THIS, THAT, THOU
There are only three tangraphs with the radical gam. The second and third were in my last post:
All three words are pronouns but don't have anything else in common.
2172 2tʃhɨu 'this, that' (dilgam)
2173 2thiu 'this; here (i.e., 'this place') (dexgam)
3846 2nie 'thou' (girgam)
I already discussed the analysis of 3846 last time. 2172 and 2173 have circular analyses:
=
+
2172 2tʃhɨu 'this, that' (dilgam) =
2569 1tʃɨə̣ 'to encircle, go round' (gaidil) +
2173 2thiu 'here, this' (dexgam)
=
+
2173 2thiu 'here, this' (dexgam) =
3926 2nia 'thou' (girdexcin) +
2172 2tʃhɨu 'this, that' (dilgam)
2569, the mirror image of 2172, seems like an unusual choice for a source tangraph of 2172 unless one knows that 2172 is the first syllable of the words
2172-2672 2tʃhɨu-2khɨaa 'to surround'
2172-2172 2tʃhɨu-2tʃhɨu 'to surround'
Removing a dot from the spelling of the first disyllabic word for 'surround' and changing the right radical of 2172 slightly results in
2283-2672 1ɣəuʳ-2khɨaa 'to surround'
Note that 2283 does not have the same right side as 2172.
gai is only rarely on the right. gak
1890 bie 'high'
with a 'tail' is much more common.
As one would expect, 2672 is derived from 2569:
=
+
2672 2khɨaa 'to surround' (dexgaidil) =
2757 2roʳ 'to circle, move around' (dexzorcin) +
2569 1tʃɨə̣ 'to encircle, go round' (gaidil)
Why don't 2672 and 2569 have gam instead of gai? Why don't all three 'surrounding' tangraphs share a radical? Is gai meant to remind the reader of gam while keeping 2672 and 2569 distinct from the three pronominal tangraphs with gam?
10.10.3.21:49: YOU HELP ME
make sense of the analysis of 3926 'thou' from my last entry:
+
+
Tangut has subject-object-verb word order, so 'thou I help' is 'you help me'.3926 2nia 'thou' (girdexcin) =
3846 2nie 'thou' (girgam) +
2098 2ŋa 'I' (dexduufer) +
0757 2bạ 'to help' (haxweecin)
One might expect other pronoun tangraphs to have similar analyses, but none of the other pronoun tangraphs have ヒ cin on the left. Is 0757 the real source of cin, or was it arbitrarily chosen from 548 cin-tangraphs to create a phrase 'you help me'? There is no tangraph girdex, so -cin wasn't necessary to differentiate girdexcin 'thou' from an already existing girdex.
3846 has a circular analysis:
3846 2nie 'thou' (girgam) =
3926 2nia 'thou' (girdexcin) +
2173 2thiu 'here' (dexgam)
It's highly unlikely that 3846 and 0757 predate 3926. 3926 is the basic second person pronoun, whereas it's not even certain that 3846 really does mean 'thou'. Kychanov (2006: 739) has no pronominal glosses for 3846 and Li Fanwen (2008: 620-621) only gives three examples of 3846 as 'thou'. One of the three is the 'you here' analysis above. The other two are
2ni 'thou' (honorific) : 2nie (Homophones 13B54)
2nie: 1miə 1ʔie 1ʔiə (Homophones D 14B35 note)
'thou': 'other GEN say'
'2nie is what the other [an addressee?] is called.'
Cf. Homophones 16B75:
1miə 'other' (an addressee?): 2nia 'thou'
and a note in Homophones D 17B46:
2nia 'thou': 1miə 'other' (an addressee?) 1tsie 'he; it; other' (an addressee?)
2ni could be a direct loan from Chinese 你 *ni 'thou'. The other two words for 'thou' (2nia, 2nie) could be native Tangut cognates of Old Chinese 汝 *naʔ 'thou'.
2nie is also an optative verb prefix (Gong 2003: 608) derived from the downward motion verb prefix
1452 1nia 'downward': e.g., 1nia-1liẹ (rain) 'came down'
which has a completely different tangraph.
Are the parallel vowel alternations coincidental?1nia 'downward' : 2nie (optative prefix; the tone change is unexpected)
2nia 'thou' : 2nie 'thou'
The analysis of 2098 2ŋa 'I' is unknown. 2098 is in the Homophones B entry for 2nia 'thou' (17B46):
0757 (analysis unknown) seems to consist of 1637 plus a cin from some tangraph like 2705:2nia 'thou': 2ŋa 'I'
=
+
?
0757 2bạ 'to help' (haxweecin) =
1637 2ba (transcription tangraph; first half of surname 2ba-2bəi) (haxyax) +
2705 2biẹ 'to help, aid' (carjiucin)
Although yax and wee are slightly different (though not in the Mojikyo font you see here), I doubt the difference is significant.
0757 and 2705 may be cognates. The -ạ and -iẹ alternation between 0757 and 2705 is parallel to the -ia and -ie alternations in 'thou' and the verbal prefixes.