TT5593
arrived in the mail today, five days after volume 1.
I never imagined that an article of mine would immediately follow an article by Roy Andrew Miller. To understand what this means to me - and how I ended up writing for Frederik Kortlandt's Festschrift in the first place - let's turn the clock back over twenty years ...
I grew up in Hawaii - a linguist's paradise*. Asian and Pacific languages are everywhere, and even though English dominates the media, Pijin is the lingua franca of the streets.
But I regret being oblivious to this diversity until a late age. In elementary school, one of my best friends was Lao. I wasn't curious about his language - or about the languages of my classmates. I had fallen in love with sinography, and all I cared about were languages with Chinese characters. At the time I only knew of two such languages: Japanese and Chinese. Starting in third grade, I borrowed Chinese textbooks from public libraries.
Although my best friends at Punahou** were Koreans, I knew nothing about Korean until my sophomore year. Korea somehow became the topic of my final project in Asian studies. This assignment set the course for the rest of my life. Two revelations shook me to the core.
First, I learned that the version of history that my Japanese tutor had taught me was ... incomplete, to say the least. My textbooks from Japan never mentioned the crucial role of Korea in the development of early Japan. Nor did they even allude to the horrors of the Japanese colonization of Korea. I became determined to discover the truth, and my research went far beyond what was required. I had to know what really happened. I retain an interest in these two periods of Korean history to this day.
Second, I learned that the Korean language used Chinese characters. It wasn't an alien entity written with circles anymore. It became relevant. I started memorizing the Korean readings of Chinese characters. But Korean was far more than a treasure trove of Chinese borrowings. Its alphabet was brilliantly designed. I learned it almost instantly. And its grammar was very similar to that of Japanese. I was fascinated by the idea of a language that was simultaneously familiar yet alien. I had studied German for four years by that point, but that wasn't very alien - its relationship with English was obvious. Korean, on the other hand, was said to be related to Japanese even though it didn't sound like Japanese. Thus my interest in historical linguistics was born.
In my senior year, I only applied to universities that offered both Korean and Japanese. There were only a few such institutions back in 1988: Berkeley, Stanford, and the Ivy League. Most rejected me. I'm glad that they did, because there's more to a school than its reputation. Berkeley may not be number one in the American academic hierarchy, but it made me who I am today.
Roy Andrew Miller was my first historical linguistics teacher. I never met him (even though he later moved to Hawaii!). I only knew him through his books in the Berkeley library. He believed that Japanese was a member of the 'Altaic' language family containing Manchu, Mongolian, and Turkish in addition to Korean. I had my hands full with Japanese, Korean, Chinese, and Sanskrit as an undergraduate, so I couldn't study the other Altaic languages yet.
However, they were on my to-do list for graduate school. I chose the University of Hawaii, not only because I wanted to go home, but also because I wanted to become the disciple of Altaic specialist Gisaburou N. Kiyose. With my luck, he was gone by the time I started my master's program in Japanese! Nonetheless, the University of Hawaii had no shortage of great gurus such as Sino-Tibetanist Anatole Lyovin (who introduced me to Tangut and Tibetan), Ryukyuanist Leon Serafim, Japanologist Bart Mathias, and Austronesianist Bob Blust (click to read his origin story!).
In 1995, another Altaic specialist arrived. Alexander Vovin taught me Manchu, Classical Mongolian, and Old Turkic. As I struggled with these Altaic languages, I came to question the Altaic hypothesis. It seemed plausible when I was eighteen and fresh out of high school. But now that I was actually learning Altaic languages instead of merely reading about them, I suspected that Altaic wasn't like an established language family such as Indo-European or Austronesian. Altaic languages are undoubtedly similar, but this similarity may be due to contact and convergence - recurring themes throughout my linguistic career.
Some linguists work on a single language, whereas I am interested in how languages influence one another. It was my 1995 paper on early Chinese loans in Korean and Japanese that put me on Frederik Kortlandt's mental map. He mentioned it to me when we first met in Vancouver in 1999.
At his side were his students Elisabeth de Boer and Martine Robbeets. Their contributions are also in volume 2 of Evidence and Counter-Evidence.
I owe Elisabeth and her family an unpayable debt for taking care of me during my first month in the Netherlands. Elisabeth and I spent innumerable hours discussing linguistics and life. She greatly expanded my intellectual horizons. My 2003 paper on vowels in pre-Old Japanese would not have been possible without her help. Her article on Japanese pitch accent in Evidence draws upon her 2005 PhD dissertation which is to appear soon in book form. I wonder what she's doing now.
Martine is a proponent of Altaic as a language family. Her 2003 dissertation is entitled, "Is Japanese related to the Altaic languages?" Her answer is 'yes'; mine is 'probably not'. Her article in Evidence also has a question for a title: "If Japanese is Altaic, how can it be so simple?" That may sound odd since Japanese is widely regarded as a difficult language. Martine is referring to the simplicity of Japanese syllable structure compared to other Altaic languages. I may blog about her article after I'm done with my Obama series.
*I'm surprised that the US English Foundation states there are only 91 languages in Hawaii (excluding Pijin!) and that Honolulu County is only #31 in terms of language diversity. California might be the language king of the US with 207 languages and "Los Angeles County’s 135 languages represented the highest number recorded in any county in the United States."
**A school which may soon be best known for its alumnus Barack Obama, who graduated ten years before I did. His sister graduated a year ahead of me.
08.11.14.23:59: (OBA)MA (PART 3)
Last night, I wrote:R18 is strongly correlated with Chinese Grade II -a in the transcriptional data, so the two rhymes must be similar if not identical. The problem is that the phonetic value of Grade II -a in Tangut period northwestern Chinese [TPWNC] is uncertain.
In modern northwestern dialects, the reflex of Grade II -a is generally -ia after gutturals and -a elsewhere. -ia agrees with Gong's reconstruction of Grade II -ia in both Tangut and TPNWC. -ia is also similar to Arakawa's Tangut Grade II -ja. Problem solved?
No. Note that I said "generally". Coblin (1994: 106) pointed out that
in certain colloquial readings DH [Dunhuang] and LZ [Lanzhou] have -a instead [after gutturals].
| Sinograph | Tibetan transcription of NW Late Middle Chinese | Gong-style TPNWC reconstruction | Dunhuang colloquial | Dunhuang literary | Lanzhou colloquial | Lanzhou literary |
| 蝦 | he | *xia | xə | (none) | xa | (none) |
| 下 | ha(H) | *xia | xa | ɕia | ɕia |
(The Gong-style reconstructions are mine using his system.)
Dunhuang and Lanzhou colloquial can also lack an expected -i- after gutturals before codas:
| Sinograph | Tibetan transcription of NW Late Middle Chinese | Gong-style TPNWC reconstruction | Dunhuang colloquial | Dunhuang literary | Lanzhou colloquial | Lanzhou literary |
| 解 | gaH, ka, ke, geHi | *kiej́ | kɛ | tɕiə | kɛ | tɕie |
| 皆 | keHi, keHɨ, ke | (none) | tsɛ | |||
| 咸 | ham | *xiã | xæ̃ | ɕiæ̃̃ | xɛ̃ | ɕiɛ̃ |
| 杏 | (none) | *xiej | xə̃ | ɕiə̃ | ? | ? |
Here's what I think happened:
1. In NWLMC, Grade II a was *æ. This vowel was absent from Tibetan, so it was transcribed in Tibetan as either a or e:
| NW Late Middle Chinese | Tibetan transcription |
| *-æ | -a, -e |
| *-æj | -a(H), -e, -eHi, -eHɨ |
| *-æm | -am |
| (*-æŋ >) *-æ̃ɰ | -e, -eHi, -eHu |
2. In TPNWC, Grade II a was still *æ, and was transcribed with Tangut Grade II rhymes:
| My Tangut period NW Chinese | Tangut transcription in Forest of Categories |
| *-æ | R18 -æ |
| *-ɛj | R35 -ɛ |
| *-æ̃ | R18 -æ |
| *-ɛ̃j | R35 -ɛ, R42 -ɛ̃ |
I'm surprised that TPNWC *-æ̃ does not correspond to R26 *-æ̃.
3. These low front vowels are more or less retained in the colloquial strata of Dunhuang and Lanzhou.
4. The Dunhuang and Lanzhou literary forms with -i- are imports from the east and are not evidence for *-i- in TPNWC or for Grade II medial -i- or -j- in Tangut.
5. The palatal initials of the Dunhuang and Lanzhou literary readings of 下解皆咸杏 are the results of a later wave of eastern influence: e.g.,
| Sinograph | NWLMC | TPNWC | Lanzhou stage 1 (native word only) | Lanzhou stage 2 (native word coexisting with eastern import) | Lanzhou stage 3 (*xi > ɕi sound change from the east) |
| 下 | *xɦæ, transcribed as Tib ha(H) | *xæ, transcribed as Tangut xæ R18 1.18 | *xa | *xa, imported *xia | xa, ɕia |
I had originally intended to describe an alternate scenario in which Lanzhou a in words like xa was from TPWNC -ɑ(ˁ), but such a vowel's NWLMC ancestor would not have been transcribed with Tibetan e.
I am inclined to favor my solution C from last night
| R18: Grade II (front) | R19: Grade III (palatal glide + central) | R20: Grade IV (central) | R17: Grade I (back) |
| -æ | -ja | -a | -ɑ |
and reconstruct my transcription of ma in Obama
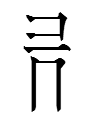
TT5593
as ma R20 1.20.
However, Grade III was probably less palatal than Grade IV in Chinese, so I would expect the reconstructions of R19 (Grade III) and R20 (Grade IV) to be reversed.
Grade III R19 -ja follows the Homophones chapter II initial w- as well as chapter VII palatals and chapter IX liquids (l- [ʎ]? and ʑ, both palatal?). Perhaps wja R19 was [vja] with a cluster like the v- [vj] of Saigon Vietnamese. (v- is generally [j] in Saigon, but [vj] may be an archaism reinforced by spelling.)
There are two major problems with reconstructing Grade IV R20 as -a. First, a low central vowel has nothing phonetically in common with other Grade IV rhymes such as R11 -i and R37 -ie. Second, even if R20 is reclassified as some other grade to avoid the first problem, it transcribes Chinese rhymes with palatal vowels in the Forest of Categories: e.g,
吉
transcribed in Tibetan as kyir in the pre-Tangut period
transcribed in Tangut as TT0549 k- R20 1.20
tɕi < *ki in modern NW Chinese dialects
Why would TPNWC *ki be transcribed as ka R20? Was TT0549 kia or even kie in the Tangut dialect underlying the transcription? Perhaps I should reconstruct two dialects instead of trying to reconcile seemingly contradictiory evidence:
| R20 -ia (originally) | |
| Dialect A: -a | Dialect B: -ie |
| Transcribed in Tibetan as -a; underlies transcriptions of Sanskrit -a (via Tibetan?) |
Used to transcribe Chinese front vowel rhymes |
08.11.13.23:59: (OBA)MA (PART 2)
I am uncomfortable about reconstructing
TT5593 mia R20 1.20
with -i- because I cannot find any evidence for such a medial*. In other words, my theory makes a false prediction, so it must be false.
Here are two alternative reconstructions for the first group of a-rhymes in Tangut. Both lack -i- in R20.
Solution A
| R20: Grade IV (front) | R19: Grade III (palatal glide + front) | R17: Grade I (central) | R18: Grade II (back; pharyngealized?) |
| -æ | -jæ | -a | -ɑ(ˁ) |
Solution B
| R18: Grade II (front) | R17: Grade I (central) | R20: Grade IV (back) | R19: Grade III (palatal glide + back) |
| -æ | -a | -ɑ | -jɑ |
R17 is the most common of the four rhymes** and therefore should have a simple reconstruction: -a.
R18 is the only one of the four never used to transcribe Sanskrit, so it has to be a vowel absent in Sanskrit. R18 is strongly correlated with Chinese Grade II -a in the transcriptional data, so the two rhymes must be similar if not identical. The problem is that the phonetic value of Grade II -a in Tangut period northwestern Chinese is uncertain. I will examine the ambiguous evidence next time. Grade II -a in the two languages could have been a front or a back vowel. Another possibility that occurred to me tonight is a complex, un-Indic diphthong -ɨa with an achromatic high vowel reflecting Old Chinese *-r-. In any case, there is no evidence for a -i- or -j- in premodern NW Chinese Grade II -a which was transcribed in Tibetan as -a, not -ya or -iHa.
R19-R20 were used to transcribe Sanskrit -a so it is unlikely that they were -æ as in solution A. On the other hand, Grade III and IV appear to have front vowels so a back vowel for these rhymes is also unlikely. Maybe R17 had a back vowel and R19-20 had a central vowel:
Solution C
| R18: Grade II (front) | R19: Grade III (palatal glide + central) | R20: Grade IV (central) | R17: Grade I (back) |
| -æ | -ja | -a | -ɑ |
That might explain why R19-20 are more commonly used to transcribe Sanskrit -a than R17.
R19 is correlated with Homophones Chapter VII initials (palatals or alveopalatals), so it could have had a palatal -j-. Grade III and IV are often not distinguished in Tangut, so they must be phonetically similar. Hence I reconstruct one vowel for both grades and assume that a glide accounts for the distinction between the two.
11.14.0:24: For comparisons with solutions A-C, here's the reconstruction I've been using until recently:
| R18: Grade II (front low vowel) | R20: Grade IV (high front vowel + central low vowel) | R19: Grade III (high central vowel + central low vowel) | R17: Grade I (central [or back?] low vowel) |
| -æ | -ia | -ɨa | -a or -ɑ |
These roughly correspond to my reconstruction of -a-rhymes in generic Middle Chinese:
| 麻 Grade II (front low vowel) | 麻 Grade IV (high front vowel + front low vowel) | 歌 Grade III (high central vowel + central or back low vowel) | 歌 Grade I (back low vowel) |
| *-æ | *-iæ | *-ɨa or *-ɨɑ | *-ɑ |
There is no guarantee that Tangut period NW Chinese had
similar rhymes.
*11.14.0:28: Some oddities in Tangutized Sanskrit are due to borrowing from Sinicized Sanskrit. However, Tangut mia R20 corresponds to Tangut period NW Chinese Grade I *mba, not *mbia in Sanskrit loans: e.g.,
Sanskrit mahaa- 'great'
Tangut mia R20 1. xa ?R17 ?.? (< via Written Tibetan ma ha?)
Tangut period NW Chn 摩訶 *mbɔ xɔ < Middle Chinese *ma xa
**11.14.1:04: An easy way to estimate the frequency of a Tangut rhyme is to look at the homophone groups listed in Sofronov (1968 II: 6-59). R17 is the most common of the four rhymes:
| Tangut rhyme | Level tone homophone groups in Tangraphic Sea | Level tone homophone groups in Mixed Categories (incomplete copy) | Rising tone homophone groups probably in the lost second volume of Tangraphic Sea (estimated on the basis of Homophones) | Rising tone homophone groups in Mixed Categories (incomplete copy) | Total |
| R17 | 37 | 2 | 19 | 1 | 59 |
| R18 | 19 | 1 | 9 | 0 | 29 |
| R19 | 11 | 2 | 6 | 1 | 20 |
| R20 | 17 | 1 | 10 | 0 | 28 |
Unfortunately, these figures exclude tangraphs with uncertain rhymes: e.g., ?xa R17 in mia xa 'great'.
08.11.12.23:55: (OBA)MA (PART 1)
The tangraph
TT5593 mia R20 1.20
has a medial -i- in my reconstruction because R20 is a grade IV rhyme in rhyme group IV:
| Rhyme | My grade | My reconstruction | Gong's grade | Gong's reconstruction | Arakawa's grade | Arakawa's reconstruction | Tibetan transcriptions | Used to transcribe Sanskrit |
| R17 | I | -a | I | -a | I | -a | -a(H) | -a |
| R18 | II | -æ | II | -ia | II | -ja | (none known) | |
| R19 | III | -ɨa | III | -ja | IIIa | -aa | -a(H) | -a |
| R20 | IV | -ia | IIIb | |||||
But TT5593 mia R20 1.20 represents Sanskrit ma, not mya (cf. Gong's mja and my mia) or maa (cf. Arakawa's maa). Moreover, its homophone
TT4250 mia R20 1.20 'or; other; maybe; probably'
(why does it have Li Fanwen radical 025 'water' on the left next to 'person'?)
was transcribed in Tibetan as ma, not mya or a Tibetan transcription of Skt maa.
None of the above recent modern reconstructions can account for the Tibetan and Sanskrit evidence against a palatal -i- or -j-.
TT5593 mia R20 1.20 can also mean 'end' (and by extension, 'east'?). If mia 'end' is a loanword from Middle Chinese 末 *mat, then this etymology would be another point in favor of reconstructing R20 without any medials.
Older reconstructions of R20 generally don't fit the evidence either, and some are downright baffling (e.g, Hashimoto's nasals in R17-R20 and Huang's nasalization in R18-R20):
| Rhyme | Sofronov 1963 | Nishida 1964 | Hashimoto 1965 | Sofronov 1968 | Huang 1983 | Li Fanwen 1986 |
| R17 | -æ | -ɑɦ | -ääwN | -a | -(i/u)ɑ | -aa |
| R18 | -æ' | -a | -äwN | -â | -ɑ̃ | -ia |
| R19 | -jæ | -ja | -jäwN | -ja | -iɑ̃, -iã | -jaa |
| R20 | -æ˔ | -aɦ | -ääN | -aC | -æ̃ | -a |
Only Li Fanwen reconstructed a simple -a for R20.
Next: What if I reconstructed R20 as a simple vowel?
08.11.11.23:59: BA(RACK O)BA(MA)
The tangraph
TT4348 ba R17 2.14
has no meaning. It represents the first syllable of the Tangut surname
ba bəi*
and transcribes Sanskrit bha and vat in
ba ɣa ba (< bhagavat)
(why not ba ga wa?)Nishida (1966) has no gloss for
though it appears to mean 'child' in some (but not all) tangraphs containing it. Its function in ba is unknown. I hope it is not an arbitrary placefiller.
Li Fanwen radical 158
The right side of ba
Li Fanwen radical 333 (meaning unknown)
is clearly phonetic, as it also appears in tangraphs for ba-like syllables:
| Tangraph | TT | Reconstruction | Rhyme | Tone.rhyme | Gloss | Notes |
 |
0876 | bã | R25 | 1.24 | tray | < Middle Chinese 盤 *ban; 'wood' over phonetic (second half of 'witticism' below) |
 |
2052 | bạ | R66 | 2.56 | first half of surname bạ rieʳ | function of 'horned hat' unknown; phonetic is 'help' below |
 |
3676 | ba | R17 | 2.14 | second half of pɛ̣̃ ba 'witticism' | why is 'person' on the left instead of a language radical? |
 |
4349 | bạ | R66 | 2.56 | help | phonetic is Skt transcription graph ba; function of ヒ unknown |
 |
5709 | bã | R25 | 1.24 | second half of bã ŋææ 'goose' | 'bird' on left; ŋææ < 雁 Middle Chinese *ŋænh; etymology of first syllable unknown; did nasality of second syllable onset spread to vowel of first syllable? |
 |
2542 | bɔɔ | R55 | 1.53 | patrol | why is TT1612 kạ 'heavy' on the right? |
The bottom of Li Fanwen radical 333 resembles the 女 at the bottom of the sinograph 婆 corresponding to Sanskrit ba, but the tops don't match.
*08.11.12.3:00: The tangraph for the second half of the surname ba bəi may be derived from Li Fanwen radical 177 'horse' which in turn was derived from Tangut period NW Chinese *mba 'horse':
<
< 馬
08.11.10.23:55: EVIDENCE AND COUNTER-EVIDENCE, VOLUME 1
Professor Frederik Kortlandt of Universiteit Leiden found me when times were tough in 1999 and offered me a position that enabled me to finally meet Guillaume Jacques, Wolfgang Behr, and Laurent Sagart in person the following year.
Guillaume guided me through the streets of Paris at night and showed me his copy of the holy grail - Li Fanwen's 1997 Tangut dictionary. Although I have not seen him in eight years, I continue to benefit from his immeasurable knowledge and insight, and he is always in my thoughts as I stumble my way through the mysteries of Tangut.
Wolfgang invited me to lecture on Tangut at Ruhr-Universität Bochum. He let me stay overnight at his place where I drove him nearly mad by talking nonstop about linguistics for hours. He introduced me to Axel Schuessler's Later Old Chinese reconstruction whose 'vowel bending' has been an enormous influence on my revision of Gong Hwang-cherng's Tangut reconstruction.
In Leiden, I moved into the office formerly occupied by the late Sergei Starostin. I had studied Russian so I could read his book on Old Chinese (as well as the writings of Nevsky and other Russian Tangutologists). It is a shame that my only encounters with Starostin were anything but academic. I had difficulty with the lock of my office, so he had to open my door for me at least once, if not twice. The simplest things can be so hard.
Once I became accustomed to my new setting, I read Sagart's The Roots of Old Chinese which blew my mind. Click on the link to see Wolfgang's review. This "trailblazing book," as Wolfgang put it, has been yet another major influence on my Tangut reconstruction. Moreover, the combination of Schuessler's and Sagart's work made me abandon Starostin's Old Chinese reconstruction and set me on the path that I've been treading since.
Years later, after I left academia, I was offered a chance to contribute to a volume in honor of my benefactor's sixtieth birthday. How could I say no? It would be no exaggeration to say that Kortlandt's generosity had changed my life. I live to uncover the history of Asian languages and I could never look at them the same way again.
It was easy to choose a topic for the Festschrift. In the Leiden library, I had accidentally found a book on Maltese describing the 'bending' of vowels after ajn (written as għ in Maltese):
i > aj, u > ow
This reminded me of the 'bending' of Schuessler's Later Old Chinese reconstruction:
*i > *ei, *u > *ou
What caused this bending? I was agnostic back in 2000, but by 2002, the answer dawned on me, and I revealed it in a lecture at the University of Oregon. I was busy with my book on Old Japanese and my article on pre-Old Japanese (which would never have been possible without the help of Elisabeth de Boer, whose family hosted me during my first month in the Netherlands) as well as teaching, so I had never gotten around to writing up my theory. Now I had my chance, and three years later, it has seen print in Evidence and Counter-Evidence: Essays in Honour of Frederik Kortlandt, Volume 2. (I could never have guessed that my name would be next to that of Roy Andrew Miller, my idol as an undergraduate in Berkeley!) I'm still waiting for my copy.
So why is this post titled "Volume 1"? Because that's the volume that arrived in the mail today. I ordered it primarily to see a contribution by my next-door neighbor in Leiden, Petri Kallio ("On the 'early Baltic' loanwords in common Finnic') But there is much more in the book that appeals to the amateur Indo-Europeanist in me. For instance, I've been meaning to write a post speculating on Proto-Germanic obstruents and I wonder if my thoughts are anything like those of Harry Perridon in "Reconstructing the obstruents of Proto-Germanic". I doubt it. Maybe I should write my post before reading Perridon's article.
I must conclude this post by saluting all those who made my stay in Europe enlightening and enjoyable. It was a great honor to work for a man whose
... empiricism does not rely on facts proving the theory. The role of the theory is to allow its own disproof: "a new insight means a new way of looking for counter-evidence rather than a new way of looking at known facts". This paradox is due to the fact that "human beings are driven by ideas". For if humans risk becoming victims of their own ideas, it is the responsibility of science to test these concepts in the exploration of unknown territories.
- Alexander Lubotsky, Jos Schaeken, Jeroen Wiedenhof (with quotes by Kortlandt) in the preface of Evidence and Counter-Evidence, vol. 1
I'll write about volume 2 when I get it - soon, I hope!
08.11.9.23:59: SANSKRIT VOWEL TANGRAPHS
All the Sanskrit vowels (excluding syllabic liquids) have pairs of transcriptive tangraphs. Many are clarifiers of their opposite-length counterparts in Homophones: e.g., u is used to clarify uu, and vice versa.
| Skt short vowel | Tangraph | TT | Reading |
Rhyme | Tone. rhyme |
Skt long vowel | Tangraph | TT | Reading | Rhyme | Tone. rhyme |
| a |
|
0489 | ʔa | ?R17 | ?1.17 | aa |
|
0544 | ʔææ | R23 | 2.20 |
| i |
|
4598 | ʔɨi | R10 | 1.10 | ii |  |
4655 | ʔɨi | R10 | 2.9 |
| u |  |
4635 | ʔwəu | R1 | 1.1 | uu |  |
4636 | ʔwiụ | R62 | 1.59 |
| e (long!) |  |
4611 | ʔɨe | R36 | 1.35 | e (ai?) |  |
4437 | ʔɨe | R36 | 2.32 |
| o (long!) |  |
5488 | ʔo | R51 | 1.49 | o (au?) |  |
5487 | ʔo | R51 | 2.42 |
Problems (partly carried over from my previous posts on the o-tangraphs):
1. If these tangraphs represent Sanskrit long and short vowels, why do their reconstructed readings only have short vowels with one exception (ʔææ for Skt aa)?
2. Most members of pairs have opposite tones and there is no consistent correlation between tones and Sanskrit vowel length. Was the choice of tones arbitrary?
3. Why do the readings for the a/aa pair belong to different grades: II and I? Does this reflect the qualitative difference between Sanskrit a [ə] and aa [a]?
4. Why do the readings for the i/ii and e tangraphs have Grade III medial -ɨ-? Why aren't they simply Grade IV ʔi(i) and Grade I ʔe(e)?
5. Why do the readings for the u/uu tangraphs have medial -w- and belong to different grades (I and merged III/IV)? (I have carried this medial over from Sofronov's and Gong's reconstructions.) Does the -i- in the uu-tangraph correspond to the *-i- in Tangut period NW Chinese 優 ?*ʔiw, chosen to transcribe Sanskrit u centuries ago when it was pronounced *ʔu?
6. How can there be tangraphs for short and long e and o? Sanskrit only has long e [ee] and o [oo]. Do the pairs of e- and o-tangraphs really represent Sanskrit e/ai and o/au?
More problems added 11.10.1:55:
7. Homophones lists the Sanskrit vowel tangraphs as a set (aa ii u uu e ai o au; 45B75-46A14) in the 'isolated' (i.e., homophoneless) graph section of Chapter VIII (glottals). Why are the tangraphs for a and i (45B14 and 45B18) listed separately in that section? If none of the vowel tangraphs had homophones, why not place them all together?
8. Is it really possible that almost none of the Sanskrit vowels sounded like native Tangut words: i.e., that there were few native Tangut words consisting of simple vowels like a, i, u, e, o? A few of the Sanskrit transcription tangraphs can represent Tangut exclaimations. The i-tangraph is 'alas', the ?ai-tangraph represents the sound made to call (bull-)calves, and the ?au-tangraph represents a moaning sound. The uu and u-tangraphs together may be a disyllabic word for 阿弟 'younger brother' (Kychanov 2006: 248 1374-1).
Could these Sanskrit vowel tangraphs have been pronounced without glottal stops in Tangut, distinguishing them from native ʔV-words: e.g.,
əu R1 1.1 'Skt u' vs. ʔəu R1 1.1 'cemetery; ashes of the dead'
(the latter is phonetic in the former which has 'language' added to the left)
9. Why don't the readings for the u/uu-pair
have the same rhyme? Why does the uu
tangraph have a glottalized vowel which does not exist in Sanskrit?
10. Why doesn't the tangraph for 'long' Skt e have
Li Fanwen radical 308 'long'
on the right (or any elements in common with its 'short' counterpart)?
11. Were special tangraphs for Skt syllabic ṛ(ṛ) and ḷ (theoretically also long) ever devised? I have seen medial -ṛ- transcribed as
TT4911 riʳ R84 1.79 (Kychanov 2006: 361, 2390-3)
but I don't know if this is the only tangraph for ṛ.