 =
= +
+
is the literal translation of the components for Tangut character 1310:
1310 1lɨəə '?' =
'dog' = left of 0573 1na 'dog' +
all of 3094 1khie 'gray'
What does 1310 mean? Select the following blank space for the answer: wolf.
1lɨəə looks like Mawo, Taoping, and Ronghong Qiang lɑ 'id.', but those Qiang forms are borrowed from Mandarin lang (Huang and LaPolla 1996: 334).
Md lang comes from Old Chinese *raŋ with *r- which later changed to *l-. Hence it cannot be cognate to Tangut 1lɨəə.
I doubt that 1lɨəə was an early loan from a Chinese *laŋ postdating the *r- to *l- shift because the vowels are too different. I know of no other cases of Tangut rhyme 33 -ɨəə corresponding to Chn *-aŋ which normally corresponds to Tangut rhyme 51 -o or rhyme 56 -õ.
10.9.8.23:59: TANGRAPHIC RADICALS 18: THE PUOFIK-TION OF BUDDHA
Homophones (13A24) has a disyllabic word for 'Buddha'
0418-2852 1xwɨə 1tha
which is based on pre-Tangut northwestern Chinese 佛陀 *f- tha < Middle Chinese *but da, a transcription of Sanskrit Buddha.
Each half of this word can also mean 'Buddha' by itself.
I have already examined the second half which appeared in line 79 of the Golden Guide.
Although the second half is a graphic calque of 佛 (the first half of the Chinese word), the first half
=
+
0418 1xwɨə 'Buddha' (puofik) =
1798 2xwɨə 'treasure' (puopik; phonetic; why does 'treasure' have pik = 'hand'?)
0542 2lɨuu 'beautiful' (fikdex; semantic)
has no resemblance to either 佛 or 陀. (But see below.)
The initial of 0418 is uncertain. 0418 is listed in the labiodental section of Homophones, but its fanqie in Tangraphic Sea indicate a velar initial:
+
1xwɨə = 1xəu + 1ʃwɨə
Perhaps both dictionaries are correct because they reflect two different dialects of Tangut:
Homophones dialect: 1vɨə with labiodental initial
Tangraphic Sea dialect: 1xwɨə with velar initial
xw- is not far from hw-, the voiceless counterpart of w- which would be close to v-. Did the TS dialect have w- instead of v-?
One might expect all TS xw- to correspond to Homophones v-, but in most cases, the two dictionaries agree. I recconstruct a three-way distinction in pre-Tangut to account for the three patterns of correspondence between TS and Homophones:
| Voiceless | Voiced | ||
| Pre-Tangut | *xw- | *hw- [ʍ] | *w- |
| Homophones | xw- | v- (f-?) | v- |
| Tangraphic Sea | xw- (hw-?) | w- | |
A pre-Homophones dialect may have merged *hw- and *w- into *w-, just as many English dialects have merged wh- and w-.
The pre-Tangut initial *hw- of 0418 'Buddha' would be an attempt to imitate the *f- of Chn 佛. I assume the initial of 佛 had devoiced since Tangut 1tha for 陀 has a voiceless initial th- instead of a d- reflecting Middle Chinese *d-.
(9.9.0:18: Perhaps *hw- became f- in the Homophones dialect: cf. the wh- > f- shift in Scots.)
The rhyme -wɨə of 0418 'Buddha' may indicate that Middle Chinese *-ut had become something like *-wɨə after labials. Gong (2002: 375) reconstructed the Tangut period northwestern Chinese rhyme category of 佛 as -(w)ə, -jwi, -ju. I do not know whether the three reconstructions were in free variation or conditioned by preceding initials.
So far I have mentioned two tangraphs with the radical puo. There is only one other puo tangraph. Its analysis links to the other two:
=
0719 1xwɨə 'to eliminate, clear away' (puogoi) =
1798 2xwɨə 'treasure' (puopik; phonetic) +
5372 1phəʳ 'to eliminate, clear away' (pikgoi; semantic)
1798 2xwɨə 'treasure' (puopik) =
0418 1xwɨə 'Buddha' (puofik; phonetic; derived from 1798; see above) +
5655 1lɨə̣ 'treasure' (pikbaegii; semantic)
9.9.00:41: Could puo be derived from 佛 with 亻 reduced to フ on top and 弗 turned into ㄇ with three horizontal lines? The right side of 0418 could be derived from 它, the right side of (佛)陀.
Last night, I mentioned two tangraphs for 'Tibetan' which can also form a redundant disyllabic compound:
5233-1309 1phə 1tʃɨe 'Tibetan' (pikqer qeoweo)
They both share the radical qer ~ qeo which changes slightly depending on position.
qeo is unique to 1309.
qer occurs in only one other tangraph, the second half of

5647-5235 1pị 2ʔiẽ 'Tibetan' (pikweo paibaeqer)
Is this a disyllabic Odic Tangut word? Li Fanwen lists no attestations outside dictionaries. Like 1309 1tʃɨe, 5647-5235 1pị 2ʔiẽ does not resemble Tibetan Bod 'Tibetan' or Qiang RRmea 'Qiang' or even the Chinese terms for those ethnicities.
Since all tangraphs with qer ~ qeo are glossed as 'Tibetan' in English and Russian in Nevsky (1960 II: 260, 377, 526), Kychanov (2006: 372, 382-383), and in English in Grinstead (1972: 251) and Li Fanwen (2008: 219, 826-827), I will gloss that radical as 'Tibetan'.
All but Grinstead also gloss qer ~ qeo tangraphs as 羌 'Qiang' in Chinese but not in other languages. Is 'Qiang' based on the use of one or more of the qer ~ qeo tangraphs as translations of 羌 in Chinese texts? Li Fanwen lists no examples of such translations. Could the shape of qer ~qeo be loosely inspired by 羌? I don't see much of a resemblance.
9.8.1:11: Another translation of 5647 and 5235 is 戎 'Rong' (western barbarian) in Kychanov (2006: 383) and Li Fanwen (2008: 826-827, 889). What is the textual support for this? The only Tangut translation of 戎in Chinese texts that I know of is
1ʒɨõ 'fine hair' (Sunzi 555, Leilin 109)
a borrowing from Chinese 絨, a homophone of 戎. I doubt there was a native Tangut word for 'western barbarian'.
5647 consists of the non-qer ~ qeo parts of 5647-5235:
=
+
5233 and 5647 have pik 'hand' on the left but 5235 has 5298 1noo 'finger' (paibae) instead:
Why were these body part radicals added to qer 'Tibetan'?
10.9.6.23:36: THE GOLDEN GUIDE: LINE 79: TANGRAPHS 391-395
It's been two weeks since I last translated the Golden Guide.79. The Tangut Empire was Buddhist, so I'm surprised that it took 79 lines for Buddha to appear.
| Tangraph number | 391 | 392 | 393 | 394 | 395 |
| Tangraph | |
 |
 |
 |
 |
| Li Fanwen number | 5233 | 0747 | 2852 | 1489 | 3419 |
| My reconstructed pronunciation | 1phə | 2miaa | 1tha | 1səĩ | 1biuu |
| Tangraph gloss | Tibetan | many, much | Buddha | monk | to respect |
| Word | |||||
| Translation | Many Tibetans respect Buddhist monks; | ||||
391: Li Fanwen (2008: ) glossed 5233 as both 'Tibetan' and Qiang, but I interpret it as Tibetan since the Qiang are not traditionally Buddhist. 1phə vaguely resembles Written Tibetan Bod 'Tibet'. Perhaps 1phə was borrowed through the local Chinese dialect which had shifted *b- to *ph-:
Tib Bod > Chn *ph-? > Tangut 1phə
5233 has a circular analysis:
+
5233 1phə 'Tibetan' (pikqer) =
5212 1pị 'discuss' (pikbui; 'hand' + 'language'; arbitrarily chosen?; no semantic/phonetic relevance) +
1309 1tʃɨe 'Tibetan' (qeoweo; semantic; qeo is a left-hand variant of qer)
=
1309 1tʃɨe 'Tibetan; skillful' (qeoweo) =
5233 1phə 'Tibetan' (pikqer; semantic) +
3297 1tʃɨe 'a kind of bird' (giiweo; phonetic)
I have no idea why the Tibetans or Qiang would be called 1tʃɨe.
392: 0747 (analysis unknown) must be graphically related to
0743 2ʃɨu 'many' (< 'numerous'?; is the resemblance to Tangut period Chinese 數 *ʃɨu 'number' coincidental?)
0497 'numeral'
which share the radical 'number'.
393: 'Buddha' looks like a visual calque of Chinese 佛 'Buddha'. Both have 'person' on the left followed by a #-type element. No Tangraphic Sea analysis mentions Chinese influence. The analysis for 2853 is no excepiton:
1tha = 2dzwio 1sọ 2kɛ̣ 1thew
'Buddha' = 'person three world pierce' = 'the person who pierces three worlds'
1sọ 2kɛ̣ 'three worlds' refers to the 三界 three worlds of Buddhism.
The first and last tangraphs of this description ('person', 'pierce') contain the left and right radicals of 'Buddha'.
1tha 'Buddha' is borrowed from the second half of pre-Tangut period northwestern Chinese 佛陀 *f- tha 'Buddha', even though its tangraph resembles the sinograph for the first half.
394: Monks (1səĩ < Chn 僧 *sə̃ <*səŋ < Skt saṅgha) are very gentle:
+
1489 1səĩ 'monk' (boadexwir) =
1507 1ŋwe 'gentle, mild, kind' (boadexcun; boa, cun = 'speech'; dex = 'person') +
3119 1ʔi 'many, numerous' (dexfamdosdux; wir = famdux)
395: Respect is fearing an elder brother:
+
3419 1biuu 'to respect' (feowol) =
2539 1kiạ 'fear' (feodex; feo = 'fear') +
4613 1ka 'elder brother' < pre-Tangut period Chn 哥 *ka, 'song' < pre-Tangut period Chn 歌 *ka (bukwol; buk = 'mouth' [used in singing?])
How does one determine the meanings of tangraphs that don't have complete definitions in the surviving Tangut dictionaries?
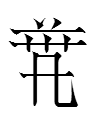
4874 2lõ 'wide'
is such a tangraph. How do we know it means 'wide'? And why did Nishida (1966: 344) define it as 'bean', of all things?
The answer to the former question are in the Tangraphic Sea dictionary and a page of the Pearl, a Tangut-Chinese glossary.
Nishida had access to neither the TS nor that page in the early to mid-60s, so the answer to the latter question lies in the texts he could consult: the Homophones dictionary and an incomplete copy of the Pearl.
In Homophones, 4874 is paired with 5970 1pɪ and vice versa (49B4, 8A1):
This may mean they were (near-)synonyms.
In the Pearl,
5829-5970 2dwɨu 1pɪ
is the equivalent of Chinese 蓽豆, which Nishida translated as 'beans'. Thus Nishida may have reasoned that 4874 meant 'bean' like 5970.
However, in the Pearl, black beans are

5829-0176 2dwəu 1nɨaa 'black beans'
and peas are

5829-1046 2dwəu 1nɨaa 'ashen beans'
2dwɨu 'bean' may be borrowed from Middle Chinese 豆 *dəwh 'bean', though the -w- corresponding to nothing in Chinese (but see below).
Could
5829-5970 2dwəu 1pɪ
also consists of 'beans' followed by an adjective (5970)?
A page of the Pearl cited in Li Fanwen (2008: 940) but absent from the versions of the text in Nishida (1964) and Kwanten (1982) confirms that 5970 could be an adjective:
4560 5970 1tʃhɨə 1pɪ
is the equivalent of 狹闊 'narrow and wide'
Moreover, the Tangraphic Sea which Nishida was unable to consult defined 5970 as 4874 and as
1918 4560 1mi 1tʃhɨə 'not narrow'
Therefore
闊 'wide' = 5970 = 4874 (as confirmed by the usage of 4874 in texts)
and
5829-5970 2dwəu 1pɪ
is literally 'broad beans'.
9.6.21:41: Or is it? Could both 2dwɨu and 1pɪ be borrowings from Chinese? Just as 2dwɨu does not quite match Middle Chinese 豆 *dəwh 'bean', 1pɪ does not quite match Middle Chinese 蓽 *pit 'bean' (among other things). I would have expected Tangut 2dəu and 1pi. Perhaps the rhymes reflect lost Tangut affixes added to Chinese loanwords:
*P(ʌ)-dəuH > 2dwəu
*r(ʌ)-pi > 1pɪ
Is it a coincidence that 1pɪ also appears in
4194-5970 1lɨu 1pɪ
corresponding to Tangut period northwestern Chinese 蓽篥 *pi li (translated by Nishida as 'cypress flute') in the Pearl (325)? Although 1lɨu vaguely resembles *li, it is more likely to be cognate to Old Chinese 笛 *liwk 'flute'. 1pɪ is probably not 'broad' here since a 蓽 篥 *pi li is narrow.
篥 is not an independent word and 蓽篥 has alternate spellings 悲栗 ~ 悲慄 ~ 悲篥 and 觱篥. This suggests that *pi li (or some ancestor of it) is a transcription of a foreign word, which would not be surprising since this instrument is of non-Chinese origin. I don't know how old this word is. If 蓽篥 existed in Middle Chinese, it would have been *pit lit, suggesting an expansion of *plit or a reduplication, but 悲栗 ~ 悲慄 ~ 悲篥 would have been *pɨi lit with only one *t. To complicate matters, 蓽篥 has the bizarre Japanese reading hichiriki < *pit lik rather than the expected hichiritsu < *pit lit. Was 篥 *lit < *lik (which looks like Old Chinese 笛 *liwk 'flute')? There is no Japanese-internal reason for *-it < *-ik, though that change did occur within Chinese: e.g., 節 *tsit < *tsik 'joint' (cf. Tibetan tshigs < *-ks, Written Burmese chac < *-ik, and Tangut 1tseʳw < *rʌ-tsik).
In any case, the Tangut term seems to be a blend of the native word 1lɨu 'flute' plus a 1pɪ possibly intended to sound like the first syllable of 蓽篥: 'the pi flute'. Could the Tangut term be a nonce creation?
5970 1pɪ appears in one more word in the Pearl (153):
2278 5970 1kiụ 1pɪ
glossed as 韭 'leek'. This word must underlie Grinstead's (1972: 122) to gloss 5970 as 'leek'. 2278 1kiụ 'onion, garlic, leek' looks like a borrowing from Tangut period Chinese 韭 *kɨw 'leek' with a tense vowel from a Tangut prefix: *S(ɯ)-kɨu? 1pɪ could be an adjective, though does 'broad' make any sense after 'leek'? (There is an Old English term bradeleac 'broad leek'!)
Adding 'wood' atop 5970 results in a tangraph for its homophone

4119 1pɪ 'cypress' < Chn 柏
5970 also transcribes Chn 伯, a homophone of 柏 'cypress'. Although both 柏 and 伯 were Grade II like 4119 and 5970, I would be surprised if they ended in -ɪ in Tangut period northwestern Chinese. Their rhyme category was transcribed in Tibetan as -(y)ag, -eg, -og in the pre-Tangut period. This category was borrowed into Korean as -ʌyk (> modern -aek). Although the dialect that was the source of Korean -ʌyk was not Tangut period northwestern Chinese, the latter dialect could have shifted the rhyme transcribed in Tibetan as -(y)ag, -eg, -og to something like *-ʌɪ which was then borrowed into Tangut as rhyme 9 -ɪ.
Perhaps Tangut rhyme 9 should be reconstructed as -ʌɪ, the lowered Grade II counterpart of the Grade I diphthong -əi. Rhyme 9 was transcribed in Tibetan as -iH (Tai 2008: 206).
I left out 4119 and 5970 from the list of tangraphs with yun in my previous entry. Here's the complete list:
























