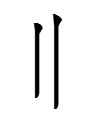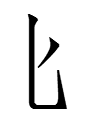TT4732 kwe R34 1.33 'respectful'
TT4743 ti R11 1.11 'not'
08.6.7.23:54: HLAI -ɯ
Yesterday, I discovered a book I forgot I had: 苑中树 Yuan Zhongshu's 黎语语法纲要 Outline of Hlai Grammar (1994).
Despite its title, it also provides an introduction to Hlai phonology. One characteristic that jumped out at me was the presence of final -ɯ, which is also a characteristic of Sofronov's Tangut reconstruction. Unlike Sofronov's -ɯ, Hlai -ɯ contrasts with final -u, which is absent from Sofronov's diphthongs:
通什 Tongshi Hlai
|
|
a |
aa |
e |
ee |
|
-u |
-au |
-aau |
-eeu |
|
|
-ɯ |
-aɯ |
-aaɯ |
-eɯ |
白沙 Baisha Hlai
|
|
a |
aa |
e |
|
-u |
-au |
-aau |
-eu |
|
-ɯ |
-aɯ |
-eɯ |
(保定 Baoding, 西方 Xifang ['Western', a variety of 美孚 Meifu], and 加茂 Jiamao lack -ɯ. Yuan does not cover the phonology of dialects other than these five.)
Without comparative data, I don't know whether pre-Tongshi *-eu lengthened to -eeu, or if pre-Baisha *-aaɯ merged with *-aau.
What I can say with certainty is that the distribution of -ɯ is very restricted. It cannot occur after vowels other than a(a) or e(e) in any of the dialects covered by Yuan, whereas -u is much more widely distributed:
| Baoding | Xifang | Baisha | Tongshi | Jiamao | |
| -au | + | + | + | + | + |
| -aau | + | + | + | + | + |
| -eu | + | + | |||
| -eeu | + | + | + | + | |
| -iu | + | + | + | + | + |
| -iiu | + | + | + | ||
| -iəu | + | ||||
| -ɔɔu | + | ||||
| -ou | + | + | + | + | + |
| -ɯɯu | + | ||||
| -əəu | + | ||||
| -iau | + | + | + | + | |
| -uau | + |
(6.8.0:01: Although Jiamou has -u after more vowels than other dialects, I cannot say that it best preserves Proto-Hlai rhymes lost elsewhere without further study. Jiamou might have split a single proto-rhyme into several rhymes depending on the initial.)
Li Fang-kuei's (1977) Proto-Tai*-ï (which I will rewrite as *-ɯ) could occur after vowels other than a and e:
| (no *-iɯ) | *-uɯ- (in closed syllables only?) | |
| *-eɯ or *-ɛɯ | *-əɯ (> early Siamese ใ *-aɯ) | *-oɯ |
| (no *-aɯ!) | (no *-ɔɯ) |
I find the absence of *-ɯ after *a to be strange, so I would rewrite this table as
| (no *-iɯ) | (no *-ɯɯ) | (no *-uɯ) |
| (no *-eɯ) | *-əɯ (= LFK's *-eɯ or *-ɛɯ) | *-oɯ |
| (no *-ɛɯ) | *-aɯ (= LFK's *-əɯ; > early Siamese ใ *-aɯ) | (no *-ɔɯ) |
Since this post is about Hlai and not Proto-Tai, I will explain my revisions in a footnote*.
Ostapirat's (2000) Proto-Kra *-ɯ occurred exclusively after *a.
Offhand, I wonder if:
- Proto Kra-Dai had *-ɯ after a number of vowels
- Proto-Kra
either merged all vowels to *a before *-ɯ
or *-ɯ became something else after non-*a vowels
- Proto-Hlai
either merged all vowels to *a(a) and *e(e) before *-ɯ
or *-ɯ became something else after non-*a(a)/*e(e) vowels
- Proto-Tai
either retained many (most? all?) of the original *-Vɯ diphthongs
and/or developed new *-ɯ (e.g., from *-l, which is reconstructible for Proto-Kra?; this is a blind guess, as I do not know what PK *-l corresponds to in PT)
I know nothing about the status of -ɯ in the immediate sisters of Tai (Kam-Sui and Be), so I am not sure whether the three or four *-Vɯ diphthongs should be projected upward into their common ancestor Proto-Kam-Tai.
6.8.00:09: Structure of the Kra-Dai family (after Ostapirat 2000: 1)
| Kra-Dai (a.k.a. Tai-Kadai) | ||||
| Kra (a.k.a. Kadai) | Hlai | Kam-Tai | ||
| Be | Tai | Kam-Sui | ||
*6.8.00:36: I have made three changes to Li Fang-kuei's Proto-Tai reconstruction:
| Li Fang-kuei's Proto-Tai | This site | Li Fang-kuei's | ||
| Proto-Southwestern Tai | Proto-Central Tai | Proto-Northern Tai | ||
| *-uɯ- | ? | *-uə- ~ *-ua- | *-ɯə- ~ *-ɯa- | |
| *-eɯ or *-ɛɯ | *-əɯ | *-aɯ | *-ɯɯ | |
| *-əɯ | *-aɯ | *-aɯ | ||
1. PT *-uɯ-: Li (1977: 284) gave only two
examples in closed syllables:
*ruɯŋ 'ear of corn, paddy, etc.'
*suɯn 'garden'
(Forms generated using Proto-Tai'o'Matic.)
No other *Vɯ diphthong can occur before a nasal or any other coda. There is nothing special about *uɯ that would account for this unique distribution, so I think something else should be reconstructed. Maybe 'ear of corn' and 'garden' have irregular reflexes of *-ɯə- and/or *-ɯa-.
2. PT *-eɯ or *-ɛɯ: This rhyme has no palatal vowel reflexes. Hence I prefer to reconstruct it with a neutral vowel as *əɯ.
3. PT *-əɯ: This rhyme has reflexes with (*)a: e.g., early Siamese ใ *-aɯ > modern -ai. Therefore I prefer to reconstruct it as *-aɯ.
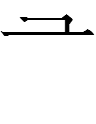
08.6.6.23:23: BIG MYSTERY, SMALL SURNAME
In "Acronymic Analogy", I presented the two distinct graphic analyses for each reading of
TT4732 kwe R34 1.33 'respectful'
TT4743 ti R11 1.11 'not'
I know of two other tangraphs with double readings.
The first is
TT0971 liẹ R64 2.56 'big, great' (native word)
TT0972 tha R17 2.14 'big, great' (borrowing from Tangut period northwestern Chinese 大 *tha)
Precious Rhymes of the Tangraphic Sea only has a listing for the first reading without any analysis.
The second reading has no entry at all and is presumably reconstructed solely on the basis of Homophones. However, PRTS does list a homophone with the same left side:
TT0969 tha R17 2.14 (transcription tangraphic)
One might expect the left side
TT0962 'cool, cold' (distortion/abbreviation of Tangut period NW Chn 涼 ?*ljo 'cool'?)
to be a phonetic for tha, but in fact it was pronounced ɕu R2 1.2, and no other tangraphs containing it in any position are pronounced tha (or even ta or da).
The only other tangraph with a double reading that I know of is

TT3908 ŋwu R1 2.1 (a surname; not in TRECD)TT3584 tsẽ R41 1.40 'small, little, young'
No analysis of the surname is available, but 'small' was analyzed as a semantic compound:
+
'person' < left of TT5070 zɨɨʳ R100 1.92 'few' +
but why 'person'?
all of TT1730 tsɨ R31 1.30 'small, little; too, also'
Why was this tangraph was also used for a nonhomophonous surname ŋwu R1 2.1? Its right side
seems to be a phonetic for ŋwu R1 2.1 in
TT5339 ŋwu R1 2.1 'vulture' (with 'bird' on the right)
(with the elements of TT3584 'small, little, young' reversed!)
TT5343 ŋwu R1 2.1 (grammatical word; no analysis available; why does it have 'person' on the right?)
which has another reading
TT1748 la R17 1.17 'small, little, petty'
(I follow Precious Rhymes of the Tangraphic Sea and TRECD 2843-2844 in displaying the right side as 'person' rather than 'earth')
with an analysis
+
bottom (right) of TT0873 la R17 2.14 'small, little' (cognate to TT1748 la R17 1.17) +
why is 'wood' on top?
left of TT3584 tsẽ R41 1.40 'small, little, young'
Could the element
have a double origin?
1. It could be a distortion of a sinograph like
吳 Tangut period NW Chn ?*ŋgu or
禺 Tangut period NW Chn ?*ŋgy
that sounded like ŋwu R1 2.1.
2. It could be a distortion of 小 'small' or 少 'few' with added strokes.
08.6.5.23:57: AN ACRONYMIC ANALOGY FOR CONVERGENT COMBINATIONS
Did the Tangut consider
TT4732 kwe R34 1.33 'respectful'
TT4743 ti R11 1.11 'not'
to be one tangraph with two readings or two tangraphs with two different readings?
Each reading has a separate entry in Tangraphic Sea under the appropriate rhyme with a different graphic analysis:
+
TT4732 kwe R34 1.33 'respectful' =
left of TT4731 bu R2 1.2 'crawl; creep' +
right of TT3742 zew R44 2.38 'elbow'
'crawl on one's elbows in deference'?
=
+
TT4743 ti R11 1.11 'not'* =
right of TT2778 tị (< *S-ti-H) R70 2.60 'place' (phonetic) +
left of TT2802 tuọ (< *S-ti-o) R75 1.72 'put' (cognate to TT2778; also phonetic if suffix ignored?)
Do both of these analyses reflect the intentions of the inventor(s) of tangraphy? Or was one (or both) created by the compiler(s) of Tangraphic Sea under the assumption that each reading must have a distinct graphic fanqie as well as a distinct phonetic fanqie?
Are TT4732 and TT4743 like homographic acronyms? The first TBS I had ever heard of stood for Tokyo Broadcasting System. Years later, I got cable TV and learned of another TBS: Turner Broadcasting System. I don't consider both TBSs to be the 'same' word even though they are written identically. So should I consider TT4732 and TT4743 to be different tangraphs that happen to be written identically?
TT4743 ti R11 1.11 'not'
have the semantic element
'not'
which could distinguish it from TT4732 'respectful?
08.6.4.9:34: SHOULD DIGNITY EQUAL BEAUTY?
At first glance, I thought
TT4691 kɨʳw R94 2.79 'curve; crooked'
looked like its homophone
TT4690 kɨʳw R94 2.79 'elbow'
plus an extra
'incline'
on the bottom right, but obviously its second and third elements are completely different:
+
(meaning unknown) + 'person'
not
+
'incline' (Nishida 1966: 244) + 'arm'
Such a mistake is inexcusable. These two elements form the tangraph
TT0153 liuu R7 2.6 'dignified'
which has a near-lookalike
TT1177 ɕuo R53 2.44 'beautiful'
with
(meaning unknown)
on the left.
I'm surprised to discover that in the Unicode Tangut proposal, both
TT0153 and TT1177
have a single codepoint (17CED) with TT0153 as its UCS representative glyph.
The Unicode Tangut proposal also has a single codepoint (17CF0) for
TT0138 ɕia R19 2.16 'happy'
TT1170 khə R28 1.27 'poetry'
Such conflation is understandable given how Li Fanwen (1997) regarded both
as a single radical in his index (6.4.19:52: unlike Nishida, who distinguished them as 220 and 221). Nonetheless, an index specific to a single book was not intended to be the basis for the definitive encoding for Tangut.
I am not against all mergers. For instance, I think it makes sense to assign a single codepoint to tangraphs with double readings: e.g.,
TT4732 kwe R34 1.33 'respectful'
TT4743 ti R11 1.11 'not'
TT0971 liẹ R64 2.56 'big, great' (native word)
TT0972 tha R17 2.14 'big, great' (borrowing from Tangut period northwestern Chinese 大 *tha)
Without transcriptions, one cannot be absolutely certain that one or the other reading was intended. A single codepoint (18650) for the second pair (liẹ/tha) in Unicode is no different from a single codepoint for the sinograph 大 which can be read as Mandarin da or (very rarely) dai, Sino-Korean tE, etc. Unlike Unicode, Mojikyo follows Li Fanwen 1997 and others in treating each tangraph-reading combination as distinct. Hence if I want to find all instances of a double-reading tangraph in a text using a Mojikyo font, I have to search for the codepoints associated with both readings. Unicode avoids that problem, but it prevents me from typing some pairs of non-identical glyphs. The ideal solution should be somewhere in the middle:
| similar but distinct tangraphs: 'dignified' : 'beautiful', 'happy' : 'poetry' | double-reading tangraphs: e.g., 'respectful'/'not' and 'big, great' | |
| Mojikyo | distinct codepoints | distinct codepoints |
| What I favor | a single codepoint | |
| Unicode | a single codepoint |
Han Xiaomang (2004), which I have not seen, also unifies pairs like 'dignified' and 'beautiful'. Are such pairs really interchangeable in texts?
6.4.19:57: There is a precedent within Unicode for preserving multiple legacy codepoints for a single glyph. The CJK Compatibility Ideographs range contains codepoints for alternate Sino-Korean readings, reflecting how the KS C 5601-1987 standard encoded each sinograph-reading combination separately. Such preservation enables round-trip conversion: e.g.,
Round-trip conversion is not possible with Tangut Unicode:六 ryuk: KSC D7BF > Unicode 516D > KSC D7BF
六 yuk: KSC EBBB for > Unicode F9D1 > KSC EBBB
TT0971 > Unicode 18650
TT0972 > Unicode 18650
08.6.3.23:54: WHY ARE ELBOWS DISRESPECTFUL?
In "Nine Elbows", I found that external cognates of
TT4690 kɨʳw R94 2.79 < *r-kəw-H 'elbow'
"point toward a reconstruction of R94 with a labial glide (e.g., Gong's -jiʳw or my -ɨʳw) rather than, say, Li Fanwen 1986's -ạ and -jə̣ or Arakawa's -jeʳ."
If I am right, I would expect the tangraph for 'elbow' to contain a -Vw or -u phonetic. Yet it contains a tangraph with two readings ending in palatal vowels:
TT4732 kwe R34 1.33 'respectful'
(6.4.1:01: superficially similar to Old Chinese 敬 *kreŋs 'respect' but cannot be cognate since kwe cannot be traced back to pre-Tangut *p-kre which would have become kwɛ R35 1.34.)
TT4743 ti R11 1.11 'not'
ti has nothing in common with kɨʳw other than a high vowel and kwe only has a common initial. Hence the former cannot be phonetic and the latter is probably not phonetic. However, kwe isn't too different from what Arakawa might reconstruct for 'elbow': ?kjeʳ. I wonder if there are any other instances of -e tangraphs as phonetics in -Vw tangraphs.
Next: Another disrespectful derivative.
6.4.1:2:45: 'respectful'/'not' consists of two elements
'incline' (Nishida 1966: 244) + 'arm'
Although one might expect such a combination to form a semantic compound for 'elbow' (even though 'incline' is not the expected 'bend'), of course the resulting tangraph means 'respectful' and 'not'. Why does 'elbow' require an additional
on top which has no known function?
So far, I've been interpreting the structure of 'elbow' as A + (B + C). But there are other possibilities: e.g.,
(A + B) + C
(A + C) + B
A + B + C
Since the second volume of the Tangraphic Sea containing the analysis of 'elbow' is lost, I can only guess that (A + B) + C is correct. C is 'arm' which is semantic. A + B may be an abbreviation of
TT4692 (reading unknown; listed in the glottal initial chapter of Homophones; Precious Rhymes of the Tangraphic Sea lists it under the entering tone!)
if it means 'deviant, slanting' (Li Fanwen 1997; still not a good semantic match) rather than 'yawn' (Grinstead 1972 and TRECD 4113).
TT4692 has the very common bottom right element
whose function is unknown. TRECD lists 524 tangraphs (1 out of 12 in the entire script!) with this mysterious element (B256, tangraphs 3711-4234).
This element plus 'incline' equals
TT4761 lhwɨe R36 1.35 'oblique; tilted; slanting' < ?*K(ɯ)-P(ɯ)-la-j
cognate to Old Chinese 邪 *sla 'awry; crooked' (the initial may have been more complex, but the root initial was *l-). ヒ seems to be a filler added to semantic elements that can't stand by themselves (why?).
Adding a line to TT4761 results in
TT4434 sie R37 1.36 'slanting'
probably a loan from Tangut period NW Chinese 斜 ?*sje 'slanted' < OC *sla (but with a newer sinograph).
Its left-hand element
appears on the left of a few more tangraphs (TT4435-TT4438) which do not comprise a coherent semantic or phonetic group:
TT4435 woʳ R95 2.80 'calf'
TT4436 sie R37 2.33 (surname)
TT4437 ʔɨe R36 2.32 (transcription tangraph for Sanskrit e)
TT4438 mɨ R31 2.28 'cheek'
Nishida (1966: 477) did not identify any function for it. Contra Grinstead (1972: 131), it does not appear on the right side of tangraphs in TRECD (element B171, p. 40).
08.6.2.23:59: NINE ELBOWS TO THE RESCUE?
It is somewhat circular and hence dangerous to use external cognates to aid in reconstruction. Nonetheless, at least they are hard data, unlike Chinese reconstructions.
Possible cognates of
TT4690 kɨʳw R94 2.79 < *r-kəw-H 'elbow'
include
Set 1: kr-words (from Starostin)
Written Tibetan khru 'cubit (from elbow to end of middle finger)', gru-mo 'elbow'
Lepcha kjŭ 'a measure of about a span'
Trung kru1-mu1 'arm'Kanauri kru-tś (sic) (no gloss)
Thebor kru 'elbow'
Set 2: k-words (from Starostin except for Old Chinese)
Written Tibetan dgu-ba 'to bend', sgu-stegs 'elbow, angle'
Kachin: ko (H) 'be bent, curved'; dǝgo2 'to fold (as an envelope)'; ku3 'be bent'Lushai kiu 'elbow'
Old Chinese 肘 *t-r-kuʔ 'wrist, elbow'
Sagart (1999: 96-97) proposed root-initial *k- for 'elbow' "on account of the graphic similarity of the early graph for this word with [OC 九 *kuʔ] 'nine'." However, I am not sure whether the phonetic series of 'elbow' should be reconstructed with *k.*
Schuessler (2007: 320) noted that "in [Written Tibetan] 'nine' and 'bend' are also homophones (dgu)."
Set 3: Ambiguous: *k- or *kl-?
Old Chinese 觓, 觩 *(N-)k(l)iw 'long and curved' (see Schuessler 2007: 320 for Sino-Tai loanword evidence suggesting *-l-, though the phonetic 求 *N-ku has no liquid medial)
Still other OC words could be cognate if they share a root *k-w with affixes:
屈 'to bend' *khut < ?*C-kəw-t
絀 'to bend' *t-r-kut < ?*t-r-kəw-t
曲 'to bend' *khok < ?*C-kaw-k
I doubt that Kr- or Kl- words are cognates (unless they contain liquid infixes) because I currently believe that pre-Tangut medial *-r- did not condition retroflexion in Grade III rhymes like R94, and that pre-Tangut *Kl- became lh-, not k- plus retroflexion in the following vowel.
If at least some of these words are cognate to the Tangut word for 'below', they point toward a reconstruction of R94 with a labial glide (e.g., Gong's -jiʳw or my -ɨʳw) rather than, say, Li Fanwen 1986's -ạ and -jə̣ or Arakawa's -jeʳ.
6.3.0:15: -uʳ is not a possible reconstruction of R94, since none of the transcriptions of R94 contain -u. Moreover, several scholars reconstruct R80 as -uʳ, so R94 has to be reconstructed differently.
6.3.0:48: The absence of -Hu in Tibetan transcriptions of -w-type rhymes such as R94 in Gong's rhyme group IX may simply reflect a nonstandard Tangut dialect which had lost all final glides, completing a process that was almost complete in standard Tangut which only retains some instances of earlier *-w:
R94 -ɨʳw (standard)
R94 -ɨʳ (nonstandard; transcribed as -aH or -iH)
Pre-Tangut *-j monophthongized with preceding vowels and pre-Tangut *-w was lost after labial and achromatic vowels: e.g.,
*-aj > -e
*-ow > -o
*-aw > *-aɰ > -a
*08.6.3.2:31: 肘 *t-r-kuʔ 'wrist, elbow' is a member of a phonetic series with retroflex and dental-initial readings in Middle Chinese:
| Karlgren 1957 number | Sinograph | MC | OC (velar) | OC (nonvelar) | Gloss |
| 1073a | 肘 | *ʈuʔ | *t-r-kuʔ | *r-tuʔ | wrist, elbow |
| 1073b | 疛 | intestinal pain (< 'bending'?) | |||
| 1073c | 酎 | ɖuʔ | *N-t-r-kuʔ | *N-(t)-ruʔ | new spirits made to ferment by addition of older spirits |
| 1073d | 討 | *thawʔ | *t-khuʔ | *thuʔ | punish, blame; request; examine; curtail |
If it weren't for the graphic and external evidence, I would see no reason to reconstruct a velar in the OC readings of this series. I have three reasons to favor a nonvelar reconstruction of 1073:
1. It seems unlikely that 'wrist, elbow' would have a homophone 'intestinal pain' with a *t-r- prefix sequence needed to account for the retroflex voiceless stop in MC. (But this is the weakest objection if 'intestinal pain' shares a root 'bend' with 'wrist, elbow'.)
2. There are Tibeto-Burman t/d-words for 'elbow' that could be cognate to 'wrist, elbow' if it were reconstructed as *r-tuʔ.
3. There is a likely nonvelar cognate for 1073c 'new spirits ...': 1069r 醪 *ruʔ 'spirits with sediment' (borrowed into Vietnamese as rượu < *rɨəwʔ 'liquor'). A medial *-t- is unnecessary if OC *N-r- was phonetically [ɳɖr] with a stop which would justify its inclusion in a dental series. This stop would have survived into MC while the consonants around it were lost: OC *ɳɖr- > MC *ɖ-.
are hard to reconcile:
| R93 | R94 | |
| Tibetan transcriptions | rngi(H), ngi ring Hdwi bdhe(H) |
dkaH (6.2.0:21: in Nevsky 1960 I: 222, but Sofronov has dkiH, presumably for the same tangraph or a homophone; དཀའ dkaH and དཀིའ dkiH are identical in Tibetan script apart from the presence or absence of ི i) |
| Middle Chinese reconstructions of rhymes of sinographs used to transcribe Tangut | *-ək (> Tangut period *-ə?), *-u (> Tangut period *-ɨw and *-iw?) | *-əw |
| Middle Chinese grades of sinographs used to transcribe Tangut | I, III | I |
| Kychanov and Sofronov 1963 | -ɘ | (none) |
| Nishida 1964 | -jəʳ | -jʉʳ |
| Hashimoto 1965 | -ɛw | -ew |
| Sofronov 1968 | -ẹɯ | -ə̣ɯ |
| Huang 1983 | -iəu | -ieu |
| Li Fanwen 1986 | -jəə | -ạ and -jə̣ |
| Gong 1997 with his grades | -eʳw (I) | -jiʳw (III) |
| Arakawa 1999 with his grades | -eʳ (I) | -jeʳ (II) |
| This site with my grades | -eʳw (I) | -ɨʳw (III) |
1. Tibetan preinitial r- points to retroflexion in R93. Some presume R94 to be retroflex because it is in the retroflex rhyme cycle
whose Tibetan transcriptions sometimes have preinitial or final r
whose members can be preceded by Tangut r- (unlike all rhymes other than R43 2.37 -iẽ)
2. The Tibetan transcriptions lack a -Hu
that would correspond to the -w-like elements in
most reconstructions and MC *-w.
3. The Tibetan transcription -ིང -ing for R93 may be a misreading of -ིར -ir since the Tibetan letters for ང ng and ར r are similar. No other evidence points to nasality in R93.
4. The MC grades don't match Gong's, Arakawa's, or my Tangut grades. Perhaps I should reverse the grades for my reconstructions of R93 and R94, even though that would violate the general principle of rhymes arranged in ascending grade order:
R93 -ɨʳw (Grade III, corresponding to MC Grades I and III)
R94 -eʳw (Grade I, corresponding to MC Grade I)
5. Tibetan transcriptions lack a -y- corresponding to the reconstruction of *-j- in R93 and R94. Some reconstruct MC *-u with a *-j-, but none reconstruct a *-j- in MC *-ək or *-əw, so there is no Chinese evidence for a *-j- in R94.