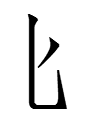=
= +
+
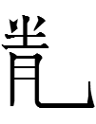
Can you guess the meaning of the first Tangut character?
dʒɛ '?' =
right side of zwiã 'to revolve; to rotate' +
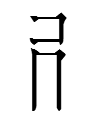
right side of rieʳ 'skillful; ingenious'
The answer is at the end of this post.
zwiã 'to revolve, to rotate' is borrowed from northwestern Chinese 旋.
The component shared by dʒɛ and 'revolve' is Nishida's (1966: 262) radical 'wheel'which cannot stand by itself. The 匕 on the right may be a 'filler'.
Hint: dʒɛ is part of a Buddhist term
dʒʌ-dʒɛ 'saṃsaara; transmigration of the soul'
when combined with dʒʌ 'to rotate; to alternate'. Do dʒʌ and dʒɛ share a common root?
Answer: Select the space between the single quotes below.
'wheel'
I wish
Vã Riʳ-dziə (roughly 'Vahn reads-ya')
a
mə-wəəi niəə bɛɛ-reʳ
lit. 'birth day happy'
in Tangut.
The first character vã
has no meaning of its own. It is used to represent foreign syllables like wan. (It has other uses that I'll mention in a future post.)
The second and third characters
represent a disyllabic word riʳ-dziə for 'tiger'. Since the normal Tangut word for 'tiger' is
ləi < *kʌ-li; cognate to Old Burmese kla 'tiger'?
I assume that riʳ-dziə is its ritual language equivalent.
Note how all three characters share the element
from Chinese 𠂰, a variant of 虎 'tiger'?
It is probably an abbreviation for
ləi 'tiger'
in
riʳ-dziə 'tiger'
'fear', from the right side of Chinese 怖 'fear'
shared by both characters of
riʳ-dziə 'tiger'
is probably short for
riʳ 'to revere; to fear'
a homophone of the first syllable of riʳ-dziə 'tiger'.
Hence
=
+

riʳ (first syllable of riʳ-dziə 'tiger') =
left of riʳ 'to revere; to fear' (phonetic/semantic) +
left or right side of ləi 'tiger'
and the second syllable of riʳ-dziə 'tiger' was written like the first syllable but with an added vertical stroke:
=
+
2nd syllable = 丨 + 1st syllable
There is a tangraphic element
alphacode: yam (on left), yal (on right)
which reminds me of Chinese 青 'blue; green'. But Nishida (1966: 245) identified it as the 盜 'steal' radical. It appears in only six tangraphs. Five mean 'to steal' and the sixth is mysterious:
| Tangraph | LFW # | Reading | Rhyme | Tone.rhyme | Gloss | Source 1 | Source 2 |
 |
1186 | ʒɔ̃ɔ̃ | R59 | 1.57 | (mantra transliteration) |  |
 |
 |
1855 | kiiʳ | R101 | 2.86 | to steal | unknown; presumably in the lost rising tone volume of Tangraphic Sea | |
|
3780 | tʃɔ̃ɔ̃ | R59 | 1.57 | to steal |  |
 |
|
5817 | kwiəəʳ | R100 | 1.92 | to steal |  |
|
|
5886 | tʃhɔ̃ɔ̃ | R59 | 1.57 | to steal | |
 |
|
5904 | kiuʳ | R81 | 2.70 | to steal | unknown; presumably in the lost rising tone volume of Tangraphic Sea | |
Not all tangraphs meaning 'steal' include it: e.g.,
Notes on the six tangraphs:
lə(-die) 'to steal'
(the second syllable is optional; die is also glossed 'to steal' but cannot occur by itself)
(5.16.2:22: Is this a disyllabic ritual language word? Li Fanwen lists no attestations outside dictionaries.)
(the right side of lə is probably from 5886; the bottom of die looks like 3728 thie 'raised')
1186: Fanqie graph from ʒ- + -ɔ̃ɔ̃. But ʒɔ̃ɔ̃ isn't an Indic syllable. Any attestations outside its Tangraphic Sea entry?
The Mojikyo graph for 1186 has an extra stroke that I have deleted from my GIF.
1855, 5817, 5904: All share a root *r-k-. The ablaut might be conditioned by presyllabic vowels. The vowel length may be compensation for a lost *-w. The original root vowel may be *u: cf. Written Tibetan rku-ba 'to steal'.
1855: kiiʳ < *r-kii-H < *r-kiw-H?
5817: kwIəəʳ < *P-r-kəə < *P-r-kəw-H?(but if *r- -iw > R100 -iiʳ, then R94 must be -ieʳw, not -iʳw)
5904: kiuʳ < *r-ku-H ('zero grade' of root *k-w?)
The root also occurs in Old Chinese without *r-: 寇 *khos < *C-ko-s 'to rob'. More on this Chinese form below.
The elements in 1855 are reversed in 5817:
3780 and 5886 share a root *tʃooN:
3780: tʃɔ̃ɔ̃ < *tʃooN5886: tʃhɔ̃ɔ̃ < *K-tʃooN
These two words sound like the modern Sino-Korean reading 청 chhŏng [tɕhɔŋ] of 青 'blue, green' which resembles their shared radical, but this is coincidental. The earlier SK reading was 쳥 tshjəŋ. The Tangut period northwestern Chinese reading of 青 was probably closer to *tshiẽ than tʃ(h)ɔ̃ɔ̃.
The left side of 3780 ('person') is from 3627 ni, half of a reduplicated expression
ni-ni 'whispered; quiet; secret'
(rising tone syllables; no Tangraphic Sea analysis available)
If the radical for 'steal'
alphacode: yam/yal
has nothing to do with its Chinese lookalike 青 'blue, green', where does it come from? About two weeks ago, I realized that 5886
alphacode: yamdil
vaguely resembled the aforementioned sinograph
寇
'to rob'
if its roof 宀 were directly atop 元. Tonight, I found a variant of 寇 with the root over the second element but not the third resembling 完 'complete' + 攵, a variant of 攴 'to strike'. 寇 represents the 攴 striking of a head 元 (now 'primary') under a 宀 roof. Could the radical be derived from 5886, instead of the other way around? If so, then the Tangraphic Sea analysis of 5886
yamdil = yambue + yamdilcin
5886 = 5817 + 5904
and 5904 was derived from 5886 via the addition of the high-frequency element
alphacode: cin
which could be the abbreviation of one of 547 other tangraphs - roughly one-eleventh of all tangraphy. Is there a cin-tangraph with a relevant meaning? Could cin, like yam/yal be an abbreviation of a sinograph? How many other tangraphic elements are abbreviated sinographs?
5.15.21:43: I forgot about 'fear' from the right side of Chinese 怖 'fear'.
5.15.21:07: Could
lə R28 2.25 < *Cʌ-lə < *Cʌ-ləw 'to steal'
be cognate to Old Chinese
偷 *hlo < ?*C-ləw 'to steal'
and possibly
盜 *laws 'to steal' (also reconstructible as *daws)
sharing a common root *l-w?
I could even try to derive 寇 'to rob' from *khlos < *C-k-ləw-s, but I'd rather link it to Written Tibetan rku-ba and the various Tangut k-words for 'to steal'.
Tangut l- can be from medial *-t- or *-d- as well as *-l-. Perhaps
lə-die 'to steal'
was originally a partial reduplication:
*Cʌ-də-de-H > *Cʌ-də-die-H > *Cʌ-lə-die-H > lə-die
with the nonlow vowel of the reduplication conditioning the bending of *e to ie.
But why didn't the second *d also lenite? Was there a constraint against lenition within reduplications?I doubt that die is cognate to Old Chinese 盜 *daws 'to steal' since a pre-Tangut *-ew would become *-iew after a nonhigh-vowel presyllable, not -ie.
10.5.14.4:00: KO-NI, MƏ-WƏƏI NIƏƏ BƐƐ-RER!
I wish
Ko-ni
lit. '(light) pearl'
a
mə-wəəi niəə bɛɛ-reʳ
lit. 'birth day happy'
in Tangut.
ko 'a Tangut surname' consists of the left and center of its homophone ko 'put the palms together' plus the right side of 'surname':
=
+
ko 'a Tangut surname' was also used to write the similar-sounding Tangut period northwestern Chinese word 光 ko 'light' (noun).
ni 'pearl' consists of the left side of niaa 'colored glaze' plus the left of kwɛ 'true; precious':
=
+
(Written on 10.5.7 and revised on 5.12 and 5.13. "Today" and "now" refer to 5.7.)
I didn't know there were capital versions of ɣ and ʊ until now. You can see them in the title of the Kabiyé version of the Universal Declaration of Human Rights. The other unusual capitals in Kabiyé are Ɩ Ɔ Ɛ Ŋ Ʃ. According to PanAfriL10n, the lower-case version of Ʃ is ʃ (not σ!), but I can't find either in the Kabiyé UDHR. At least I now know what letter to use if I want to have Tangut ʃ in a blog post title.
Today I found the word
thiə-ɣʊ 'emperor'

alphacode: dexgiifak geoduucin
which might be a Tangut ritual language word since Li Fanwen (2008) only lists attestations in dictionaries.
Titles like 'emperor' interest me because they are likely to be loanwords: cf. the spread of qaɣan 'emperor' to other languages*.
ɣʊ R4 2.4 might be from a suffixed variant *Cʌ-qu-H of ɣʊ R4 1.4 < *Cʌ-qu 'head'. But what is thiə R31 2.28? Does it have any (near-)homophones that would plausibly combine with 'head' to form 'emperor'?
| LFW | Reconstruction | Rhyme | Tone.rhyme | Gloss |
| 0792 | thiə | 31 | 1.30 | to enclose |
| 0826 | to call; to say | |||
| 0827 | second half of mia-thiə 'east; end' | |||
| 1400 | first half of thiə-riaʳ 'restrained; reserved' | |||
| 5548 | first half of the place name thiə-khiəəʳ | |||
| 5671 | to abandon; to distinguish; to expel | |||
| 0986 | 2.28 | first half of thiə-na 'buttocks' | ||
| 3115 | first half of the surname thiə-ɣʊ (homophonous with 'emperor'!) | |||
| 5354 | this | |||
| 5355 | first half of thiə-la 'scorpion' (but LFW2106 la can also be 'scorpion' without thiə in the compound 'heaven-scorpion', the name of a constellation |
The only thiə that might have something to do with 'emperor' is LFW3115, the first half of the surname
thiə-ɣʊ
alphacode: gerfak belduucin
which shares the element fak with the first half of 'emperor'.
The second tangraph shares the elements
duu and cin
with geoduucin, the second half of 'emperor'. I suspect duucin in geoduucin is an abbreviated phonetic combined with
geo
'sage'. There is no independent tangraph duucin. The presence of duucin does not guarantee a reading like ɣʊ; only one other duucin tangraph is pronounced ɣʊ, the second half of
diə-ɣʊ 'a kind of tree'
(homophonous with thiə-ɣʊ 'emperor'/'a surname' except for the initial)
alphacode: boxbeldilcin boxbelduucin
Is the name thiə-ɣʊ taken from the word for 'emperor' or vice versa? (Cf. the surname Kaiser from the title Kaiser which is turn is from the cognomen Caesar.) And is the name for the tree somehow related to the surname and (ritual language?) word for 'emperor'? See Gong's "Phonological Alternations in Tangut" for other examples of d- ~ th- alternation. I tentatively reconstruct *K- as a source of aspiration in pre-Tangut: *K-d- > th-. (I can't reconstruct *S- as a source of aspiration since I reconstruct it as a source of tense vowels: *S-CV > CṾ.)
*5.14.2:18: Pulleyblank (1962: 261) proposed that a Xiongnu term transcribed in Late Old Chinese as 護于 is the source of qaɣan. He reconstructed 護于 as *ɦwax-ɦwaaɦ representing Xiongnu *ɣʷaɣʷaa or *ɢaɢaa. I reconstruct 護于 as *ɣwɑh-wɨa which is even less like qaɣan. But a Baxter-Sagart-type reconstruction *ɢʷˁah-ɢʷa is still close to the forms that Pulleyblank proposed for Xiongnu.
There's a xiongnu.net devoted to the Xiongnu, but tangut.net is just a placeholder and tangut.com, though taken, goes nowhere.
10.5.12.22:55: WHY SHOULD TANGUT BE RECONSTRUCTED WITHOUT FINAL NASALS OR STOPS? PART 2: LOANWORDS
Several scholars have proposed that some of the 105 rhymes of the Tangraphic Sea had final consonants. Let's compare reconstructions of the first seven rhymes (the u-type group). Rhymes with codas are in bold.
| Rhyme number | Reconstructions with final consonants | Reconstructions without final consonants | Undated Tibetan transcriptions | ||||||
| Nishida 1964 | Sofronov 1968 | Arakawa 1999 | Hashimoto 1965 | Huang 1983 | Li 1986 | Gong 1997 | This site | ||
| R1 | -u | -u | -u | -uu | -(i)u | -u/-ü | -u | -əu | -u(H), -wu, -wo, -i(H) (sic) |
| R2 | -ǐu | -i̭u | -yu | -u | -(i)ɯ | -ǐu | -ju | -ɨu | -u(H), -yu, -ywe (sic) |
| R3 | -ǐuɦ | -ʏ | -ju | -io/-iɔ | -ǐuu | -iu | -(y)u(H), -o(H), -uo | ||
| R4 | -uɦ | -uC | -u: | -juu | -uu | -ǔo | -u | -ʊ | -u(H) |
| R5 | -ʊ | -un | -u' | -ɔ | -(u)o | -ʊ | -uu | -əuu | -u(H), -wu, -uu |
| R6 | -ʊɦ | -ûn | -yu' | -o | -ïo | -ɪʊ | -juu | -ʊʊ | none |
| R7 | -ǐʊɦ | -i̭ûn | -u:' | -jo | -ɔ/-iɐ | -ɪʊʊ | -ɨuu/-iuu | -u(H), -yu, -wa (sic) | |
The Tangraphic Sea contains many loanwords from northwestern Chinese (NWC). These borrowings must predate the writing of TS in the 11th century. Transcriptions indicate that NWC had codas up to the 10th century. Those codas were then lost by the 12th century. There may have been an intermediate stage around the 11th century in which the stops had merged into glottal stop or had become fricatives:
NWC final stops: merger scenario
| 10th century | 11th century? | 12th century |
| *-p | *-ʔ | zero |
| *-k |
NWC final stops: fricative scenario A
| 10th century | 11th century? | 12th century | |
| *-p | *-ɸ | *-h | zero |
| *-k | *-x | ||
NWC final stops: fricative scenario B
| 10th century | 11th century? | 12th century | |
| *-p | *-β | *-ɦ | zero |
| *-k | *-ɣ | ||
NWC *-t had shifted to *-r by the 8th century.
If Tangut had final consonants, I would expect NWC rhymes ending in consonants to be borrowed as Tangut rhymes with final consonants: e.g.,
NWC *-uk or *-ux or *-uɣ > Nishida's R4 -uɦ, Sofronov's R4 -uC, Arakawa's R5 -u'
NWC *-un or *-uŋ > Sofronov's R5 -un
Conversely, I would not expect NWC rhymes ending in vowels to be borrowed as Tangut rhymes ending in -ɦ, -C, -n, -', etc. However, Gong's paper "西夏語中的漢語借詞" identified
3 open syllable NWC loanwords and 0 closed syllable NWC loanwords in R3
2 open syllable NWC loanwords and 1 closed syllable NWC loanword in R4:
谷 *-k > TT4060 kʊ
2 open syllable NWC loanwords and 2 closed syllable NWC loanwords in R5
通 *-ŋ > TT2817 thəuu
同 *-ŋ > TT2834 thəuu
Apparently all R6 syllables are native.1 open syllable NWC loanwords and 0 closed syllable NWC loanwords in R7
Are Gong's findings necessarily proof against reconstructing R3-R5 and R7 with codas? Not necessarily. Gong's identifications could be incorrect and the phonetic/semantic matches could simply be coincidental. And even if the identifications are correct, the Tangut codas could be consonantal suffixes added to the loanwords. But I prefer to assume that NWC open syllables were borrowed as Tangut open syllables.
The three NWC closed syllables (谷通同) could have been borrowed after they had lost their codas*. Or the Tangut borrowed them as open syllables without their un-Tangut codas. A third possibility is that one or more of the borrowings occurred when Tangut still had codas, but those codas were lost by the 11th century:
| Pre-11th century rhymes | 11th century Tangraphic Sea rhymes |
| *-ʊ | R4 -ʊ |
| *-ʊk | |
| *-əuu | R5 -əuu |
| *-əuŋ |
After putting this post aside for a day, I looked at Gong's data again and noticed that NWC syllables with prenasalized initials were borrowed with R5 and R7 rather than R1-4. All borrowings with R5 either have prenasalized initials or rhymes that (once?) ended in nasals. There is only one borrowing with R7 and it had a prenasalized initial.
The following scenario occurred to me this evening:
*NV > *NṼ > *NCṼ b> R5 and R7 with nasal codas
i.e., 奴 *nd-, 慕 *mb- (b> R5) 女 *ndʒ- (b> R7)
*CVŋ b> R5 with a nasal coda
i.e., 通 and 同, both *th-ŋ
(b> = borrowed into Tangut)
So could Sofronov's reconstruction of a final nasal for R5-7 be correct? (Although there is no loanword data for R6, I assume it had the same coda as the rhymes surrounding it.) I still don't think so. If NWC syllables like 奴慕女 had nasal vowels as well as prenasalized initials, I would expect their Tibetan transcriptions to have final nasals, but I couldn't quickly find any. And I have not yet run out of arguments against final consonants.
Next: Part 3: Cognates.
*The aspirated initial of thəuu < 同 indicates a late loan.
10.5.11.23:39: EXAMINING CAREFUL ZEN CICADAS
I've been puzzled by the Cantonese readings of 禪 Sim 'Zen' and 蟬 sim 'cicada' since the late 90s. They end in -m even though all other evidence points to an earlier *-n. 禪 is from Pali jhaana 'meditation' which has no -m. Both graphs share the -n phonetic 單.
Hakka also has -m in those words:
| Sinograph | Gloss | Meixian | Taiwanese Hakka | ||||
| Sixian | Hailu | Dapu | Raoping | Zhaoan | |||
| 禪 | Zen | ? | sam | sham | shiam | ||
| 蟬 | cicada | hiam (with h-!) | ? | ||||
Today I found some other Hakka -m for *-n words in Ungsitipoonporn's (2008) "The Bangkok Hakka Phonology":
慎 sɨm 'careful': cf. Meixian Hakka sǝm and Chaozhou sim but Cantonese san
with an -n phonetic 眞 tsɨn 'truth, real'!
審查 sɨmtsha 'to examine, check up': cf. Meixian Hakka sǝm and Chaozhou sim but Cantonese san for the first syllable
Chaozhou is Min, not Hakka. So -m for *-n is in at least three branches of Chinese: Yue (Cantonese), Hakka, and Min. I have no idea why. Taboo deformation in early south China?
Does any language have -p < *-t in absolute final position? (Cases involving assimilation like Sino-Japanese 八方 happou < hat-pou don't count.)
Yinchuan (from my last post) has a couple of cases of syllable-initial m- from *n-:鮎 miæ̃ (Middle Chinese *nem) in 鮎魚 'catfish'
泥 mi (Middle Chinese *nej) in 稀泥 'mud'
I would expect *m- to become n- before i, but not the other way around.
(23:45: Could these be retentions of earlier root-initial *m- or a prefix *m-?)
Two more shifts in Bangkok Hakka that I'd like to note before I forget:
*ɲ- > ŋ- initially in 人 ŋin 'person' (cf. Meixian ɲin)
but *ɲ- > -n finally: e.g., *diɲ > 定 thin 'reserve' (cf. Sino-Vietnamese định [ɗiɲ])
*ɲ- > ŋ- seems vaguely familiar, but it's not in any of the major Chinese languages. Where have I seen it before?
*-p > -k in 法 faak 'law' (cf. Meixian fap and Chaozhou huap)Middle Chinese labial coda dissimilation is common in Chinese, but usually MC *PVP becomes PVT (e.g., 法 Cantonese faat), not PVK.Are there cases of *-m > *-ŋ in Bangkok Hakka after labial initials corresponding to *-m > -n after f- in Cantonese: e.g., 犯 *fam > Ct faan 'crime' (but Meixian fam and Chaozhou huam)?
I was disappointed to see that there was nothing Bangkok or even Thai about Bangkok Hakka. Surely there must be Thai loanwords in BH, but I didn't see any in the article. Almost every single word had a Chinese character (i.e,. had a Chinese etymology). I wonder what Thai sounds like with a Bangkok Hakka accent.
I finally got around to trying the historical phonology tool at eastling.org. I wish there were something like it for Tangut.
Phonological data for 281 varieties of Chinese are available. I picked 銀 川官话 Yinchuan Mandarin. Yinchuan 'Silver River' is the modern name for 興慶 Xingqing, the former capital of the Tangut. (It still has a 兴庆区 Xingqing District and even has a 西夏区 Xixia [Tangut] District.) The YM data is apparently from a book called, of all things, 厦门音档 Amoy Sound Files even though Amoy is on the coast and Yinchuan is inland. (I suspect Amoy Sound Files was accidentally copied and pasted in place of the actual data source. The only other variety listed with ASF as a source is Amoy itself.)
Although Yinchuan Mandarin is probably not the descendant of the Chinese dialect once spoken in Xingqing, the former may retain some of the features of the latter. Clicking on 銀川官话 leads me to an interface which allows me to view modern syllables according to Middle Chinese phonological categories: initial, rhyme, tone, grade, etc.
Choosing MC nasals led me to discover that they sometimes corresponded to aspirated stops in Yinchuan:
| MC nasal | MC reconstruction | Tangut period reconstruction | Yinchuan nasal | Frequency | Yinchuan nonnasal | Frequency |
| 明 | *m- | *m(b)- | m- | 163 | ph- | 17 |
| 泥 | *n- | *n(d)- | n- | 43 | th- | 5 |
| 娘 | *ɳ- | *ɲ(dʒ)- | 24 | 3 | ||
| 疑 | *ŋ- | *ŋ(g)- | 9 | zero | 86 | |
| v- | 23 | |||||
| m- | 1 | k- | 2 | |||
| kh- | 1 |
The table above is not an exhaustive list of correspondences: e.g., MC *ŋ- corresponds once to tɕ- in 研 tɕiæ̃ (implying MC *k-; cf. the Sino-Japanese reading ken).
I omitted 日 MC *ɲ- which never corresponds to nasals in Yinchuan. In the Tangut period, it had become *ʒ- which corresponds to Yinchuan ʐ-.
Here's what may have happened. Steps 1 and 2 are certain, but steps 3 through 6 are speculative.
1. Nasals often partly denasalized in northwestern dialects of Late Middle Chinese: e.g.,
*m- > *mb-
2. *ɲdʑ- simplified to *ʒ-, and retroflex *ɳ(ɖ)- shifted to alveopalatal *ɲ(dʒ)-.
3. Voiced obstruents devoiced and aspirated:
*b- > *pɦ- > *ph-
4. Prenasalized obstruents lost prenasalization:
*mb- > *b-
Tangut transcriptions of Tangut period NW Chinese and vice versa indicate steps 1 through 3 and perhaps 4.
4. *ɲ- and *dʒ- became *n- and *d-.
5. The new voiced obstruents from nasals devoiced and aspirated like the old voiced obstruents in step 3:
*b- > *pɦ- > *ph-
*d- > *tɦ- > *th-6. An eastern dialect replaced the original dialect of Yinchuan, but some native Yinchuan words which had undergone step 5 survived: e.g., khu in addition to imported vu for the name 吳.
Summary of nasal changes (added 5.10.23:25)
| Middle Chinese | Step 1 | Step 2 | Step 3 | Step 4 | Step 5 |
| *m- | *mb- | *b- | *ph- | ||
| *n- | *nd- | *d- | *d- | *th- | |
| *ɳ- | *ɳɖ- | *ɲdʒ- | *dʒ- | ||
| *ɲ- | *ɲdʑ- | *ʒ- | |||
| *ŋ- | *ŋg- | *g- | *kh- | ||
This hypothesis predicts that syllables with voiceless aspirates from nasals might have other archaic features.
The ratio of nasals to nonnasals in Yinchuan is roughly 9 to 1:
MC *m- : YC m- 163 : ph- 17
MC *n- : YC n- 43 : th- 5
MC *ɳ- : YC n- 24 : th- 3
Total: 230 nasals : 25 aspirated stops
Perhaps at least one out of nine *nasal syllables is an archaism. ("At least" because not all initial nasals denasalized in Tangut period northwestern Chinese.)
It would have been neat if 銀川 Yinchuan (< Middle Chinese *ŋɨin + *tɕhwien) had an initial voiceless aspirate kh- in Yinchuan Mandarin, but 銀川 is pronounced iŋ tʂhuæ̃ with a zero initial.
5.11.0:03: I briefly considered the possibility that the eastern dialect arrived before step 5. Perhaps that dialect had its own voiced obstruents (corresponding to indigenous voiceless aspirates) and both imported and indigenous voiced obstruents were devoiced and aspirated simultaneously in step 5:
| Middle Chinese | Arrival | Post-arrival devoicing and aspiration |
| *b- | Yinchuan *ph- | *ph- |
| Eastern *b- | ||
| *m- | Yinchuan *b- | |
| Yinchuan, Eastern *m- | *m- |
The problem with this scenario is that voiceless aspirates from nasals occur in three out of four categories, whereas Mandarin devoicing and aspiration usually occurs only in level tone syllables. Voiced obstruents normally simply devoice in Mandarin non-level tone syllables.
| Tone category | Example sinograph | Early Yinchuan | Expected modern Yinchuan with tonally conditoned aspiration | Actual modern Yinchuan without tonally conditioned aspiration |
| Level | 梅 | *bei | *phei | phei |
| Rising | 美 | *pei | ||
| Departing | 妹 |
I can't find any examples of voiceless aspirates from nasals in former entering tone syllables. (Yinchuan no longer has an entering tone.)
All instances of ph- < *m- are before the rhyme -ei. Similarly, all instances of th- < *n- are before the rhyme -iæ̃. Nothing about those rhymes would make preceding initials devoice and aspirate. There is no mei or nei, but miæ̃ does exist.
10.5.10.21:18: DO YOU KNOW THE WAY OF THE CHICKEN?
(5.11.19:05: I didn't know. Thanks to Andrew West for helping me to improve this post.)
This site has 'humorous' transcriptions of standard Mandarin as pronounced in Nanning: e.g., standard
不知道
bu zhidao
'not know'
supposedly sounds like
不鸡道
bu ji dao
'not chicken road'
in Nanning.
The 'chicken' transcription implies that standard zh (a sound absent from the Cantonese dialect native to Nanjing) is pronounced as j in Nanning, but the Nanning pronunciation of 张 zhang (a classifier used to count flat objects) was transcribed as both 山 shan 'mountain' and 三 san 'three' instead of, say, 江 jiang 'river'.
(5.11.19:05: Looking at the Nanning Cantonese data at eastling.org, I bet the actual initial of standard 知 and 张 in Nanning pronunciation is [ts], not j [tɕ], sh [ʂ], or s.)
(5.10.21:35: 普通话 Putonghua 'standard Mandarin' supposedly sounds like
不懂哇
bu dong wa'not understand (exclamation)'
with a Nanning accent.)
The inconsistency of the transcriptions and the transcriber's sense of humor* make this 'data' extremely dubious. But I am always fascinated by attempts to write one language in the script of another. Understanding modern transcriptions - especially when their targets are known - can help me understand ancient transcriptions of unknown languages (e.g., Tangut).
*5.11.18:55: The transcriber may have deliberately chosen amusing characters for the transcription without regard for phonetic accuracy. Cf. the Chinese practice of derography - writing foreign words with derogatory characters: e.g., pre-Old Japanese *kimi (or *kemi?) 'lord' was transcribed with Middle Chinese 雞 *kej 'chicken' in Sui shu. 'Lord' is kimi in Old Japanese but could have been either *kimi or *kemi in pre-OJ. It is uncertain whether the transcrber heard a *ke and transcribed it fairly accurately or if he heard a *ki and wrote it with 雞 *kej which was phonetically imprecise.
10.5.9.23:45: WHY SHOULD TANGUT BE RECONSTRUCTED WITHOUT FINAL NASALS OR STOPS? PART 1: TRANSCRIPTIONS
My reconstruction of Tangut has 105 rhymes which all end in vowels or the glide -w. In my last post, I reconstructed twelve types of short i and eleven types of short a. Why not reconstruct
-iŋ, -iŋs, -ik, -iks, -in, -ins, -it, -its, -im, -ims, -ip, -ips
which are all found in Old Chinese instead of
-ei, -ı, -ɨi, -i, -eị, -ı̣, -ɨị, -ị, -eiʳ, -ıʳ, -ɨiʳ, -iʳ
The short answer is that the transcription data almost entirely point toward open syllables.
Most Tibetan transcriptions of Tangut syllables end in vowels with three major exceptions:
ང -ng and ར -r in the Tibetan transcription data probably represent nasalization and retroflexion rather than final consonants since spellings of those Tangut syllables without -ng and -r also exist.
It is not clear what འ -H represents. Although it is tempting to reconstruct -ɦ like Nishida did or even -ʁ or -ɣ on the basis of -H, that letter inconsistently appears after many rhymes. For instance, it appears in transcriptions of six of the seven members of rhyme group I (R1-R5, R7, but not the rare R6) which also all have transcriptions without -H. Nishida (1964: 42-43) reconstructed this group as
|
Without -ɦ |
With -ɦ |
|
R1 -u |
R4 -uɦ |
|
R2 -ǐu |
R3 -ǐuɦ |
|
R5 -ʊ |
R6 -ʊɦ |
|
(no -ǐʊ) |
R7 -ǐʊɦ |
even though transcriptions of R1, R2, and R5 syllables exist with -H and transcriptions of R3, R4, and R7 syllables exist without -H.
For comparison, I reconstruct
|
Short |
Long |
|
|
Grade I |
R1 -ou |
R5 -oou |
|
Grade II |
R4 -ʊ |
R6 -ʊʊ |
|
Grade III |
R2 -(ɨ)u |
R7 -(ɨ)uu |
|
Grade IV |
R3 -iu |
R7 -iuu |
R7 combines two rhymes whose first vowel is determined by the preceding initial consonant.
I have never seen a language in which -ɦ is in most rhymes. -H is not a common written final consonant in Classical or Old Tibetan. Then again, I have never seen a language with a vowel system as elaborate as Tangut.
The Chinese transcriptions at first seem to indicate a wealth of final consonants. For example, R1 was transcribed with sinographs whose rhymes ended in *-k and *-ŋ as well as *zero as late as the 10th century. However, the Chinese transcriptions date from the end of the 12th century, so the apparent mix of MC *zero, *-k, and *-ŋ reflects the loss of final consonants in Tangut period northwestern Chinese rather than the presence of final consonants in R1. (Was the loss of final consonants in Tangut influenced by their loss in its more prestigious Chinese neighbor?)
Modern northwestern Chinese dialects lack final consonants other than -ŋ in Xi'an (Coblin 1994: 87-91). Although I doubt that those dialects are descendants of the Tangut period dialects, I think the avoidance of codas is a substratal feature that survived the shift from indigenous northwestern dialects to imported dialects from the east..