TT5233 HORSE ryiry 1.74
07.4.7.16:41: OH DEER (PART 6): 乭 TOL TALES
In part 5, I defined tangraphic 'tails' as elements which
- always appear on the right of a tangraph
- apparently have no graphic variants in other positions
i.e., are never cited as sources for non-right elements in Tangraphic Sea
- apparently have no phonetic or semantic value
- are based on the shape 乚
These 'tails' remind me of the element 乙 in made-in-Korea sinographs (國字 국자 kukcha 'national characters') for transcribing Korean syllables: e.g.,
乫
갈 kal < 加 가 ka 'add' + 乙 을 Ul 'second Heavenly Stem'
乬
걸 kOl < 巨 거 kO 'gigantic' + 乙 을 Ul 'second Heavenly Stem'
乧
둘 tul < 斗 두 tu 'dipper' + 乙 을 Ul 'second Heavenly Stem'
乶
볼 pol < 甫 보 po 'big' + 乙 을 Ul 'second Heavenly Stem'
used to write the name of 乶音島 볼음도 porUmdo 'Porum Island'
(ㄹ l > r between vowels)
乷
살 sal < 沙 사 sa 'sand' + 乙 을 Ul 'second Heavenly Stem'
All of the above could be described as
phonogram for CV + 乙 -l = sinograph for CVl
The element 乙 을 Ul for -l is not unlike the hangUl letter ㄹ -l in terms of position (bottom) and even shape: X atop 乙 = X atop ㄹ.
Given that
乼
contains 注 주 chu 'pour', one can easily guess its phonetic value. (Answer here.*)
This kukcha deviates a bit from the pattern:
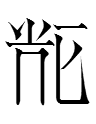
乭
돌 tol < 石 석 sOk 'stone' + 乙 을 Ul 'second Heavenly Stem'
(The native Korean word for 'stone' is 돌 tol.)
In this case, 乙 functions as a 'clarifier': it tells the reader that the 石 above it is to be read as tol rather than as sOk (its default reading). Here's a hypothetical English parallel: if 石 were normally pronounced petro, then rock could be written as 石k and stone could be written as 石n.
If tangraphic 'tails' are like Korean 乙, then they represented Tangut B codas. This would explain their position (always on the right) and their lack of semantic value. Therefore the structure of a tangraph like
TT5233 HORSE ryiry 1.74
may have represented a second reading: the Tangut B (or earlier Tangut A?) word for 'horse' ending in an unknown consonant (匕). The left-hand element means 'horse' and is structurally analogous to the 石 'stone' in Korean 乭 tol. The right-hand element 匕 could have represented an earlier Tangut A or Tibetan *-ng (cf. pre-Tangut A*rang and Old Tibetan rmang 'horse') or a Tangut B -t (cf. Uighut at 'horse').
One-element tangraphs without 'tails' such as
TT3344 PERSON dzywo 2.44
may have had Tangut B readings without codas.
If many tangraphs containing a certain 'tail' (匕) have semantic (near-)equivalents in another language (e.g., Uighur) which all end in the same consonant or similar consonants (-t and -d), then that other language is likely to be a relative of Tangut B, if not Tangut B itself.
*乼 is pronounced 줄 chul, a combination of 注 주 chu 'pour' and 乙 -l.
07.4.5.23:59: OH DEER (PART 5): 'E' FOR EMPTY?
I've spent most of the "Oh Deer" series investigating the tangraphic element that I've been calling 'longhorn'. It's on the left side of
TT0833 (first half of tree name) ?lhya 1.20
and seems to have at least three functions:
- phonetic symbol for lhya 1.20 (3 cases)
- phonetic symbol for tsar 1.80 (3 cases)
- semantic symbol for 'deer' (only 1 case)
See part 4 for details.
But what about the right side? What does 'E' (as I'll call it) represent?
Looking at reconstructions and meanings, the answer seems to be ... nothing. Here are some other E-graphs:
TT0121 HANDBELL Giẹe 2.59
the left and center elements do not form an independent tangraph
ditto for the center and right elements
so the structure is not [AB][C] or [A][BC] but [A][B][C]
TT1202 SAND bẹ 1.65
TT1687 稻 RICE rer 2.71
TT1925 WEST khyiy 1.36
TT2204 SALTY chhywi 1.10
TT2430 (a surname) jiə 1.28
TT2613 SEPARATE jyow 1.56
TT2816 MUTUAL twụ 1.58
TT2979 ISLAND tạ 1.63 (loan from Tangut period NW Chn 島 *taw 'island'?; Gong's reconstruction has no rhyme -aw and the landlocked Tangut would not need a native word)
TT5109 LONG jyo 1.51 (loan from pre-Tangut NW Chn 長 *jo 'long'?)
At one point I wondered if 'E' was a 'filler' added purely to avoid having a single-element tangraph. However, even though most tangraphs have two or more elements, there are a few simple tangraphs like
TT3344 PERSON dzywo 2.44
Why don't these tangraphs have 'fillers'? What makes PERSON different from DEER? Why doesn't PERSON look like
TT3484 PILE-UP dzyiw 1.45
which is an already existing tangraph? PERSON might be phonetic in TT3484, but the question remains: what is the right side doing?*
Is it an 'empty' disambiguator whose sole purpose is to tell the reader, 'don't confuse me with TT3344' (which looks like TT3484 without 'E')? 'E' might be a disambiguator in
TT0881 WOOD syi 1.11
that distinguishes it from its cryptophonetic**
TT0879 西 WEST shyạ 1.64
(the Tangut period NW Chn word for 'west' was something like *si)
The disambiguation hypothesis would predict that each X+E tangraph had a corresponding E-less X graph. But some 'E'-graphs have no 'E'-less counterparts. Their left sides can't stand alone. They need the support of a right-hand tail.
There are other tails which
- always appear on the right
- apparently have no graphic variants in other positions***
- apparently have no phonetic or semantic value
- are based on the shape 乚****
e.g., the right-hand elements of
TT3309 字 WRITTEN-CHARACTER dyi 2.10
TT1746 條 (somethng long and narrow?) piə̣y 2.65
TT1734 (syllable of a name) ze 2.7
these two have TT1730 ALSO/SMALL tsyï 1.30 on the left
TT0609 THAT zyi 1.11
TT4074 CAP pyụ 2.52
TT4366 FRUIT dew 2.38
TT0487 DIFFERENCE phyo 2.44
TT0529 CAUSE phyo 2.44
TT0507 象 ELEPHANT pyi 1.11
TT0512 畏怕 FEAR phyïï 1.32
these four and the next one have MOUTH on the left
TT0498 肉餡 MEAT-STUFFING khə 1.27
TT0099 SOUND Giẹ 1.59
TT3832 (syllable of names) jyị 2.60
TT3728 獨自 ALONE kywị̈y 1.45
TT3593 (a surname) lu 2.1
these last three have PERSON on the left
Some tails are extremely rare: e.g.., the right-hand side of FRUIT is in only three tangraphs and the right-hand side of DIFFERENCE is unique.
Other tails are extremely common: e.g., the right side of TT1746 appears in c. 540 tangraphs (~20 columns of Grinstead 1972 * ~27 graphs/column; almost one out of ten tangraphs).
Approximately 1,300 tangraphs (~16 pgs in Grinstead 1972 * 3 columns * ~27 graphs/column) - almost a fourth of the total of c. 6,000 - contain tails. Therefore figuring out the functions of tails would be a major step in unlocking the secrets of tangraphy.
Next: Tol tales.
*According
to the Tangraphic Sea, the right side of PILE-UP is
from the right side of the river name
TT5763 ngwe 2.7
which consists of
TT5649 WAIST/BIRD jyiw 1.49
twice plus 'E'. The left and center elements (WAIST/BIRD) do not comprise an independent tangraph. There is nothing about this tangraph which suggests water, and there is no way a reader could know that the 'E' of PILE-UP is from this river name as opposed to the c. 270 other 'E'-graphs.
**I use 'cryptophonetic' to refer to elements used for secondary, non-Tangut (i.e., Chinese) sound values. The phonetic nature of these elements is cryptic without Chinese knowledge. See Grinstead (1972: 65) for more examples of cryptophonetics. One could also call them sinophonetics, but I don't want to rule out the possibility of phonetic elements based on other languages.
Here's a case of what might be a cryptosemantic:
TT4007 LIGHTNING lhyạ 1.64
sounds like Written Tibetan lha 'god' (Lhasa is 'god-place') and might be semantic in
TT2018 GOD syi 2.10
representing a word whose Tibetan translation (lha) sounds like the Tangut word for lightning (lhyạ).
***07.4.6.00:59: Compare 'tails' with these right-hand elements which have left-hand versions (and known meanings): e.g.,
TT4254 MOIST/WET tsyi 2.10
which has the left and right-hand versions of WATER surrounding PERSON
Tangraphic Sea treats left- and right-hand versions as interchangeable for purposes of analysis: e.g.,
<
+
TT5361 WHIRLPOOL wa 1.17 <
left of TT5360 PIG wa 1.17 (phonetic) +
left of TT4282 WATER zyïïr 2.85
despite the different shape!
****06.4.6.1:46: But note that some 乚-elements do have known functions and are therefore not, strictly speaking, 'tails': e.g.,
TT3390 若 IF / 或 OR no 2.42
what does PERSON on the left have to do with IF or OR?
has six homophones all written with the same right-hand phonetic element:
TT1086 子 MASTER/CHILD no 2.42
TT2469 CLOTH-MEASURE no 2.42
TT4390 PEACE/安穩 SMOOTH-AND-STEADY no 2.42
TT4462 寶物 TREASURE no 2.42 (a distortion of 物?)
TT5665 (a kind of bird) no 2.42
TT5649 WAIST/BIRD jyiw 1.49 is on the left
TT5795 鼠 RAT no 2.42
TT5792 INSECT kyiy 1.36 is on the left (i.e., vermin?)
07.4.4.23:59: FROM A TO 澤 ZE?
One might have gotten the impression from " 澤散 Zesan = Azania?" that I was going to use the mid-3rd century CE transcription 澤散 (currently pronounced Zesan in standard Mandarin and identified by John E. Hill as 'Azania') to challenge existing reconstructions of earlier Chinese. In fact, I ended up defending the status quo: 澤 'marsh' had an initial stop (retroflex *D) and did not correspond to the A of Azania. Here's why I didn't reinterpret 澤散 as *azan:
1. No Chinese language (or language that has borrowed from Chinese) has a simple a (or 'a) for 澤 'marsh'. You can see its readings in 18 different Chinese languages and dialects here. Its readings in neighboring non-Chinese languages all reflect something like *tak:
Vietnamese trạch (borrowed c. the 10th century)
Korean 택 thEk < earlier*thayk (borrowed c. the 8th century)
Japanese taku (borrowed c. the 7th century), chaku < *tiyaku (borrowed c. the 5th century; found by Numoto [1995] in Myougishou)
All three readings were borrowed from different Chinese dialects in different periods. Nonetheless, none are a simple a. If 澤 'marsh' were *a in the third century, it would have to have 'grown' an initial and final stop by the fifth century.
2. 'Growth' is unusual. The only case of 'growth' I can think of is in Maru, which developed final -t and -k in open syllables (see Burling 1966 and Lyovin 1968; I also verified the secondary nature of those codas in an unpublished 1994 paper on comparative Lolo-Burmese). David Mortensen discusses Maru and five other cases of 'growth' in "The emergence of obstruents after high vowels: a maladaptive sound change". Of course a is not a high vowel, so no stops would be expected to 'grow' after it. And I do not know of a single case in which zero initial ever becomes a stop. (The addition of stop prefixes to zero-initial roots doesn't count.)
3. Other characters containing the phonetic element 睪 of 澤 'marsh' are not pronounced with zero initials or zero codas in any Chinese language (or language that has borrowed from Chinese). In Old Chinese, all these graphs' readings had a shared 'kernel' *lak: e.g.,
睪 *lak 'to spy'; also used to write 'marsh' (whose bare root was also *lak?)
圛 *lak 'turn round'
懌 *lak 'be pleased'
斁 *lak, *laks 'fed up with', *tlaks 'destroy' (= 殬 below)
繹 *lak 'draw out'
譯 *lak 'interpret'
cognate to 易 *lek 'change'; the Yijing (Book of Changes) was the 易經 *lek keng
醳 *lak 'bitter spirits'
驛 *lak 'post horses'
釋 *hlak 'unloose'
擇 *rlak or *dlak 'choose'
澤 *rlak or *dlak 'marsh' (> 3rd c. *Dæk)
07.4.5.00:35: Yet another possible Old Chinese reading would be *ntlak.
鐸 *lak 'kind of bell'
殬 *tlaks 'destroy' (= 斁 above)
蘀 *hlak 'withered and fallen leaves'
cognate to 落 *kəlak 'fall'
If 澤 'marsh' were reconstructed as *a, then the readings of all the other 睪-graphs would have to be reconstructed as near-homophones, despite all evidence to the contrary.
4. In Shijing, 澤 'marsh' and other words written with the same phonetic element 睪 rhyme with Old Chinese words ending in *-ak (Starostin 1989: 565). Since 3rd century CE *-a came from Old Chinese *-ay, a hypothetical 3rd century CE *a 'marsh' would have come from an Old Chinese *ay. A rhyme between *-ay and *-ak words would be very irregular. Those two rhyme classes never intersect in Shijing.
5. 散 3rd c. *san 'scatter'/'disperse' could not have had an initial *z-. No modern Chinese language (or language that has borrowed from Chinese) has an initial z- in 'scatter'. The Chinese data is here and the non-Chinese data is below:
Vietnamese tản < *sản 'dispersed', tán < *sán 'scattered' (borrowed c. the 10th century)
Korean 산 san (borrowed c. the 8th century)
Japanese san (borrowed c. the 7th century)
The Chinese languages which devoiced *z- to s- but reserve certain tones for earlier *voiced initial syllables (e.g., Cantonese) have tones implying an earlier *voiceless initial (i.e., *s-).
3rd century Chinese had no *zan, but it did have *dzan. If the transcriber intended to represent a foreign zan, a *dzan-graph might have been preferable to a *san-graph.
If 澤散 was *Dæk san'/h in the 3rd century CE, does that mean it could not have referred to Azania? Not necessarily. Perhaps it reflects a compound or phrase like 'Dak(-)Azania' or another name for Azania. A place can have multiple noncognate names. If one encountered the hypothetical transcription
比哥婆
Md Bigepo
referring to New York City, one shouldn't assume that those graphs represent a Mandarinization *Niu Yue Xi of the English words New York City. (Of course they represent a Mandarinzation of Big Apple.)
07.4.5.00:20: 紐約市 Niu Yue Shi happens to be an actual Mandarin term for 'New York City'. 紐約 Niu Yue (lit. 'button pact') is a transcription of New York, but 市 shi 'city' is a native word that has nothing to do with Eng city.
07.4.3.4:34: 澤散 ZESAN = AZANIA?
It's a shame that the Tangut didn't use their script to write more foreign names.
Although many Chinese names were written in tangraphy (e.g., these surnames in Kotaka's font), we don't know exactly how the Chinese originals were pronounced into the northwestern dialect known to the Tangut. (Of course having them is better than nothing.)
I don't know of any Tibetan names in tangraphy. Surely some must exist, but even if they did, we wouldn't be sure how they were originally .
Tangraphy was used to transcribe Sanskrit, whose phonology is extremely well understood. Unfortunately, the clues that tangraphic Sanskrit gives us are not sufficient for the reconstruction of Tangut. The evidence it provides is partly negative: e.g., if a Tangut rhyme is never used to transcribe Sanskrit, it probably represented a vowel (and coda?) without any counterpart in Sanskrit.
There is the Tangut name for the Khitan
TT0988 0952
chhyï 1.29 tã 1.24
but it's not clear whether it directly reflects a Khitan autonym or is a borrowing from Chinese 契丹 (and its affricate initial might have originated as a Tangut prefix-stop cluster; see here).
Kepping (2003: 192) found Temujin (i.e., Genghis Khan) in tangraphy. Unfortunately, this was not a phonetic transcription but was a partly hidden translation: METAL DO (i.e., BLACKSMITH) MARSH (standing for a homophone THUNDER?). (We'll see another 'marsh' shortly.)
A large number of words from known languages in tangraphy could be used to test the various existing reconstructions of Tangut - and provide the basis for further improvements in reconstruction.
In 1962, EG Pullebylank proposed a revolutionary reconstruction of Old Chinese supported by Chinese transcriptions of foreign words which could not be explained using the then-dominant reconstruction of Bernhard Karlgren. Although that reconstruction is now long outdated, Pulleyblank has continued to look for transcriptional evidence over the following decades.
I wonder how he would interpret the mid-third century CE transcription
澤散
identified by John E. Hill as 'Azania' (no, not South Africa) in the 魏略 Wei lüe.
One might expect the characters to represent a-zan, but only the second character 散 'scatter'/'disperse' comes close. In the third century it was *san' ('scatter') and *sanh ('disperse') and is still san in standard Mandarin today.
The problem is the first character 澤 'marsh'*. At no time was it ever pronounced as a. Its third century pronounciation was *Dæk with a retroflex stop onset and a velar stop coda. In Old Chinese - long before this transcription was ever coined - it was something like *rlak or *dlak. Did Azania have another name like 澤散*Dæk san'/h, or did the transcription refer to some other place with a name like Daksan?
*澤 is also used to write the ze in 毛澤東 Mao Zedong.
07.4.2.4:20: OH DEER (PART 4)
I admit that tangraphy frustrates me because of a lifetime of using sinography. Sinographs are not thousands of discrete 'pictures' but are combinations of elements whose positions often indicate their functions. To determine some correlations between positions and functions, let's look at characters containing 鹿 'deer' from the 遠東袖珍英漢漢英辭典 Far East Concise English-Chinese Chinese-English Dictionary (3rd ed. 1985):
1. 鹿 on top: a semantic element over a phonetic element:
麂 ji 'deerlike animal without antlers'
phonetic: 几 ji
麏 jun 'a kind of roe deer'
phonetic: 君 jun
麕 jun 'a kind of roe deer'
phonetic: 囷 jun
麐 lin (see 麟 lin in category 3 below)
phonetic: 吝 lin
麋 mi 'a kind of deer'
phonetic: 米 mi
麑 ni 'fawn'
phonetic: 兒 er < Middle Chinese *ñiə'
麅 pao 'a kind of roe deer'
phonetic: 包 bao
麃 pao 'a kind of roe deer'
灬 abbrev. of obscure phonetic 西+灭 piao now usu. written 票
abbrev. phonetics uncommon in sinography; more common in tangraphy?
麝 she 'musk deer'
phonetic: 射 she
麞 zhang 'deerlike animal'
phonetic: 章 zhang
麈 zhu 'a kind of deer'
phonetic: 主 zhu
1a. 鹿 on top: a semantic element over another semantic element:
麀 you 'doe'
匕 abbrev. for 牝 pin 'female'; not 七 qi 'seven'
2. 鹿 on the bottom: a phonetic element beneath a semantic element:
簏 lu 'bamboo trunk'
semantic: 竹 zhu 'bamboo'
麓 lu 'foot of a hill'
semantic: 林 lin 'woods' (surprisingly not 山 'mountain')
3. 鹿 on the left: a semantic element followed by a phonetic element:
麒 qi (first half of 麒麟 qilin [kirin; deerlike mythological animal])
phonetic: 其 qi
麟 lin (second half of 麒麟 qilin [kirin; deerlike mythological animal])
phonetic: 粦 lin
4. 鹿 on the right: a phonetic element preceded by a semantic element:
漉 lu 'remove sediment by dripping; wet, dripping'
semantic: 氵 'water'
轆 lu 'wheel; capstan'
semantic: 車 'wheeled vehicle'
5. 鹿 as a part of a phonetic element (here, 麃 pao/biao)
臕 biao 'fat'
semantic: 月, abbrev. of 肉 rou 'meat'
鑣 biao 'bit for a horse; ride on a horse; dartlike projectile'
semantic: 金 jin 'metal'
Exceptions:
6. Reuse of existing characters to write homophonous syllables:
麃 biao 'till the land'; 麃麃 biaobiao 'have a martial appearance' (see category 1 above)
麈 zhu 'to whisk; to dust; a duster' (see category 1 above)
麤 cu 'coarse; rough' (see category 7 below)
7. Semantic triplet:
麤 cu 'name of a place' (Behr 2006: 93)
do the three 鹿 'deer' indicate a place inhabited by many deer, or known for someone associated with deer?
8. Part of a larger drawing:
麗 li 'beautiful' (a deer with 丽 horns)
This chart sums up the five regular patterns:
| 1. top 鹿: semantic: 'deer' | ||
| 3. left 鹿: semantic: 'deer' | 5. 鹿: part of larger phonetic | 4. right 鹿: phonetic: lu |
| 2. bottom 鹿: phonetic: lu | ||
Using the five patterns, one can guess the function of 鹿 'deer' in graphs not in the Far East Concise English-Chinese Chinese-English Dictionary: e.g.,
1. top 鹿: semantic: 'deer'
麌 wu 'buck'
phonetic: 吳 wu
2. bottom 鹿: phonetic: lu
蔍 lu 'a kind of grass'
semantic: 艹 'grass'
3. left 鹿: semantic: 'deer'
麣 yan 'goat'
phonetic: 嚴 yan
4. right 鹿: phonetic: lu
摝 lu 'shake'
semantic: 扌 'hand'
and other lu-graphs with different semantic elements:
廘熝 螰塶蹗樚膔騼
5. 鹿: part of larger phonetic
don't know of any examples
Can one make similar predictions by studying the positions of tangraphic elements? The element that I've been calling 'longhorn' has only two positions:
- left:
TT2841-2845
TT2846-2849
- left (as part of an embedded tangraph):
TT0833, TT4540
In part 3, we saw that embedded tangraphs could either be phonetic (TT0833) or possibly semantic (TT4540).
The role of 'longhorn' in left-hand position is phonetic in most instances. However, unlike Chn 鹿 'deer', it has at least two phonetic values
lhya 1.20 in
TT2841 2843 2849
tsar 1.80 in
TT2845 2847 2848
There is no way to tell which reading is relevant just by looking at the tangraphs.
Sometimes the right-hand elements appear to be semantic but in other cases they seem to have no function: e.g., why is BASIC on the right of TT2847 SILK, and what is on the right of TT2843?
'Longhorn' may be semantic in
TT2846 FAWN ?xwụ 1.58
but its function in
TT2842 (syllable of a name) jywaa 2.18
TT2844 煩惱 / 煩わしい VEXING jiew 1.44
remains obscure, and it may really be a compound of smaller elements in TT2844 (and possibly the others as well).
One might get the impression that there is no correlation between form, function, and position in tangraphy. Certainly the correlation is weaker than in sinography, but it is there. Certain elements can only appear in one position or another. Some of these constraints are due to purely aesthetic reasons (e.g., it is awkward to squeeze a long horizontal element into a left or right-hand position or a tall vertical element into a top or bottom position). However, others may be linguistic (i.e., semantic or phonetic).
Next: Tails of the unexpected.
07.4.1.12:48: OH DEER (PART 3)
In part 2, I listed all tangraphs containing the element I call 'longhorn' on the left. I know of no tangraphs with that element in the center or on the right. I left out two tangraphs which contain 'longhorn'-left tangraphs:
TT0833 (first half of tree name*) ?lhya 1.20
TT4540 (first half of sheep name**) gywã 2.24
loan from Tangut period NW Chn 頑 ?*nggywã 'stubborn'
the disyllabic sheep name was glossed in the Pearl as 頑羊 'stubborn sheep'
I excluded these because I didn't think they would help me figure out the function of 'longhorn'. I assumed that they were top element + tangraph combinations, with the embedded tangraph having a single function of its own.
That is definitely the case with TT0833, which is a straightforward semantophonetic compound:
<
+
TT0833 (first half of tree name) ?lhya 1.20 <
semantic: head (PLANT) of TT0881 WOOD syi 1.11 +
phonetic: all of TT2843 DEER ?lhya 1.20
It is not clear what is going on with TT4540. Precious Rhymes of the Tangraphic Sea analyzed it as
<
+
TT4540 (first half of sheep name**) gywã 2.24 <
[top of] TT4537 DEER syu 1.7
[all of] TT2845 ? tsar 1.80
First, the function of ユ is unknown. Nishida (1966: 320) has no gloss for it. ユ is hardly sufficient to suggest DEER. Other DEER tangraphs do not contain it:
TT2250 ANTELOPE phyo 1.51
def. by Nishida (1966: 361) as 黃羊 MONGOLIAN-GAZELLE (the Chn is lit. 'yellow sheep')
the right-hand element is 'shorthorn', not 'longhorn'
TT2843 DEER ?lhya 1.20
TT2846 FAWN ?xwụ 1.58
TT2863 MUSK-DEER ngerw 2.78
TT4210 MILK?/DEER? zyu 2.2
its left side is WATER!
Other graphs that do contain ユ have nothing to do with DEER: e.g.,
TT4374 CONFUSED lhạ 2.57
TT4440 にくしみ HATRED (Nishida 1966: 321) / 厭 DETEST (Shi et al. 2000: 276) kio 2.40
TT4442 WINTER tsur 1.75
TT4443 EVIL khiõ 1.50
TT4528 NOT-TO-BE mə̣ 1.68
TT4530 TORMENT lyu 2.2
TT4532 HEAT-OF-SUN dzyi 1.11
TT4535 SEPARATE ka 2.14
TT4541 DITCH khow 1.54
TT4558 HURTchyu 1.7
TT4577 ERROR dzyi 1.11
TT4707 DAYLIGHT zyï 1.69
TT4782 BOTTOM wyi 2.9
TT4784 (the Chinese surname 李 Li) lyi 2.9
TT4787 SKIRT kyir 2.72
TT5649 WAIST jyiw 1.45 is beneath ユ
Second, the meaning of the embedded tangraph
TT2845 ? tsar 1.80
is uncertain. Unless the Tangut B hypothesis is correct - and I would like to avoid it if I can - it cannot be phonetic: tsar 1.80 is nothing like gywã 2.24. So it must be semantic. Nishida (1966) has two glosses for it,
山羊の一種 KIND-OF-GOAT (p. 321)
あぶ HORSEFLY (p. 424)
Only the first seems relevant to the choice of TT2845 as the bottom element of TT4540 (first half of sheep name).
Shi et al. (1983: 519) and Shi et al. (2000: 176) defined it more generically as 獸 BEAST. The Shi et al. (1983) translation of the Tangraphic Sea definition supports this definition:
This is a wild beast. This is a wild beast [?***]. This is a name for various kinds of wild beasts.
Li Fanwen 1986: 359 defined it as 野 WILDERNESS. In Homophones it seems to form a compound
TT2845 5350 tsar 1.80 khie 2.8 野犛牛 WILDERNESS YAK
with its clarifier. I translate 野 as a noun since 'wild yak' would be YAK WILD.
Grinstead 1972: 123 defined TT2845 as "syll. of name". This definition is not mutually exclusive with any of the others. Perhaps TT2845 represented one or more (parts of) words pronounced tsar 1.80 and also served as a phonetic symbol for the syllable tsar 1.80.
Next: Location and DEER-ivation.
TT0833 0936 ?lhya 1.20 nyaa 1.21
Like TT0833, TT0936 is also a semantophonetic compound:
<
TT0936 (second half of tree name) nyaa 1.20 <
semantic: head (PLANT) of TT0881 WOOD syi 1.11 +
phonetic: all of TT4479 BLACK nyaa 1.21
If all tangraphs were this straightforward, I wouldn't be blogging about tangraphy at all. This is how most sinography works. Only a small percentage of tangraphs have this structure. The others are supposed to be semantic compounds, but I still have my doubts ...
TT4540 4461 gywã 2.24 tyiy 2.33
glossed in the Pearl as 頑羊 'stubborn sheep'
If TT4540 is from the first half of 頑羊 'stubborn sheep', one might expect TT4461 to correspond to the second half. However, 羊 was probably something like *yõ in Tangut period northwestern Chinese. tyiy 2.33 is presumably a native Tangut word meaning 'sheep'.
***There are two Tangut words for 野獸 'wild beast' in the entry which Shi et al. translated identically:
TT3960 0625 wyu 1.2 nyiry 1.74
(with BEAST on the left of the first graph and on the right of the second; do not confuse with PERSON which has one less stroke)
TT5629 3962 we 2.7 gywi 2.10
(with BEAST on the left of the second graph but PERSON on the right of the first!)
I am not certain about the first tangraph. The Tangraphic Sea tangraph has a different bottom left component.