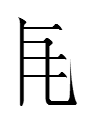
ləəi R12 2.11 nɨaa R21 1.21
08.5.24.22:16: TRECD
is my abbrevation of Tangut-Russian-English-Chinese Dictionary (Kychanov and Arakawa 2006). TRECD is a true dictionary of words rather than just tangraphs. The difference is crucial because words can be more than one tangraph long and are not necessarily the sum of their parts: e.g., the first polysyllabic word in TRECD is
ləəi R12 2.11 nɨaa R21 1.21
TRECD glossed both tangraphs as 'black', but one could not guess that 'black' + 'black' = 'dark brown (lighter than black!); sunburnt; dark-skinned'.
5.25.4:24: Li Fanwen (1997) defined ləəi as 'dark (complexion)', so the compound may be transparent.
ləəi is similar to Middle Chinese 黎 *lej 'black' < Old Chinese *ri. (The phonetic of 黎 is Old Chinese 利 *rits 'sharp' which has external cognates with r- [Schuessler 2007: 351].)
If ləəi is a borrowing from Chinese, it must postdate the shift of *r- to *l-.
In Chinese borrowings, R12 -əəi corresponds to MC *-əj and R37 -ie corresponds to MC *-ej (Gong, "西夏語中的漢語借詞", p. 764). Hence MC *lej should have been borrowed as Tangut lie. I conclude that ləəi and lej are lookalikes.
Perhaps the second polysyllabic word in TRECD is a better example of the whole being more than the sum of its parts:
lo R51 2.42 neʳ R77 1.73
'strainer; skimmer' + 'slippery, oily, lubricous'
(LFW 1997: 'filter' + 'lubricate') =
'glossy, shining' (not 'oily strainer')
08.5.23.23:55: AMBIGRAMS, SYMMETRIGRAMS, INVERSIONS
Ambigrams are an artform I discovered at 莫大伟 David Moser's* cognitive-china.org. I wonder what Tangut-English ambigrams would look like. Ambigrams can even involve a single script and language. More monolingual examples at Ger's Ambigram Gallery.
Could these symmetrical renderings of perception and psychology count as ambigrams? Yes. (Scroll down to the ambigram for geometry.) I could call them symmetrigrams to distinguish them from inversions.
*David Moser is the author of my favorite essay on language learning, "Why Is Chinese So **** Hard".
08.5.22.23:59: AN ASHEN INTERPRETATION OF THE GRADE II -A RHYMES (PART 1)
In "3 x 3" The Tangut Vowel System?", I reconstructed the three grades of Tangut -a as
| Plain | Nasal | Tense | Retroflex | |
| High (Grade III) | ɨɐ(ɐ) | ɨɐ̃ | ɨɐ̣ | ɨɐ(ɐ)ʳ |
| Mid (Grade I) | ɐ(ɐ) | ɐ̃ | ɐ̣ | ɐ(ɐ)ʳ |
| Low (Grade II) | a(a) | ã | (none) | aʳ |
(nasal column added 5.23.0:39)
But you may have noticed that I reconstructed -a rhymes somewhat differently in my last post with æ 'ash' instead of a (and a instead of ɐ before ɨ). Here's the complete set of -a rhymes in my current reconstruction:
| Plain | Nasal | Tense | Retroflex | |
| High palatal (Grade IV) | ia(a) ?[iæ(æ)] | ɨã/iã | ɨạ/iạ | ɨa(a)ʳ/ɨa(a)ʳ |
| High nonpalatal (Grade III) | ɨa(a) ?[ɨɑ(ɑ)] | |||
| Mid (Grade I) | a(a) ?[ɑ(ɑ)] | ã | ạ | a(a)ʳ |
| Low (Grade II) | æ(æ) | æ̃ | (none) | æʳ |
(nasal column added 5.23.0:39)
The Grade III/IV distinction is neutralized for nasal, tense, and retroflex vowels. The exact nature of this neutralization is unclear and requires more investigation.
This scheme is parallel to my reconstruction for Middle Chinese, which lacks the plain/tense/retroflex, oral/nasal, and short/long distinctions of Tangut:
| Plain | |
| High palatal (Grade IV) | ia [iæ] |
| High nonpalatal (Grade III) | ɨa [ɨɑ] |
| Mid (Grade I) | a [ɑ] |
| Low (Grade II) | æ |
My reconstruction of Grade II -a as æ has a single low palatal vowel, whereas Gong's -ia has a diphthong with a palatal first half and Arakawa's -ja has a palatal glide. I prefer not to reconstruct an -i- or a -j- because the only existing Tibetan transcription for a Grade II -a rhyme (-ar) lacks a palatal element:
| Grade | Plain short | Plain long | Nasal | Tense | Retroflex short | Retroflex long |
| IV | R20 -ia: Tib. -a(H), -aH | R24 -iaa: Tib -a | R27 -ɨã/-iã: (no Tib.) | R67 -ɨạ/-ia:̣ Tib. -a(H), -o (!) | R87 -ɨaʳ/-iaʳ: Tib. -a, -ye, -aṭ (for Skt transcription?), -ur (with u!) | R89 -ɨaaʳ/-iaaʳ: (no Tib.) |
| III | R19 -ɨa: Tib. -a(H) | R21 -ɨaa: Tib. -a(H), -aH, -eH, -am (why -m?) | ||||
| I | R17 -a: Tib. -a(H), -aH, -ya (why -y-?) | R22 -aa: (no Tib.) | R25 -ã: Tib. -a, -an, -ang | R66 -ạ: Tib. -a(H) | R85: -aʳ: Tib. -a(H), -aH | R88 -aaʳ: (no Tib.) |
| II | R18 -æ: (no Tib.) | R23 -ææ: Tib. -ar (why -r?) | R26 -æ̃ (no Tib.) | (none) | R86: -æʳ: (no Tib.) | (none) |
But then why reconstruct a palatal vowel for Grade II -a at all? Is an assumed parallelism with Middle Chinese my only motivation? I'll explain why it isn't in part 2.
5.23.1:23: -ar is probably not an error for -yar or -ir, because other Tibetan transcriptions of non-i/ɨ Grade II rhymes lack -y- and -i with only one or two exceptions (R35 and perhaps R42):
| Rhyme | Tibetan transcription | Gong | This site |
| 9 | -i(H) | -ie | -ɪ |
| 13 | -i, -u (sic) | -iee | -ɪɪ |
| 29 | -i | -iə | -ʌɨ |
| 35 | -e; one case of -i (error for the similar-looking letter -e?) | -iej | -ɛ |
| 39 | -e | -ieej | -ɛɛ |
| 42 | -e in the only extant example ñe, which could be analyzed as n- + -ye | -iəj | -ɛ̃ |
| 52 | -oH, -uH, -a (sic) | -io | -ɔ |
| 55 | -o(H) | -ioo | -ɔɔ |
| 57 | -o(H), -ong | -iow | -ɔ̃ |
| 59 | -o, -ou (sic), -u(H) | -ioow | -ɔ̃ɔ |
| 63 | -e(H) | -iẹj | -ɛ̣ |
| 69 | -i, -e, -a (sic) | -iẹ | -ɪ̣ |
| 74 | -o | -iọ | -ɔ̣ |
(It's uncertain whether there were any Grade II -u rhymes.)
08.5.21.23:56: DID TANGUT GRADE II COME FROM *CR-CLUSTERS? (PART 2)
Although the very limited comparative data in part 1 indicated that Tangut Grade II may have originated from medial *-r- followed by a nonhigh series vowel, Guillaume Jacques' 2006 comparisons between Tangut and gDong-brgyad rGyalrong reveal a much more complex picture:
Tangut Grade II : gDong-brgyad rGyalrong -r-
| Gloss | Gong | This site | gDong-brgyad rGyalrong |
| plowshare | khia | khæ | qraʁ |
| bring down | tɕia | tɕæ | kɤ tʂaβ 'make a tree fall' < Proto-rGyalrong *thr- |
| willow | biə, biẹ | bʌ, bɪ̣ | qa-ʑmbri |
| snake | phio | phɔ | qa-pri |
| horn | khiwə | khwʌ | ta-ʁrɯ |
| white | phiow | phɔ̃ | ku-ɣrum |
Tangut Grade II : gDong-brgyad rGyalrong zero medial
| Gloss | Gong | This site | gDong-brgyad rGyalrong |
| difficult | gie | gɪ | kɯ-ɴqa |
| forearm | kiwej | kwɛ | tɯ-ʁla |
| cook | ɣiẹ | ɣɪ̣ | kɤ-sqa |
| frog | piẹ | pɪ̣ | qa-ɕpa |
| right | tɕieʳ | tɕɪʳ | χcha |
| gnaw | kieʳ | kɪʳ | kɤ-nɤ-ŋka |
| scold | kiej | kɛ | kɤ-nɯ-mqe |
| fart | wiəj | wɛ̃ | tɯ-phe (gSar-dzong dialect) |
| take | tɕhiə | tɕhʌ | kɤ-tɕɤt |
| ear of a plant | niọ | nɔ̣ | kɯ-ɕnom |
| mud | tɕioʳ | tɕɔʳ | tɤ-rcoʁ |
Tangut Grade I : gDong-brgyad rGyalrong medial -r-
| Gloss | Gong | This site | gDong-brgyad rGyalrong |
| body | kwəʳ | kwəʳ | tɯ skhrɯ |
Tangut Grade III (incl. my IV) : gDong-brgyad rGyalrong medial -r-
| Gloss | Gong | This site | gDong-brgyad rGyalrong |
| order | phji | phi | kɤ-ɣɤ-xpra 'send on a mission' |
| otter | ɕjow | ɕuõ | tɕhɯ-ɕrɤm (borrowed from Tibetan chu sram) |
| rope | bji | bi | tɯ-mbri |
| clear | gjii | gii | kɯ-mgri |
| bear | rjɨj | rẽ | pri |
| constellation | gjịj, gjɨ̣ 'star' | giẹ, gɨ 'star'̣ | ʑŋgri 'star' |
| long | zjiʳ | ziʳ | kɯ-zri < Proto-rGyalrong *sr- |
| elbow | kjiʳw | kiʳw | tɯ-zgrɯ |
| louse | ɕjiw | ɕɨw | zrɯɣ |
| gallbladder | kjɨɨʳ | kɨɨʳ | tɯ-ɕkrɯt |
| high | bjɨ, bjij | bɨ, bie | mbro |
| pigeon | khjij | khie | qro |
| horse | rjiʳj, rajʳ | rieʳ, rɨaʳ | mbro |
| ant | kjiʳw | kiʳw | qro |
| welcome | khjuu | khuu | kɤ-qru |
These correspondences can be grouped into patterns:
| Pattern | Tangut grade | Tangut rhyme type | gDong-brgyad rGyalrong |
| 1a | II | plain | -r- |
| 1b | tense | ||
| 2a | plain | -Ø- | |
| 2b | tense | ||
| 2c | retroflex | ||
| 3 | I | -r- | |
| 4a | III/IV | plain (after initials other than k-, z-) | |
| 4b | retroflex (after k-, z-) |
Notes:
1. Why is there no pattern 1c with retroflex rhymes? Is this
because *-r- left no trace other than conditioning
Grade II (vowel lowering in my reconstruction)?
2. Conversely, why is there Tangut retroflexion in pattern 2c that corresponds to no -r- in gDong-brgyad rGyalrong? Does this retroflexion originate from a rhotic affix present in pre-Tangut but absent in gDong-brgyad rGyalrong?
3. Do patterns 2a-2c involve something other than *-r- that conditioned Grade II? Schuessler has proposed that some Grade II *æ in Middle Chinese come from Old Chinese *a rather than *ra: e.g.,
Middle Chinese 怕 *phæh 'fear' < Old Chinese *pas (rather than *rpas).
(MC 怖 *poh 'fear' is the regular reflex of OC *pas.)
Could Tangut also have preserved original low vowels in some words?
4. There seem to be no Grade II syllables in Gong's Tangut reconstruction with initial r-. This is reminiscent of how MC *l- < OC *r- is rare in MC Grade II. (Initial r- can precede Grade II rhymes in Arakawa's Tangut reconstruction. The negative correlation between r- and Gong's Grade II is a point in favor of Gong's grade system.)
5. Pattern 3 only occurs once. The retroflexion in Tangut and the -r- in gDong-brgyad rGyalrong may be innovations because there is no -r- in Written Tibetan sku 'body' or Written Burmese kuiy 'animal body'. I reconstruct pre-Tangut *r-kwə.
6. Why does pattern 4b only occur with the Tangut initials k- (but not kh-) and z-, which have nothing in common beyond being obstruents? This k-/z- pattern is reminiscent of how only kh- and ʑ- appear before R6 (Gong's -juu and my -uu). I presume that these pairs of initials (k-/z- and kh-/ʑ-) had a phonetic common denominator in pre-Tangut.
5.22.1:44: Perhaps *SCr-clusters developed retroflexion in Grade III/IV -
*SkrV > kVʳ ('elbow', 'gallbladder')
*SqrV > kVʳ ('ant')
*SrV > zVʳ ('long')
(ɕuõ 'otter' could be a loan from Tibetan sram dating after the shift of *SrV to zVʳ.)
(Did *S- become *ʂ- before *-r-? Did *-kr- and *-qr- metathesize after *S-, becoming *rC-clusters that conditioned retroflexion of the following vowel?)
- whereas *Cr-clusters did not:
*grV > gV ('clear')
*q(h)rV > khV ('pigeon', 'welcome')
The words for 'constellation' and 'star' have g- + tense vowel (< *S-) corresponding to gDong-brgyad rGyalrong ʑŋgr-. I would expect *SgrV to have undergone changes similar to *skrV above:
*SgrV > gVʳ (instead of gṾ!)
Perhaps the pre-Tangut initial of those words was *Sŋgr-:
*SŋgrV > *SŋgV > *SgV > *SgṾ > gṾ
08.5.20.23:59: DID TANGUT GRADE II COME FROM *CR-CLUSTERS? (PART 1)
In Gong Hwang-cherng's 2007 article, "The Position of Tangut in the Comparative Study of Sino-Tibetan Languages", Tangut Grade II (which he reconstructed as -i-) corresponds to medial -r- in other languages:
| Gong's comparison number | Gloss | Gong | This site | Written Tibetan | Written Burmese | Old Chinese |
| 6 | horn | khiwə | khwʌ | khrui | 角 *krok | |
| 14 | drive | kio | kɔ | dkrug 'stir' | 覺 *kruk 'awake' | |
| 35 | untie | bɛ | pre | |||
| 36 | bitter | khie | khɛ | mkhris-pa 'bile, gall' | sañ-khre 'gall' |
But in four cases, Gong's Tangut Grade III (which he reconstructed as -j-) corresponds to medial -r- in other languages:
| Gong's comparison number | Gloss | Gong | This site | Written Tibetan | Written Burmese | Old Chinese |
| 16 | six | tɕhjiw | tɕhiw | drug | khrok | 六 ruk |
| 37 | leg, foot | khjɨ | khɨ | khri 'seat' | khre | 几 krəjʔ 'stool, table' |
| 38 | ten thousand | khjɨ | khɨ | khri | ||
| 65 | tail | mjiij | meej | mriih | 尾 məjʔ |
I was initially tempted to propose that Tangut and Chinese had undergone parallel sound changes:
Pre-Tangut *-r- + nonhigh series vowel > Tangut Grade II (low series)
e.g., 14: *-ro > -ɔ
Old Chinese *r-, *-r- + emphatic vowel > Middle Chinese Grade II (low series)
e.g., 14: OC *-ruk > MC *-ɔk
Pre-Tangut *-r- + high series vowel > Tangut Grade II (low series)
e.g., 16: *-ru > -iw
Old Chinese *r-, *-r- + nonemphatic vowel > Middle Chinese Grade III (high series)
e.g., 16: OC *-ruk > MC *-uk
Pre-Tangut *r- rhotacized the following vowel: e.g.,
Pre-Tangut *r-Ce > Tangut Ceʳ (not Cɛ)
but
Pre-Tangut *Cre > Tangut Cɛ
OC *r-Ce and *Cre > Middle Chinese *Cɛ
Pre-Tangut *-r was another source of retroflexion: e.g.,
Pre-Tangut *Cer > Tangut Ceʳ (not Cɛ)
but
OC *Cer > Middle Chinese *Cien or *Ciej
Notes on individual comparisons:
6: Sagart (1999: 161) analyzed OC *krok 'horn' as concrete count noun prefix *k- + *rok 'deer'. If this analysis is correct, perhaps *k-rok and the *khrəw implied by Written Burmese khrui are lookalikes with different root initials (*r- and *kr-) and nonmatching codas (*-k and zero).
14: 'drive' is not an optimal semantic match for 'awake'. Tangut khɔ may be a loanword from an unattested Late Old Chinese variant *khɔ(h) < *r-kho(s) of Old Chinese 驅 *kho(s). Tibetan cognates of OC *kho(s) have no -r-: e.g, Hkhyug-pa 'to run', Hkhyu-ba 'to run', dkyu-ba 'to run' (Schuessler 2007: 435).
16: The root initial of 'six' is *r-, but in pre-Tangut, 'six' had an initial cluster *k-t-r- that became the aspirated affricate tɕh-.
35: Schuessler (2007: 313) linked pr-words for 'untie' to OC 解 *kreʔ, in spite of the nonmatching initials. Perhaps the Proto-Sino-Tibetan root had initial *r-, and in pre-Tangut, *p-r- fused to *pr- and was treated as a cluster.
36: I wonder if this word is cognate to Written Tibetan kha and OC 苦 *khaʔ 'bitter'.
38: Could the Tangut form be a borrowing from Tibetan? I don't know of any cognates outside Tangut and Tibetan, suggesting that the word was a Tibetan innovation.
(5.21.0:09: Starostin suggested that OC 皆 *kri 'all' and OC 師 *sri 'multitude' are cognate. If the latter is cognate, then the root initial was *r-.)
65: The root initial of 'tail' was probably *m-. Burmese mr- is from an earlier *r-m- with an *r-prefix absent in pre-Tangut. (Such a prefix would have rhotacized the following vowel: *r-meej > meeʳj.) It's not possible to determine whether the Chinese form had an *r-prefix or not, since Middle Chinese *mujʔ could be from either *r-məjʔ or *məjʔ. I have opted for the simpler reconstruction.
Next: Does rGyalrong comparison support the *Cr-cluster hypothesis?
08.5.19.23:59: LI FANWEN'S RADICAL 117
appeared in two tangraphs that I mentioned in "Is Eight the Lightest Number?":
TT1648 bi R11 1.11 'light, ray'
TT5640 nɨɨ R33 1.32 'bask (in the sun); shine upon (of the sun)'
Could it mean 'light'? It has an extremely slight resemblance to Chinese 光 'light' but that's an extremely weak argument since it even more strongly resembles Chinese 女 'woman'.
Radical 117 is rarer on the left than on the right. This Excel file contains 12 tangraphs with left-hand 117 (from Andrew West's electronic index to Li Fanwen 1997) and 42 tangraphs with right-hand 117 (from Grinstead 1972: 136-137; tangraphs without TT numbers have been omitted).
These 56 tangraphs can be grouped into 12 phonetic categories (using Gong's reconstruction; the groupings would be identical in mine):
I.1. ba, bia, ?bə, ʔwa
I.2. bji, bjĩ (conflatable with I.3?)
I.3. me, mee, meʳ
III.1. du
III.2. njɨ, njii, ?djij
?III/VI.3. deew, tseew (initials too different?)
V.1. gjwɨ, kjọ, kjụ, kjuʳ, ɣjɨʳ, ɣuʳ, ŋwu
VI/VII.1 dze, tɕiwe, tɕjɨ̣
VI/VII.2. su, dzjuu, dzjwɨ, tɕhjiw, tɕhju
IX.1. lə, ?lhã
IX.2. lhjuu, ljo, lju
IX.3. reʳ, rjijʳ, zeʳ
Roman numerals refer to Homophones chapters.
Is it really possible for 117 to have 12 different phonetic functions?
Four readings cannot be assigned to a phonetic category:
khjaa, lwəj, pjụ, saaʳ
117 is an abbreviation of
'light, ray' in lwəj 'leap' (why?)
'light, ray' in pjụ 'power, might' (why?); its left side pjụ is phonetic
'fill' in saaʳ 'irrigate' (i.e., 'fill with water'?)
Its function in khjaa 'twine, wind' is unknown since no analysis of that rising tone tangraph is available.
5.20.0:45: 117 is an abbreviation of khjaa 'twine, wind' in tɕjɨ̣ '(a)round'. Since both words have 'circular' meanings, 117 must be semantic in '(a)round'.
08.5.18.22:54: IS EIGHT THE LIGHTEST NUMBER?
(Thanks to Andrew West for creating a Tangut radical font and for creating an electronic index to Li Fanwen's Xia-Han zidian!)
It's been a long time since I looked at any graphic analyses of Tangut characters. All three tangraphs in the previous post have interesting components, so I'll be examining each of them over the next few posts.
TT1648 bi R11 1.11 'light, ray'
looks like a combination of
+
TT1632 jaʳ R87 1.82 'eight' + Li Fanwen 1997's radical 117 (meaning unknown)
What does 'eight' have to do with 'light'? bi and jaʳ are not homophonous, so 'eight' does not seem to be phonetic.
Tangraphic Sea implies that 'eight' is an abbreviation of 'radiance':
=
+
TT1648 bi R11 1.11 'light, ray' =
'eight' = left of TT1638 riẽ R43 2.37 'radiance' +
? = left of TT5640 nɨɨ R33 1.32 'bask (in the sun); shine upon (of the sun)'
the mirror image of 'light'!
but that just begs the question: what is 'eight' doing in 'radiance'? Could it be phonetic? jaʳ 'eight' is from an earlier *rja which is not unlike riẽ 'radiance'. However, were the creator(s) of tangraphy aware of the earlier *r- initial of 'eight'? Unfortunately, the analysis of 'radiance' is presumably in the missing second volume of Tangraphic Sea, so I cannot confirm whether 'eight' in 'radiance' actually is 'eight' or just an abbreviation of some other tangraph containing 'eight'.
The right side of
TT1638 riẽ R43 2.37 'radiance'
is Li Fanwen 1997's radical 012 (meaning unknown):
Beneath its ソ is an element (LFW 1997 radical 092) that Kychanov (in Grinstead 1972: 15) identified as 'light'
which can be easily confused with
TT0037 gɨ R31 2.28 'night' (identical to 'light' except for two strokes beneath the 二).
TT5640 nɨɨ R33 1.32 'bask (in the sun); shine upon (of the sun)'
cognate to Written Tibetan nyi 'sun', with a vowel depalatalized to ɨɨ by some lost antipalatal prefix (like 'low'?)
the source of the right side of 'light', also contains 'eight'. Its Tangraphic Sea analysis is
=
TT5640 nɨɨ R33 1.32 'bask (in the sun); shine upon (of the sun)' =
? = right of TT1648 bi R11 1.11 'light, ray' +
the mirror image of 'bask'!
'eight' = right of TT3565 thuoo R55 1.53 'beautiful, wonderful'
'Beautiful' looks like 'person' + 'eight':
=
+
but its Tangraphic Sea analysis only implies 'person' and 'eight' as components of other tangraphs:
+
TT3565 thuoo R55 1.53 'beautiful, wonderful' =
'person' = right of TT1177 ɕuo R53 2.44 'beautiful' +
'eight' = center of TT3567 məi R8 2.7 'shine'
looks like 'person' + 'light'
or a blend of TT3565 and 'light'
Both TT1177 and 'shine' have no known analyses.
TT1632 jaʳ R87 1.82 'eight'
seems to be associated with light and beauty. Is this association also found in Tangut culture? Here are the glosses of all tangraphs with 'eight' on the left side (LFW radical 264):
| Li Fanwen 1997 number | Li Fanwen 1997 gloss |
| 4515 | void, emptiness |
| 4522 | alarm, terrify |
| 4562 | (surname zəʳ) |
| 4570 | scheme, stratagem |
| 4573 | light; ray |
| 4574 | he; it |
| 4575 | ashamed, abashed |
| 4587 | contribution |
| 4588 | (place name dwã) |
| 4590 | (surname ʔɔ̃ɔ) |
| 4607 | dew |
| 4626 | knit |
| 4640 | many; much |
| 4641 | hide |
| 4645 | radiance |
| 4646 | deceive |
| 4655 | (phonetic symbol for bja) |
Here is a list of all tangraphs with 'eight' on the right side:
| Li Fanwen 1997 number | Li Fanwen 1997 gloss |
| 0106 | millet; paddy |
| 1051 | crawl |
| 1256 | clever wife |
| 1257 | eight (Grinstead: 'eighth son') |
| 3226 | bask (in the sun); shine upon (of the sun) |
| 3227 | bask |
| 3228 | beautiful, wonderful |
| 4293 | west (loanword from Chinese 西?) |
| 4759 | night, evening |
Only one of the above tangraphs is homophonous with 'eight': LFW1257 'eight(h son)'.
Most of these 'eight' tangraphs have meanings that have no obvious connection to light, beauty, or eight.
Names containing 'eight' may refer to clans and/or places associated with light, beauty, or eight. (A tangraph for Paris, the 'City of Light', might contain 'eight'.)
'Eight' may be semantic in
LFW4640/TT1640 dwa R17 2.14 'many; much'
The function of the right side (ソ+刂; LFW radical 070) is unknown.
One might expect 'night' to be written as 'no light', but its tangraph seems to be an approximation of Chinese 夜 'night':
LFW4759/TT1843 ŋa R17 2.14 'night, evening'
jaʳ 'eight' is cryptophonetic since it sounds like Tangut period northwestern Chinese ?*je < Middle Chinese *jæh 'night'. It also vaguely resembles the bottom right of 夜.
Strangely, the 'person' at the bottom left of 夜 corresponds to a vertical line (LFW radical 003) rather than the tangraph for 'person'.
5.18.23:34: It just occurred to me that
TT1632 jaʳ R87 1.82 'eight'
vaguely resembles Chinese 日 'sun'. Is that why it was used as a semantic element for 'light'?
Why weren't two other 日-like elements chosen instead?
Perhaps these elements were avoided because they are extremely rare. They only occur in two out of three variant tangraphs for sa R17 1.17 'swell, choke':
LFW4578 (no TT)
TT1245
LFW2572 (no TT)
On the other hand, one could argue that recycling these rare elements for a high-frequency semantic function would have made more sense than using 'eight'.
08.5.18.19:36: MEDIAL -R- IN TIBETAN TRANSCRIPTIONS OF TANGUT
Nevsky (1926) listed three Tibetan transcriptions with medial -r-:
TT1648 bi R11 1.11 'light, ray': Tib. tr. dbri, HbhiH (#247), mentioned in my last post
TT4730 dii R14 2.12 'change, vary': Tib. tr. Hrtri (#201)
Probably not borrowed from Middle Chinese 替 *thejh 'replace'.
d ~ th alternation is common in Tangut, but in such cases, th- is probably derived from d- via prefixation (e.g., *K-d- > th-); if there were a voicing prefix, one would expect both t ~ d and th ~ d alternations, but Gong has only found the latter,
(5.18.22:36: If TT4293 si 'west' is a loanword from Tangut period northwestern Chinese 西 ?*si < Middle Chinese *sej 'west', then it wouldn't be surprising if -ii in 'change' corresponded to MC *-ej.)
The semantic match is inexact.
TT0731 lụ R62 1.59 'float, drift, flow': Tib tr. bldra (#81)
Borrowed from Middle Chinese 流 *lu 'flow' with a Tangut prefix added that conditioned vowel tensing?
There may be other -r-transcriptions in Nevsky (1960) that I have not found yet.
Two of the initial clusters (Hrtr- and bldr-) do not occur in Tibetan, so I presume they are either errors or attempts to write Tangut sounds absent from Tibetan.
None of the transcribed words have retroflex vowels in standard Tangut. Could these transcriptions reflect retroflex vowels in a nonstandard dialect?
| Standard | Pre-Tangut (standard) | Nonstandard | Pre-Tangut (nonstandard) | Transcriptions |
| bi | *bi | ?t-bɦiʳ, ?m-bɦi | *t-r-bi, *m-(?r-)bi | dbri, HbhiH |
| dii | *n-tii | ?n-tiiʳ | *n-r-tii | Hrtri |
| lụ | *s-lu | ?p-t-luʳ | *p-t-r-lu | bldra |
I don't think -r- indicates retroflexion derived from root-internal *r, because I would expect such an *r to condition retroflex vowels and/or Grade II in standard Tangut. (I'll examine a possible connection between root-medial *-r- and Grade II in an upcoming post.) Thus I assume -r- indicates retroflexion derived from an *r-prefix in the nonstandard dialect absent from cognates in the standard dialect.
Conversely, a *r-prefix in the ancestor of standard Tangut could correspond to no prefix in the transcribed nonstandard dialect. This may explain why r is absent from some transcriptions of words with retroflex vowels in standard Tangut: e.g., 'four':
standard Tangut lɨɨʳ R100 1.92 < *r-lɨɨ
transcribed nonstandard Tangut ldiH, lda, zlaH, lha (< *tɯ-ləə, *sɯ-ləə, *kɯ-ləə?; Nevsky 1926 #93)
(5.18.19:43: rl- is a permissible cluster in Tibetan orthography, so transcriptions like rli would be theoretically possible. Their absence implies the lack of retroflexion in 'four' in nonstandard Tangut.)
Could the i ~ a alternation in the transcriptions represent a diphthong with high and nonhigh components: e.g., ɨə?
External cognates have no *r: e.g., Written Tibetan bzhi < *p-lji, Written Burmese leh, Old Chinese *s-hlit-s. Hence the retroflexion in Tangut must be from an affix.
The final -H in HbhiH could indicate that the Tangut vowel was not a simple [i]: e.g., it could have been retroflex [iʳ].
The derivation of d- from *n-t- is phonetically plausible and matches the H...t- sequence in the transcription of 'change' but I know of no other evidence for prenasalized voiceless obstruents becoming voiced. (In Classical Tibetan, the letter H- represents prenasalization.)
The vowel of bldra is unexpected. Perhaps an u was accidentally omitted or lost due to manuscript damage. (a is the default vowel if no other vowel symbol is added.)
Sofronov's reconstruction of 'float' (ldjwụ) includes an ld- absent from Gong's reconstruction lụ. Sofronov's standard Tangut -w- could reflect a labial prefix *p- still preserved in the nonstandard transcribed dialect. However, the fanqie final speller for 'float', TT4516 (Sofronov: tsjwụ, Gong: tsjụ, my tsụ) has a fanqie final speller without -w-, TT4918 (Sofronov: ndju, Gong: dju, my du - all R3 with a lax vowel!).
If 'float' is a borrowing from Chinese, then l must be the root consonant, and the -dr- in the transcription must reflect a stop prefix (my t-) preceding l and retroflexion from another prefix (*r-). The order of these prefixes is uncertain: *p-r-t-lu is also possible. The sequence -ld- (also used to write Tibetan) could be a Tibetanizing graphic metathesis to avoid the un-Tibetan cluster -dl-. It's also possible that the transcribed dialect had metathesized *t-l- to -ld-. (Cf. how Proto-rGyalrong *tl- became ld- in Zbu [Jacques 2004: 316].)
I assume that Tangut prefixes were voiceless and were written as voiced to conform with Tibetan orthographic conventions, but they could have been voiced and even lenited: e.g., p-t-luʳ could have been [βðluʳ]. (Cf. the lenition of *p- to β- in Japhug consonant clusters [Jacques 2004: 331].)
08.5.18.5:03: HIGH AND LOW TIBETAN TRANSCRIPTIONS
I remembered that the Tibetan transcription of TT1309 bie R37 2.33 'high' contained bh, so I hoped that the transcriptions for 'low' words would contain b. That might justify reconstructing two very different pre-Tangut roots *bi 'low' and *bhə 'high' whose derivatives partly merged (bɨ R31 1.30 'low' and 'high'!). However, bh is in the transcriptions of both the 'low' and 'high' word families, and b is only in one transcription of a 'low' word:
(# = Nevsky 1926 tangraph numbers; I/II = volumes of Nevsky 1960)
TT3592 bi R11 1.11 'low': HbHi (sic; should this be Hbhi?; II: 72)
TT3591 bi R11 2.10 'low': Hbhi, dbhi, HbiH (#125 and II: 72)
TT5019 bị R70 1.67 'to lower': no transcription known
TT0501 bɨ R31 1.30 'low': dbhi (I: 573; why is this transcription written in a box twice, once with a partly formed question mark?)
TT0494 bɨ R31 1.30 'high': dbhi 'high' (I: 569; both the reconstructions and transcriptions for 'low' and 'high' are identical!)
TT1309 bie R37 2.33 'high': HbheH (#213), Hbhe (II: 354)
TT1232 biẹ R64 1.61 'to heighten': no transcription known; Sofronov (1968 II: 39) listed Hbe as a transcription of some tangraph(s?) in its homophone group
The functions of H-, d-, -h-, and -H are unclear.
H- could represent prenasalization (though Gong strongly opposed reconstructing mb- in these words) or indicate that the following b(h) was to be read in some unusual way (e.g., as a fricative? with preglottalization? implosion?).
Arakawa (1999) proposed that transcriptive 'preinitials' such as d- were really indicators of the level tone, but note that both H- and d- occur in transcriptions of rising tone words (TT3591 and TT1309).
bh (b with subscript h) is normally used in Tibetan to transcribe Sanskrit bh. Therefore bh might represent a [bɦ] in the transcribed dialect which merged with b in the standard dialect recorded in Tangraphic Sea. One might think that bh represented a lenited b after preinitials, but b without h also occurs after preinitials: e.g., HbiH 'low'. The following table lists the number of transcriptions from Nevsky 1926 containing b(h)- with various preinitials:
|
Ø- |
d- |
H- |
|
|
b- |
4 |
5 |
6 |
|
bh- |
2 |
4 |
2 |
(I have left out one instance of dbr-. Medial -r- is only in three transcriptions in Nevsky 1926.)
bh- appears to be about half as common as b-. However, true frequency is impossible to determine without examining the transcribed texts themselves since Nevsky does not indicate how many times each transcription is used: e.g., TT3591 bi R11 2.10 'low' could have been transcribed with bh- more frequently than with b-, or vice versa.
bh was used to transcribe tangraphs pronounced with both tones, so it cannot reflect breathiness associated with one or the other tone. It could, however, represent subphonemic breathiness associated with /b/.
-H could signify that the preceding vowel was not pronounced as in Tibetan, but
- it occurs when it is not expected: e.g., why was Tangut -i transcribed as -iH?
- it does not occur when it is expected: e.g., why was Tangut -ɨ transcribed as -i?
The latter is understandable since a speaker of a language without ɨ could mishear ɨ as i, but it is harder to understand why a familiar rhyme (-i) was transcribed in an exotic way (-iH) unless the transcriber was 'trying too hard' and hearing nonexistent exotica.
*-j suffixation in Tangut may not have been limited to the formation of optative suffixes. In "Phonological Alternations in Tangut" (1988), Gong Hwang-cherng found that R37 alternated with R11 and R31:
| R11 | R31 | R37 | |
| Sofronov (used by Gong 1988) | -i | -ɪ | -ɪ̃ |
| Gong (2003) | -ji | -jɨ | -jij |
| This site | -i | -ɨ < *-ɯ-ə | -ie < *-ɯ-ə-j |
Tangut has several words for 'high' and 'low' belonging to these three rhymes. The two words in bold are homophones (not only in my reconstruction below but in any reconstruction):
bi R11 1.11 'low' < *bi
bi R11 2.10 'low' < *bi-H
bị R70 1.67 'to lower' < *s(ɯ)-bi
bɨ R31 1.30 'low' < *Cɯ-bə or *C-bi
bɨ R31 1.30 'high' (!) < *Cɯ-bə
bie R37 2.33 'high' < *Cɯ-bə-j-H
biẹ R64 1.61 'to heighten' < *sɯ-bə-j
(5.18.3:24: Added causative verbs.)
I suspect that the homophonous words for 'low' and 'high' were not homophonous in pre-Tangut:
A. They may have had presyllables with different initials:
bɨ R31 1.30 'low' < *C1ɯ-bə
bɨ R31 1.30 'high' < *C2ɯ-bə
In this scenario, R11-R31 alternation involved *i ~ *ə ablaut.
B. The R11-R31 alternation may have involved a antipalatal (grave? velar? uvular?) consonantal prefix that conditioned the depalatalization of *i. 'Low' had this prefix whereas 'high' had a presyllable:
bɨ R31 1.30 'low' < *C-bi
bɨ R31 1.30 'high' < *Cɯ-bə
5.18.3.30: I prefer this solution since it allows me to reconstruct a single root vowel for each word family (*i for 'low' and *ə for 'high').
In any case, the *-j and *-H suffixed version of 'high' that became bie R37 2.33 may have developed to avoid homophony with 'low'.
This bie appears in the name of the Tangut state:
phɔ̃ bie lhiẹ liẹ (or thạ)
'white high state great'
'The Great State of the White and High'
(The last tangraph has two readings. thạ is borrowed from Tangut period northwestern Chinese 大 *tha [though the tense vowel implies a Tangut prefix]. I assume that the native reading liẹ was used in the name of the state.)
In part 2 of my comments on Gong's 2007 paper, I derived Tangut -e from *-aj as well as *-e. Tangut optative prefixes could derive from perfective (originally directional) prefixes plus a suffix *-j. The following table is adapted from Gong (2003; yet another gift from Mahadaatṛ - thanks!):
| Pair number | Directional gloss | Directional/ perfective |
Optative | ||||
| Gong | This site | Pre-Tangut | Gong | This site | Pre-Tangut | ||
| 1 | upward | ʔja* | ʔa1 | ʔa | ʔjij1 | ʔie1 | Cɯ-ʔa-j |
| 2 | downward | nja1 | nɨa1 | Cɯ-na | njij2 | nie2 | Cɯ-na-j-H |
| 3 | here, inside | kjɨ1 | kɨ1 | Cɯ-kə | kjij1 | kie1 | Cɯ-kə-j |
| 4 | there, outside | wjɨ2 | wɨ2 | Cɯ-wəH | wjij2 | wie2 | Cɯ-wəH-j |
| 5 | towards the speaker | djɨ2 | dɨ2 | Cɯ-dəH | djij2 | die2 | Cɯ-dəH-j |
| 6 | away from the speaker | dja2 | dɨa2 | Cɯ-daH | Cɯ-daH-j | ||
| 7 | (direction not found) | rjɨʳ2 | rɨʳ2 | Cɯ-rəH | rjij2 | rieʳ2 | Cɯ-rəH-j |
According to Gong, the optative prefixes "are derived ... by changing the finals into -jij." Gong cannot use *-j suffixation because his *-jɨ + *-j should become -jɨj, not -jij. There is no -jɨj in my reconstruction, and I derive my -ɨ (= Gong's -jɨ) from a raised *ə, so I think *-ə-j and *-a-j merged into *-e (raised to -ie by a preceding *ɯ). A similar merger can be seen in Korean: some speakers have a single reflex e of Middle Korean ㅔ əj and ㅐ aj.
My pre-Tangut reconstructions have two problems:
1. It is unlikely that prefixes had presyllables, yet I need presyllables to account for the raised vowels in all but one prefix (ʔa). Perhaps I should assume that all vowels raised unless there were blocking factors (e.g., a uvular initial or a nonhigh vowel in a presyllable conditioning vowel lowering). Default raising would allow me to reconstruct monosyllabic prefixes (e.g., *ʔa-j) except for ʔa, which would have to come from something like *Cɤ-ʔa (unlikely) or be an archaism that retained its low vowel (much more likely).
2. I need to posit a rule of metathesis that changes *-H-j to *-jH. But such a rule may not be necessary if *-j-suffixation postdated tonogenesis or registrogenesis: i.e., if *-j were added to vowels with rising tones and/or nonmodal (creaky? breathy?) voice:
Cɯ-da2-j > die2or
Cɯ-da̤-j > die2
The optative prefix nie2 is the only suffix whose tone does not match its directional/perfective counterpart. Perhaps its tone was changed (or an *-H was added) by analogy with the majority of optative prefixes which have the rising tone from an earlier *-H. (Would and kie1, the only level tone optative prefixes, eventually have become kie2?)
I assume that *-H was part of the roots of prefix sets 4-7, but it may be a suffix if they have level tone cognates.
*I am puzzled by Gong's -j- in
ʔja (tone unknown to Gong)
since
1. Gong reconstructed this tangraph's reading as ʔa (tone unknown) in Li Fanwen 1997; did he later change his mind?
2. This tangraph was transcribed with Chinese 阿 *ʔa which did not have any initial or medial *j
3. This tangraph was transcribed as a (not ya) in Tibetan (see Nevsky [1926: 21], #78)
4. This tangraph was used to transcribe Indic a (see Nevsky [1960 I: 390])
5. This tangraph was also used to write a Tangut word for 'one' presumably cognate to a 'one' in Qiang varieties