

wəi giẹ
龍星 'dragon star'
09.9.12.23:59: HOW MANY HADAN-KARACTERS ARE THERE?
Robinson's fictional Hadan-ka script for the Kasgen language reminds me of Khitan Large Script (KLS). Unlike sinography or even tangraphy (assumed to be more semantic than phonetic), neither Hadan-ka nor KLS have any known semantic-phonetic compounds.
KLS is assumed to be morphographic like Hadan-ka: i.e., each character represents a morpheme (minimal meaningful unit) regardless of number of syllables. Daniel Kane (1989: 11) estimated that "there seem to be about 1000 characters in this script"*. I hope his new book lists all of them.
1,000 does not seem to be sufficient to represent all the morphemes of any language. Sinographs strongly tend to correspond to morphemes. Today, I stumbled on these figures from Victor Mair (1996: 200):
1,000 sinograms [= sinographs] cover approximately 90% of all occurrences in typical texts, 2,400 sinograms cover 99%, 3,800 cover 99.9%, 5,200 cover 99.99%, and 6,600 cover 99.999% ... the command of 2,400 diverse signs - the number considered by educators as essential for basic reading and writing skills - is a formidable task.
Tangraphy is also largely morphographic. Most Tangut texts are written with about 3,000 different tangraphs. About 3,000 more tangraphs appear in the special vocabulary of ritual Tangut and/or in dictionaries but not regular Tangut texts.
The gap between 1,000 for KLS and 2,400-3,000 for sinography and tangraphy combined with the rapid introduction of the Khitan Small Script only five years later in 925 suggests that the KLS was a failure. It could not cover the whole of the Khitan language without expansion to about 3,000 graphs. The KLS obviously was sufficient for the texts on surviving Khitan imperial monuments but one could probably not write Khitan translations of, say, Confucian or Buddhist texts in KLS.
The Khitan language is assumed to be of the 'Altaic' type like Japanese. Normal Japanese text requires
- at least 2,000 sinographs to represent most nongrammatical morphemes
- hiragana to represent native Japanese endings and other grammatical morphemes
- katakana to represent recent, mostly non-Chinese loanwords
KLS would need 2,000 graphs equivalent to the 2,000 basic sinographs in Japanese. KLS has no equivalent of kana, so anything written in kana in Japanese would be written in KLS. Given the precedents of sinography and tangraphy, KLS would need about 400-1,000 more graphs to compensate for the absence of kana. To imagine what this expanded KLS would be like, take any Japanese text and imagine that each ending and word in kana had its own character. It seems that the most common KLS endings had different characters: e.g., the genitive ending had at least three different KLS characters:
至: looks like Chinese 至 'arrive' which is homophonous with Chinese 之 'genitive particle' if tones are disregarded
火 atop 日: looks like Chinese 'fire' atop 'sun'
日 atop 廾 (or 艹?): looks like Chinese 'sun' atop 'hands' or 'grass'
However, I don't know if the full conjugation of a Khitan verb could be written in KLS. Khitan imperial monuments presumably did not contain the full morphology of the language: e.g., a memorial would largely be written in past tenses and have few if any examples of future tenses. (I have no idea if Khitan even had tenses. I wonder what Kane's new book has to say about Khitan verb morphology.) And of course those momuments did not contain every word in the Khitan language. Perhaps KLS was devised specifically for those monuments and its deficiencies only became apparent once the Khitan tried to write other texts in it. (No non-monumental texts are known.) The Khitan might even have struggled to write the text on their monuments, since they might have discovered that they needed graphs to write words that weren't foreseen in 920.
KLS may have been hard to learn because of the (total?) lack of recurring semantic or phonetic elements. It's not clear if any graph could be used to predict the meaning or reading of any other graph. The genitive ending 火+日 did share 日 with the genitive ending 日+廾, but is it really likely that the two shared the same syllable in different positions? And neither looks anything like 至. The three do not share any element signifying possession. Perhaps 至 was used to write a borrowing of Chinese 之 'genitive particle' (nearly homophonous with Chinese 至 'arrive'), but the reasoning underlying the other two characters remains unknown.
On the other hand, Hadan-ka has recurring semantic elements but unlike Chinese may have no recurring phonetic elements. If Hadan-ka has at least one character per syllable, 6,300 characters (close to the c. 6,200 of Tangut!) would be needed to write all possible syllables in the language. This figure is based on
30 = 17 initials (including zero or glottal stop ʔ) + 13 s-clusters times
5 vowels (a e i o u) times
42 finals (16 simple finals plus 25 clusters plus zero for open syllables)
(9.13.1:46: I originally listed all the consonants in this post, but I moved them to a separate post.)
I presume Kasgen does not actually have 6,300 different syllables. There are probably many chance gaps in the system.
All known native Kasgen roots are monosyllabic like those of Chinese and Tangut. If Kasgen has homophonous roots like those languages, then those roots will require different characters.
In any case, I imagine that Kasgen would need at least 3,000 graphs (cf. my estimate for KLS) and that learning these graphs would be difficult not only because of their sheer number but because of the lack of recurring phonetic elements. The graphs for ha 'origin' and us 'place' presumably do not sound like any of their components
ha 'origin' = ? 'sun' + ? 'plains'
(neither 'sun' nor 'plains' is presumably ha)
us 'place' = ? 'tree' + ? 'mountain' + ? 'plains'
('tree', 'mountain', and 'plains' are presumably not us)
whereas
Mandarin 源 yuán 'origin' sounds like its phonetic 原 yuán 'field'
Mandarin 場 chǎng 'place' sounds almost like 暢 chàng 'smooth' sharing the phonetic 昜 yáng
(9.13.00:27: In Old Chinese, 場 暢 昜 all shared a common core *[h]laŋ:
場 *r-laŋ
暢 *t-hlaŋs [hl is actually a single consonant in OC; it may be from earlier *C-l-clusters like *sl-]
昜 *laŋ)
Next: Will Hadan-ka evolve like jurchegraphy - or sinography?
*This figure includes the graphs of the Gu taishi mingshi bei inscription. Excluding those graphs results in only 830 KLS graphs. There is no way 830 graphs could cover all the morphemes of a natural language.
I wish my friend John Cassidy the
wəi giẹ
龍星 'dragon star'
mə wəəi nɨɨ bɛɛ reʳ!
生日快樂!
a happy birthday!
09.9.10.23:45: LOW AND HIGH EQUALS ...?
David Boxenhorn asked if the Tangut word for 'ladder' were written as 'low-high': e.g., asI have not been able to find such a word.
reʳw
is a monosyllabic word for 'ladder, steps, stairs'.
However, there is another monosyllabic word whose character looks like 'low' (or 'ladder') + 'high':
reʳw
Can you guess what it means? Select the blank space below for the answers:
reʳw 'ladder' on the left is phonetic. I don't understand what 'high' is doing on the right. Li (1997: 1056) groups its meanings into three categories:1. 岸 'shore', 階 'steps', 限 'limit'
2. 賄賂 'bribery' (as the second half of a word gii reʳw spelled 'covet-shore')
3. 模樣 'appearance'
I don't understand why 'steps' is grouped with 'shore' and 'limit' (a shore is a limit of a body of water). 'Steps' and 'ladder' are probably the same word spelled two different ways, whereas 'shore/limit' and 'appearance' are probably unrelated homophones.
One could try to derive 'appearance' from 'limit' by regarding it as 'what is visible at the outer edge', but that's a stretch.
One might think 'coveting the shore' is a euphemism for 'bribery'. The problem is that Tangut has object-verb order so if gii reʳw is really 'covet' + 'shore', it may be a possessor-possessed compound noun: 'shore of coveting [greed?]'. gii is also a noun 'bribe' (< 'that which is coveted'?), whereas reʳw is never 'bribe' by itself. Perhaps gii reʳw 'bribery' is literally the 'shore of bribes' - but why a 'shore'?
A similarly puzzling compound is le reʳw, written as 'trample stairs'. Li (1997: 730) glossed it as 梯蹬 'rung' and Kychanov (2006: 694) glossed it as 'go upstairs', though I would expect reʳw le 'stairs trample' with normal Tangut object-verb order.
梯蹬 'rung' also has an odd structure. It looks like 'ladder-trample', even though Chinese normally has verb-object word order. Is le reʳw a calque of 梯蹬 based on the assumption that Tangut word order is often the opposite of Chinese word order?
09.9.9.23:55: RIDDLE OF THE LOW LADDER
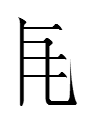
The analysis of the tangraph
bi 'low'
is unknown. It must be in the lost second volume of Tangraphic Sea. So I can only guess that the high-frequency left-hand element
dzwio 'person'
which occurs in a whopping one out of ten tangraphs - far too many to be a useful semantic element?* - is in 'low' because the sinograph
低
for 'low' also contains 亻 'person' on its left side. I have no idea why. Note that both the tangraph
bie 'high'
and the sinograph
高
for 'high' are single-element characters lacking 'person'. (The tangraph for 'high' may be derived from Chn 高 'high'.)
The left side of 低 'low' is a phonetic 氐 'foundation' (< 'that which is low'? - a case in which a root word is written with a graph derived from a graph for a derivative?).
One might expect the right side of Tangut bi 'low' to be a phonetic for 'bi' or a semantic element 'low' (but why couldn't such an element stand by itself for 'low'?). However, Nishida (1966: 244) regarded
reʳw 'ladder, steps, stairs'
one might expect ['ladder'] in a character for 'high', not 'low'!
I just realized it might be a cryptophonetic. In the northwestern Chinese dialect known to the Tangut, 低 'low' and its phonetic 氐 were something like *ti and 梯 'ladder' was something like *thi. The Tangut may have taken the phonetic on the right side of 'ladder' (弟 *thi 'younger brother'), distorted it into
and combined it with
dzwio 'person'
(equivalent to Chn 亻 'person')
to create a calque of 低 'low':
bi 'low'
One might expect a lot of sinographs with 亻 'person' on the left to have tangraphic equivalents with dzwio on the left. That is sometimes the case: e.g., 佛 'Buddha' corresponds to
Tha 'Buddha'
but not in most cases: e.g.,
liəʳ 'four', tʃhiw 'six', giəʳ 'nine'
do not have Chinese equivalents with 亻 'person' on the left: 四六九.
Subtracting 'person' from 'low' and replacing it with
'not'
results in
ʃæ̃ 'mountain'
borrowed from the northwest Chinese equivalent of modern Mandarin 山 shan 'mountain'. The Tangraphic Sea analyzed ʃæ̃ as
=
+
ʃæ̃ 'mountain' = left of mi 'not' + right of bi 'low'
i.e., a mountain is that which is not low.
If one did not know about bi 'low', one might think ʃæ̃ had something to do with not climbing or was something that wasn't a ladder.
*For comparison, only about 3% of sinographs contain 'person'. My pocket-sized Far East Concise Chinese-English Dictionary contains 217 graphs with 人 or 亻 'person' out of 7,331 graphs.
Few sinographs contain 'person' on the right, but Kychanov (2006) lists 356 tangraphs with 'person' on the right. Such right-hand 'person' elements in Tangut are probably not calques of sinographs in most (all?) cases.
The number of tangraphs with 'person' in other positions is unknown, but about one out of six tangraphs has 'person' on the left and/or right. Perhaps up to one out of five tangraphs has 'person' in it.
This figure is close to the frequency of short a in Sanskrit. One in every five phonemes in a Sanskrit text is a.
Yet 'person' cannot solely be a phonogram for a (or some other phoneme or, even less likely, a phoneme sequence) because it is unlikely that one out of six words would begin with the same phoneme or syllable. I did recently briefly consider the idea that initial 'person' could have been the Tangut B equivalent of alif, but I doubt one out of six Arabic or Hebrew words begin with glottal stop.
09.9.8.23:59: BI(E)-LOW MY USUAL STANDARDS
The Tangut part of yesterday's post should have been titled "Truly Ignorant". I am grateful to Guillaume Jacques for setting me straight. And the embarrassing thing is that my error could have been so easy to correct if I had only looked up 'high' and 'low' in Li Fanwen's dictionary. I wrote,
And perhaps some [of these Tangut words for 'high' and 'low'] are not really words at all, but only parts of words. Tangut studies tends to assume that each character represents a word in most cases, though closer study may reveal that a meaning assigned to a character really belongs to a disyllabic word written with that character.
I just assumed that if Gong Hwang-cherng regarded the homophonous syllables
biə 'high' (level tone)
biə 'low' (level tone)
as words, they were words. But Guillaume pointed out that they're actually reduplications of non-homophonous root syllables:
biə-bie 'high, more; to tower' < bie 'high'
biə-bi 'low, lower, less' < bi 'low'
(9.9.0:25: The spelling with tshee instead of bi in Kychanov [2006: 172] is an error.)
Neither biə is meaningful in isolation, so neither can be called a word.
The structures of the biə-characters are quite simple. They consist of
'mouth' (presumed to be derived from Chinese 口 'mouth' rather than 反 'turn over')
plus
bie 'high'
and
the right side of bi 'low'
(9.9.0:35: by itself this is reʳw 'ladder, steps, stairs' - which one might expect in a character for 'high', not 'low'!)
Why 'mouth'? 'High' and 'low' have nothing to do with eating, drinking, talking, or breathing. The choice of 'mouth' may have been influenced by Chinese characters for abstract words with the structure 口 'mouth' + phonetic: e.g., 吁 嗚 噫 for exclamations (with phonetics 于 烏 意).
Next: What's not low in Tangut?
9.9.1:13: Li Fanwen (1997: 884) lists an instance of a compound
biə-nie 'high antiquity'
(note the adjective-noun order within the compound instead of the normal noun-adjective order)
which has the first half of
biə-bie 'high'
not combined with bie 'high'. nie 'antiquity' and bie 'high' rhyme precisely. (They both have rising tones.) Could biə-nie 'high antiquity' be a pun on biə-bie 'high'?
The Vietnamese word điên 'crazy' came up when I was talking to a friend tonight, and I realized that it was a Chinese loanword once written as
癲 < 疒 'disease' (semantic) + 眞 'true' (phonetic) + 頁 'head' (semantic)
i.e., the 頁 head 疒 disease whose name sounds like 眞 'true'
癲 is still used to write Mandarin dian 'crazy', but it's now obsolete in Vietnamese which has switched to the Latin alphabet with many diacritics.
There is also an older variant 瘨 without 頁 'head': i.e., the 疒 disease whose name sounds like 眞 'true'.
In modern Vietnamese and Mandarin, 癲 'crazy' and its phonetic component 眞 'true' sound quite different, but they were nearly homophonous in Old Chinese (asterisks indicate reconstructions):
| 癲 | 眞 | |
| Vietnamese | điên | chân |
| Mandarin | dian | zhen |
| Old Chinese | *tˁin | *tin |
Like ancient Hebrew and both classical and modern Arabic, Old Chinese had two kinds of t, regular *t (like Hebrew ת and Arabic ت) and 'emphatic' *tˁ (like Hebrew ט and Arabic ط). These consonants changed over time and affected the following vowels, resulting in modern pairs of very different syllables only sharing a final -n in common.
Could the two words be related? It's remotely possible, but I doubt it. In early texts, 瘨 'crazy' meant 'illness, suffering, affliction, madness' (Karlgren 1957: 107). It was homophonous with other words written with the phonetic component 眞 'true':
傎 'overthrow, fall' (with semantic element 亻 'person')
蹎 'stumble, fall' (with semantic element 足 'foot')
顚 'top of the head; fall down, be overthrown, overthrow' (with semantic element 頁 'head')
巓 'top of a mountain' (with semantic elements 山 'mountain' and 頁 'head')
Karlgren derived 'fall down' from 'top of the head' via 'fall on the head'. Perhaps 'fall down' shifted to
'state of being fallen' > 'illness' > 'illness of the head' > 'madness' > 'crazy'
One could try to derive 眞 'true' from 'having the topmost quality', but that's a stretch. Old Chinese *tin 'true' could be from an earlier *tiŋ that might share a *t-ŋ root with 正 *teŋs 'straight, correct'. (This would rule out any connection with Written Tibetan bden-pa 'true' unless it were borrowed after *-iŋ > *-in in Chinese.)
I wonder if the *tˁin of 'top', etc. is from an earlier *tˁiŋ sharing a *t(ˁ)-ŋ root with 登 *tˁəŋ 'climb' (i.e., go to the top) and perhaps 丞 or 承 *dəŋ (< *N-təŋ?) 'lift up' (i.e., move toward the top).Schuessler (2007: 211) suggested that the near- 天 *thˁin 'sky' could belong to the 'top' word family, but he thought that 傎 'overthrow, fall' wasn't because he reconstructed it as *tlîn with an *l absent even though there is no Chinese-internal evidence for *l in that word. (He seems to have projected an *l from non-Chinese words for 'fall' into Chinese. I don't think Old Chinese allowed *t-syllable phonetic components like 眞 tin 'true' to be used to write *tl-syllables.)
9.7.23:27: Want to know what's truly crazy? In "Phonological Alternations in Tangut", Gong Hwang-cherng pointed out that Tangut had homophonous words for 'high' and 'low' even when tones are taken into consideration:
biə 'high' (level tone)
biə 'low' (level tone)
Fortunately, Tangut also had nonhomophonous words with those meanings: e.g.,
bie 'high' (rising tone)
(9.7.23:33: Note that this graph appears on the right of biə 'high' above.)
bi 'low' (rising tone)
Perhaps all these words share a common root *bi 'height'. And perhaps some are not really words at all, but only parts of words. Tangut studies tends to assume that each character represents a word in most cases, though closer study may reveal that a meaning assigned to a character really belongs to a disyllabic word written with that character.
A part does not necessarily have the same meaning as the whole: e.g., neither co nor ral in English coral mean 'coral' by themselves. Those two syllables have to combine to form a word meaning 'coral'.
Not quite.
Mandarin 旮旯(兒) gala(r) 'corner' (inexplicably written with characters composed of 九 jiu 'nine' and 日 ri 'sun; day') at first sounds like a loanword. Most Mandarin words can be broken up into monosyllabic roots, but there are no roots 旮 ga or 旯 la meaning 'corner'. 旮旯 gala is an indivisible disyllabic word; 旮 ga cannot appear without 旯 la and vice versa. Many indivisible disyllabic words are of foreign origin: e.g.,
剛果 Gangguo 'Congo'
拉丁 Lading 'Latin'
The Wikipedia entry for Shenyang Mandarin identifies 旮旯兒 gala(r) as being of "Manchurian" (sic) origin. However, the closest Manchu word I know of is gala 'arm'. Manchu hosho 'corner' has been borrowed into Mandarin as
火沙 huosha
胡沙 husha
和碩 heshi or heshuo (< earlier hoshi, hosho; Watters 1889 lists hoso = Pinyin hesuo and hoshêh = Pinyin heshe, but I've never seen the reading she for 碩 - is it obsolete?)
Classical Mongolian bulung 'corner' doesn't match 旮旯兒 gala(r) either.
I suspect that the real cognate of 旮旯兒 gala(r) is Mandarin 角落 jiaoluo 'corner'. 角 jiao means 'horn; corner' but 落 luo means 'fall'. 'corner-fall' makes no sense as a word for 'corner'. Hence 落 luo is probably a phonetic symbol without any etymological significance. If 落 luo doesn't mean 'fall' in 角落 jiaoluo, what is it? I think it's a partial reduplication of 角 'corner'.
Sagart (1999: 161) proposed that the Old Chinese root of 角 jiao < Old Chinese *krok was *rok as in 鹿 *rok 'deer' (i.e., a horned animal). I initially thought that *k-rok would reduplicate as *k-rok-rok, but that would ultimately develop into jiaolu, not jiaoluo. Mandarin -uo is from *-ak, not *-ok. Hence the reduplication must have taken place after the *-ok of 角 OC *krok became more *a-like. *k-rok could have shifted to something like *klæwk in northern colloquial Late Old Chinese. *klæwk would have reduplicated as *klæwk-læwk which simplified to *kæwk-læwk and then to
*kæwk-læk > *kjawk-lak > *kjaw-lɔ > standard Mandarin jiaoluo or*kjawk-lawk > *kjawʔ-lawʔ (based on the Hphags-pa transcriptions of the readings of 角 and 落) > perhaps some of the nonstandard Mandarin forms below?
depending on dialect.
Although 角 jiao and 落 luo don't rhyme in standard Mandarin, they still rhyme in some though not all other Mandarin dialects (likely archaic variants are in bold):
| Modern dialects | 角 | 落 |
| Beijing | jiao [tɕiau] | luo [luo] |
| Jinan | tɕiau | luə |
| Xi'an | tɕiau | luo |
| Hankou | tɕio | no |
| Chengdu | tɕyo; ko | no |
| Taiyuan (a Jin dialect) | tɕyəʔ | luəʔ, luaʔ |
I have also included a Jin dialect (formerly considered to be Mandarin) which preserves final glottal stops. Southern Chinese languages go further and preserve the *-k that was the source of those glottal stops.
旮旯 gala (IPA [kala]) might be an alternate simplification of *klæwk-læwk via *kak-lak. The noun suffix 兒 -r was added later. I still have no idea why the word was written as 旮旯.
9.7.1:07: The character shape 旮 has existed at least since the Ming as a variant of 旭 xu 'rising sun'. This usage of 旮 has nothing to do with 旮旯. I cannot find any premodern attestations of 旯 or 旮旯.
MacGillivray's (1921) dictionary has the spelling 噶拉兒 and the romanization ka-la-êrh equivalent to Pinyin galaer (but not galar!).
9.7.1:59: A very far-out possibility is that the pre-Old Chinese word for 'horn' was *karok which split into
- a fused monosyllabic form 角 *krok > Md jiao and its partial reduplication 角落 jiaoluo
- and a disyllabic form that ended up as 旮旯 gala [kala], still retaining the original first syllable after millennia (!)
Although I do think Old Chinese monosyllables often have disyllabic and possibly even trisyllabic origins, I am hesitant to propose such an extremely conservative first syllable: cf. 蝴蝶 Old Chinese *galep > Md hudie 'butterfly' in which the first syllable underwent regular sound changes to become hu-. If *karok were subject to regular sound changes, it would become Md guluo instead of gala.













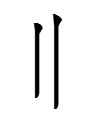




{kind=link}